
Active Directory (AD) est un service d’annuaire développé par Microsoft.
Il est utilisé par la majorité des entreprises pour gérer les identités, les comptes utilisateurs, les machines, les politiques de sécurité ainsi que les droits d’accès aux ressources et services.
Cependant, sa position stratégique en fait une cible de choix pour les attaquants et les équipes Red Team. En effet, une compromission de l’Active Directory offre en général un accès quasi illimité au réseau. De fait, il est souvent soumis à de nombreuses attaques notamment en raison de la négligence des entreprises sur la mise en place de mesures de durcissement.
Notons par ailleurs que par défaut, après installation et déploiement, un AD offre très peu, voire aucune protection. À titre d’exemple, ce n’est que très récemment que Microsoft a décidé d’enforcer par défaut des mécanismes de sécurité comme le SMB Signing pour les machines avec Windows 11, ainsi que le LDAP Signing pour Windows Server 2025.
Dans ce contexte, il est essentiel de mettre en place une surveillance accrue, couplée à des règles de détections personnalisées afin d’identifier rapidement les comportements suspects pour pouvoir réagir avant qu’ils ne se transforment en incidents majeurs de sécurité.
Dans cet article, nous passerons en revue les menaces qui pèsent sur Active Directory ainsi que les techniques et tactiques Red Team. Nous détaillerons également les bonnes pratiques de monitoring AD afin de vous permettre de prioriser la collecte de logs, d’identifier les « signaux faibles » et de transformer ces signaux en règles de détection.
Guide pratique sur le monitoring d’Active Directory
- Comprendre les menaces sur l’AD et les tactiques Red Team
- Surveillance du trafic LDAP
- Créer des règles personnalisées pour ELK
- Conclusion
Comprendre les menaces sur l’AD et les tactiques Red Team
Les exercices Red Team et les attaques réelles contre Active Directory suivent presque toujours une même logique : reconnaissance, collecte d’identifiants, exploitation et persistance.
Comprendre ces étapes et les techniques associées est indispensable pour prioriser la collecte de données, définir des seuils d’alerte pertinents et transformer des « bruits » en signaux actionnables.
Principales techniques ciblant Active Directory
Les techniques ciblant l’AD vont de l’énumération passive à des actions plus intrusives sur les contrôleurs de domaine.
Parmi les plus courantes on trouve l’énumération massive des comptes et des relations (souvent automatisée via des outils de cartographie comme BloodHound), les attaques sur Kerberos comme le Kerberoasting ou l’abus d’AS-REP pour comptes sans pré-authentification, les tentatives de réplication ou d’exfiltration via les API de réplication (DRSUAPI/DCSync) et les manipulations d’ACL/GPO pour gagner la persistance.
À ces techniques s’ajoutent des méthodes de réutilisation d’identifiants (pass-the-hash, NTLM relay) et la production ou manipulation de tickets Kerberos (Silver/Golden Tickets) pour contourner l’authentification normale.
Enfin, les attaques modernes combinent souvent plusieurs étapes : une reconnaissance LDAP/SMB pour construire un graphe d’attaque, suivie d’un ciblage précis de comptes de service ou d’objets sensibles.
L’intérêt pour une équipe sécurité est de reconnaître les signatures comportementales de ces techniques. Ce ne sont pas des patterns isolés mais des chaînes d’événements (pics d’énumération, requêtes Kerberos anormales, accès répétés à des objets sensibles, modifications d’ACL) qui, prises ensemble, font sens.
Nous ne nous étendrons pas ici sur ces différentes techniques. Pour plus d’informations, nous vous invitons à consulter notre article complet sur la sécurité Active Directory. Dans ce dernier, nous passons en revue les failles et attaques courantes ; ainsi que les défauts de configuration pouvant compromettre la sécurité d’un AD.
Objectifs des attaquants et d’une Red Team
Les objectifs poursuivis sont généralement limités à quelques finalités : obtenir des privilèges élevés (compromission de comptes administrateurs ou d’un contrôleur de domaine), établir une persistance discrète, et préparer l’exfiltration ou la propagation latérale.
La cadence d’attaque varie : la reconnaissance est souvent « bruyante » (énumérations massives, scans LDAP/SMB sur une fenêtre courte) tandis que les phases de furtivité sont « silencieuses et lentes ». Il peut s’agir de tentatives sporadiques de vol de tickets, de changements d’ACL graduels, d’utilisation de comptes compromis à horaires décalés, etc.
Certaines techniques, comme le Kerberoasting, génèrent un pic observable de requêtes TGS pour un compte de service ; d’autres, comme DCSync, se manifestent par des actions spécifiques sur les contrôleurs de domaine et des accès aux interfaces de réplication qui ne sont pas courantes en exploitation normale.
Pour la détection, distinguer reconnaissance (volume et patterns) de post-exploitation (changements d’état sur les objets AD, création/modification de comptes, opérations de réplication) est crucial. La première alerte souvent sur une tentative d’identification de cibles, la seconde indique une progression vers la compromission réelle.
Quels indicateurs doivent guider le monitoring AD ?
Plutôt que d’énumérer des règles techniques isolées, il vaut mieux se concentrer sur les signaux corrélés et sur les données à collecter. Les éléments à surveiller incluent :
- La volumétrie et la cadence des requêtes LDAP par source et par cible (des pics ou des requêtes répétées avec des filtres larges sont typiques d’énumération) ;
- Les anomalies Kerberos : nombre inhabituel de demandes AS/TGS pour un même principal, demandes AS sans pré-auth pour des comptes configurés sans pré-auth, ou un nombre élevé de tickets demandés pour des comptes de service ;
- Les échecs d’authentification répétés sur comptes sensibles ou en dehors d’horaires d’activité habituels ;
- Des accès et opérations sur la réplication ou les interfaces DRS (actions inhabituelles effectuées depuis des comptes non-administrateurs vers des contrôleurs de domaine) ;
- Les modifications d’ACL ou d’objets privilégiés (création/suppression/modification de comptes, élévation de droits sur OUs ou GPO) ;
- L’émergence soudaine d’activité SMB / accès à partages sensibles en dehors des patterns connus ;
- Les patterns d’outillage : requêtes LDAP très régulières et larges, ou volumes d’énumération typiques d’outils de cartographie, et le recours inhabituel à des comptes de service pour des opérations d’énumération.
Concrètement, la valeur vient de la corrélation : un pic de requêtes LDAP suivi de demandes Kerberos anormales et d’une modification d’ACL sur une OU sensible doit déclencher une enquête prioritaire. De même, des authentifications réussies depuis des lieux/hosts inhabituels combinées à des accès à des partages d’administration sont des signaux à haute criticité.
Fort de ce cadrage tactique, la suite de l’article bascule vers la mise en œuvre opérationnelle : il s’agit maintenant de traduire les signaux décrits précédemment en données pertinentes, politiques d’audit et règles de détection.
Surveillance du trafic LDAP
Dans cette section, nous vous proposons d’accroître la sécurité de votre Active Directory avec la mise en place d’une surveillance accentuée du trafic LDAP.
Pour ce faire, nous nous appuierons sur les journaux d’événements (Event Logs). Voyons cela étape par étape.
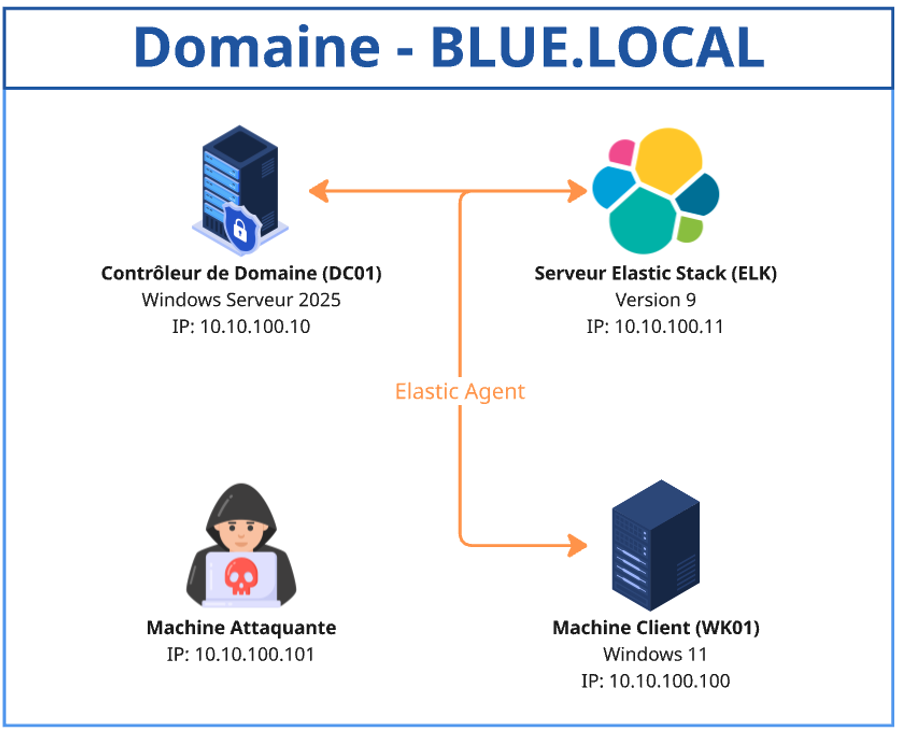
Présentation de notre environnement Active Directory
Le schéma ci-dessous représente l’environnement Active Directory utilisé pour cet article. Il est composé d’un contrôleur de domaine (DC01) en version Windows Serveur 2025, d’une machine client (WK01) en version Windows 11, d’un serveur Ubuntu hébergeant ELK en version 9, ainsi qu’une machine attaquante.
Politique d’audit des contrôleurs de domaine
La « Domain Controllers Audit Policy » joue un rôle essentiel dans la définition et le suivi des événements à auditer sur les contrôleurs de domaine. Elle garantit la traçabilité des actions sensibles et facilite la détection des activités suspectes.
Parmi ces actions figurent notamment les connexions utilisateurs, les modifications d’objets, les tentatives d’accès non autorisées, ainsi que d’autres événements critiques.
Chaque action génère un Event ID enregistré dans l’Event Viewer. Ces journaux peuvent ensuite être collectés et corrélés dans un SIEM (comme ELK), afin de détecter les incidents de sécurité et de centraliser la génération d’alertes.
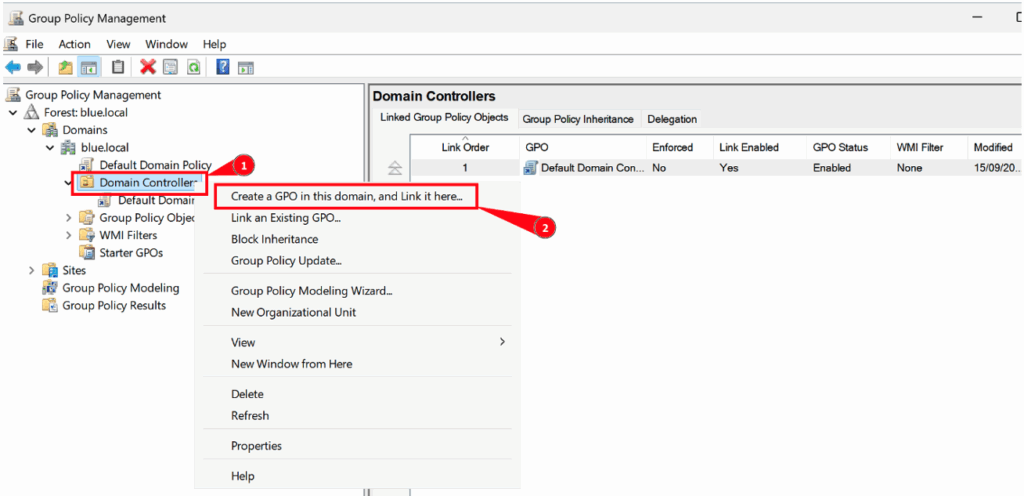
Création et configuration
Pour mettre en place cette politique de sécurité, il est recommandé de créer une nouvelle stratégie dédiée, appliquée spécifiquement aux contrôleurs de domaine.
Pour la configurer, il suffit d’accéder à l’éditeur de stratégie de groupe (GPO) et d’y définir les paramètres appropriés.
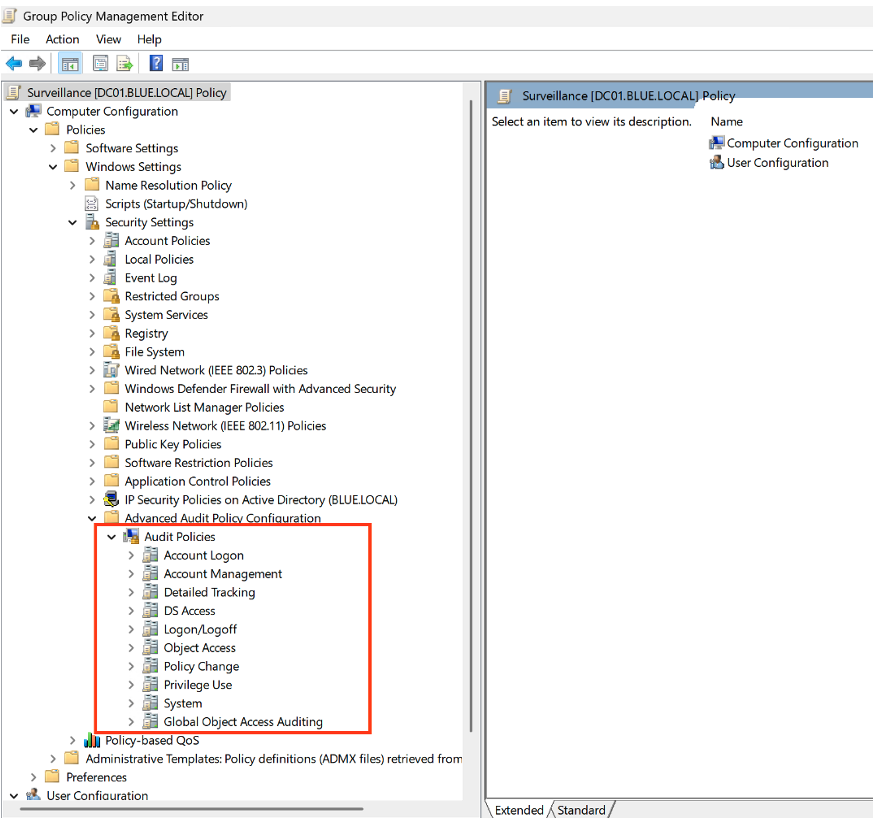
Une fois la nouvelle politique créée, vous pouvez l’éditer en accédant au chemin suivant :
Computer Configuration > Windows Settings > Security Settings > Advanced Audit Policy Configuration
Ce menu propose différentes catégories d’audit, chacune correspondant à un type d’activité spécifique. Par exemple :
- Account Logon : permet de surveiller les événements liés aux tentatives de connexion aux comptes.
- Account Management : permet de suivre les événements liés à la création, la modification ou la suppression de comptes.
La configuration des différentes catégories d’audit doit être adaptée aux besoins réels en matière de surveillance. Toutefois, gardez à l’esprit que plus la configuration est détaillée et complète, plus elle génère d’Event IDs dans l’Event Viewer, en fonction de la taille de l’environnement Active Directory.
En parallèle, cette granularité implique une charge supplémentaire pour le SIEM (par exemple ELK), qui devra disposer de ressources suffisantes pour traiter et corréler ces données.
Le tableau ci-dessous présente la configuration recommandée, en précisant les options « Success » et « Failure » à appliquer pour chaque catégorie.
| Politique d’Audit | Sous-catégorie | ID d’événements déclenchés |
|---|---|---|
| Account Logon | Audit Credential Validation | 4776 |
| Account Management | Audit Computer Account Management | 4741, 4743 |
| Account Management | Audit Distribution Group Management | 4753, 4763 |
| Account Management | Audit Security Group Management | 4728, 4729, 4730, 4732, 4733, 4756, 4757, 4758 |
| Account Management | Audit User Account Management | 4726 |
| DS Access | Audit Directory Service Changes | 5136 |
| DS Access | Audit Directory Service Access | 4662 + (nécessite une configuration supplémentaire) |
| System | Audit Security System Extension | 7045 |
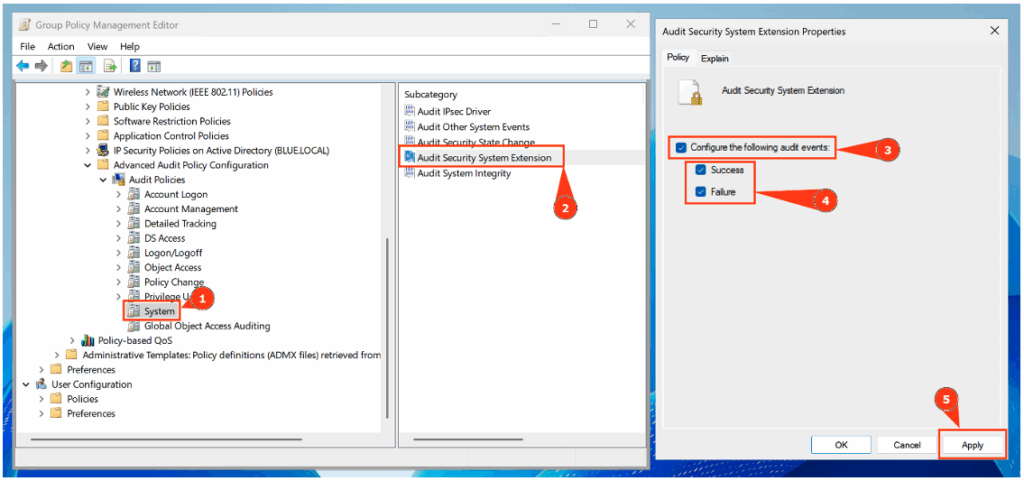
Pour illustrer, prenons la sous-catégorie Audit Credential Validation (sous Account Logon).
- Double-cliquez sur Audit Credential Validation.
- Sélectionnez Configure the following audit events.
- Activez les options pour les événements Success et Failure.
Visualisation des événements
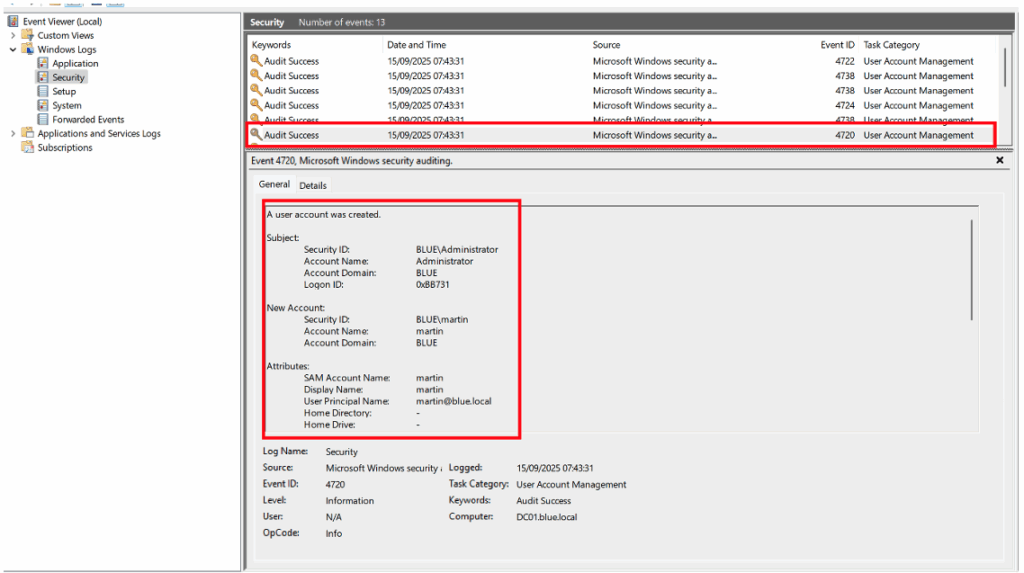
Les Event IDs générés peuvent ensuite être consultés dans :
Event Viewer > Windows Logs > Security.
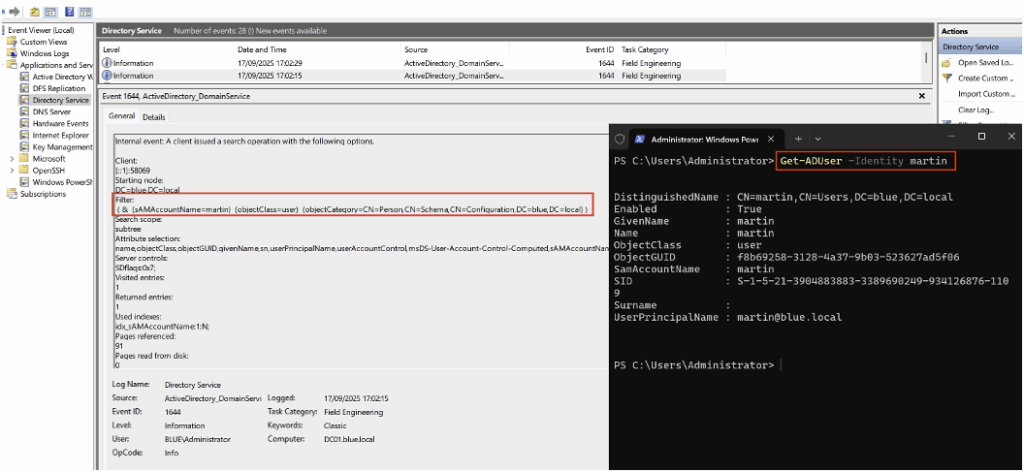
Par exemple, l’illustration ci-dessous montre l’apparition de l’Event ID 4720, correspondant à la création d’un utilisateur nommé « martin » par l’administrateur du domaine dans l’environnement Active Directory.
Activer la surveillance du trafic NTLM
En complément de la politique d’audit appliquée aux contrôleurs de domaine, il est essentiel de surveiller le trafic NTLM afin de détecter toute utilisation suspecte de ce protocole d’authentification.
De tels événements peuvent révéler :
- des tentatives d’attaque par relais NTLM,
- ou des mauvaises configurations autorisant l’usage de NTLM dans des environnements où Kerberos devrait être privilégié.
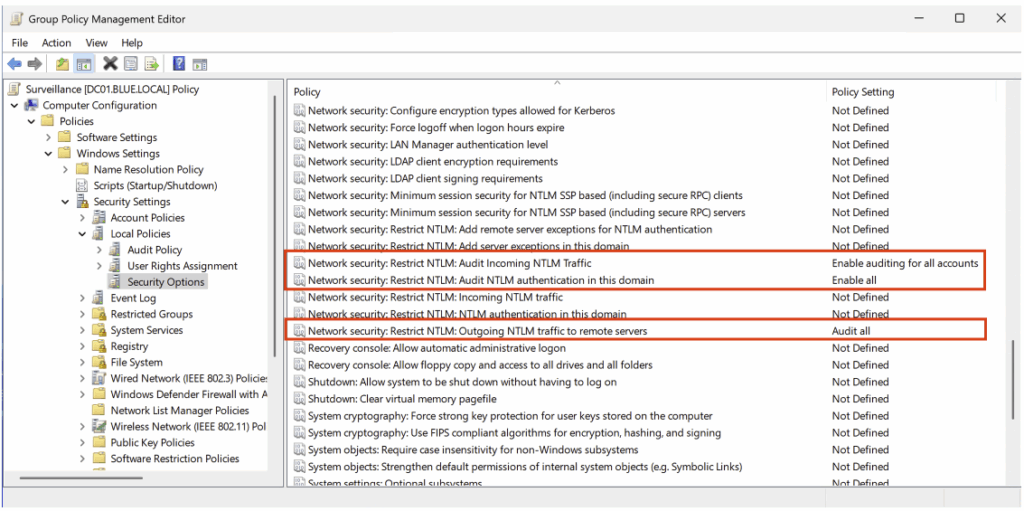
Pour activer cette surveillance, ouvrez la politique créée précédemment, puis accédez au chemin suivant :
Computer Configuration > Policies > Windows Settings > Security Settings > Local Policies > Security Options
La configuration recommandée est présentée ci-dessous.
| Paramètres de la politique de sécurité | Valeur |
|---|---|
| Network security : Restrict NTLM : Outgoing NTLM traffic to remote servers | Audit all |
| Network security : Restrict NTLM : Audit NTLM authentication in this domain | Enable all |
| Network security : Restrict NTLM : Audit Incoming NTLM traffic | Enable auditing for all accounts |
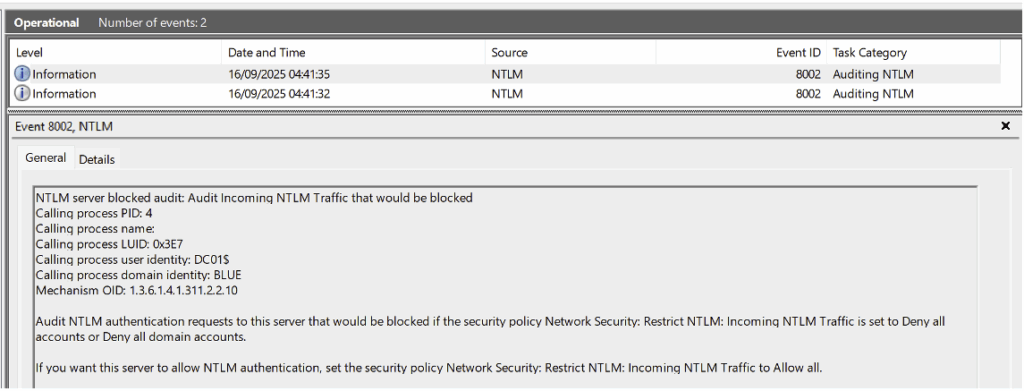
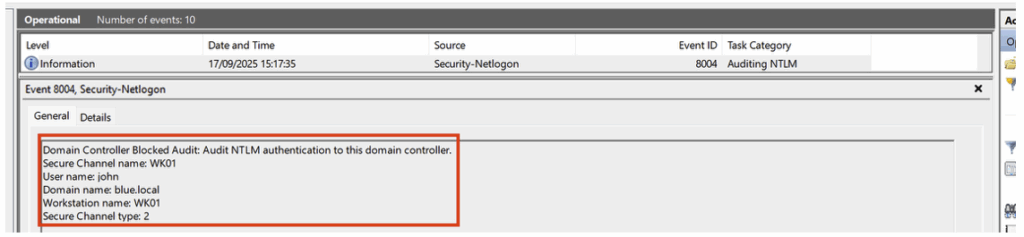
Après avoir appliqué cette configuration, les événements générés peuvent être consultés dans : Event Viewer > Applications and Services Logs > Microsoft > Windows > NTLM.
Il est toutefois important de noter que les événements issus de l’audit NTLM ne fournissent ni l’identité de l’utilisateur, ni l’origine de la machine ayant utilisé le protocole LDAP.
Pour obtenir ces informations, il est nécessaire de corréler avec les Event IDs 4776 de la catégorie Credential Validation.
En revanche, pour les autres protocoles tels que SMB, l’audit NTLM génère bien un événement qui inclut cette fois les détails complets de l’authentification.
Audit de sécurité des objets du domaine
La fonctionnalité System Access Control Lists (SACLs) permet de définir, pour chaque objet de l’Active Directory (utilisateur, groupe, ordinateur, unité d’organisation, etc.), les types d’accès qui doivent être journalisés.
Selon la configuration mise en place, les événements générés avec l’ID 4662 fournissent des informations précieuses, telles que :
- l’identité de l’utilisateur ayant accédé (ou tenté d’accéder) à l’objet,
- le type d’opération effectuée (lecture, modification, suppression, etc.),
- ainsi que le résultat de l’opération (succès ou échec).
Une fois collectés dans un SIEM (par exemple ELK), ces événements peuvent être corrélés avec des règles de détection pour identifier rapidement les activités suspectes.
Mettre en place une SACLs au niveau du domaine
La configuration d’une SACL requiert au préalable l’activation de la stratégie Directory Service Access Audit, ce qui a été effectué lors de l’étape précédente avec la politique d’audit DS Access.
Dans l’exemple présenté, nous appliquons l’audit de sécurité des objets à l’ensemble du domaine. Toutefois, dans un contexte réel, et comme illustré plus loin dans l’article avec la création de règles personnalisées pour ELK, il est déconseillé de l’appliquer globalement. Il est préférable de cibler des objets spécifiques tels qu’un utilisateur, un groupe ou une unité d’organisation (OU).
Pour mettre en œuvre cette configuration, utilisez l’outil d’administration Active Directory Users and Computers, puis accédez aux propriétés du domaine.
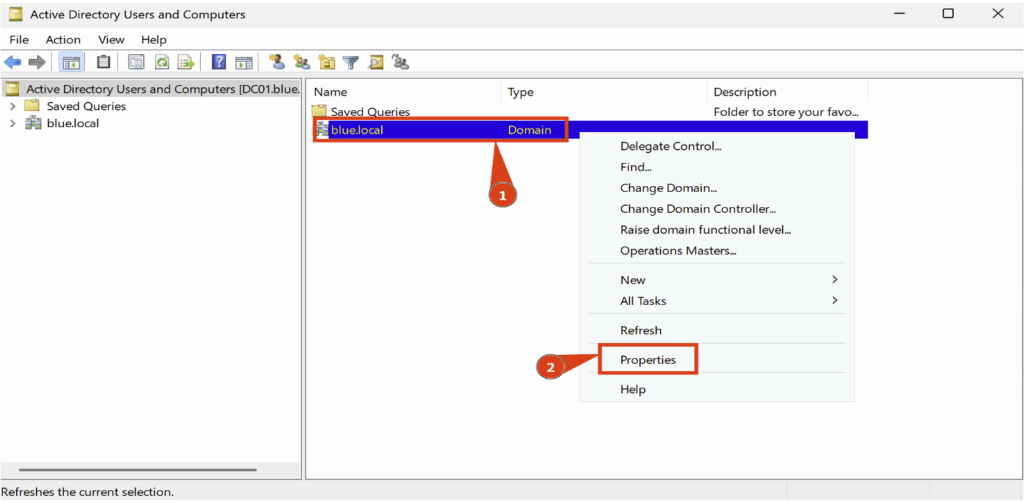
Dans l’onglet Propriétés du domaine, ouvrez la section Security, puis cliquez sur Advanced.
Un nouvel onglet s’affiche alors, donnant accès aux options de sécurité avancées.
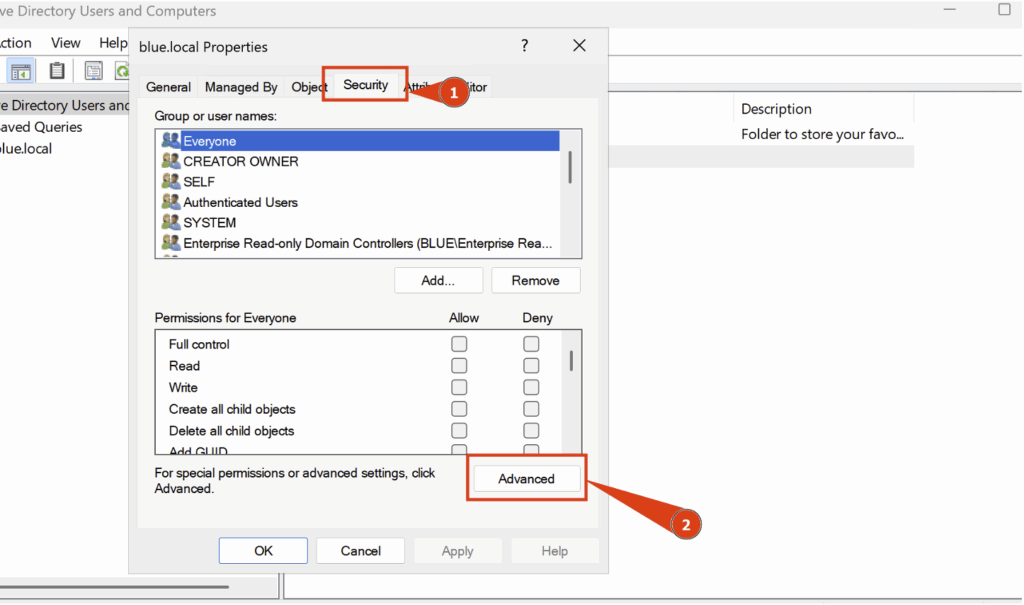
Ici, rendez-vous dans Auditing puis cliquer sur Add :
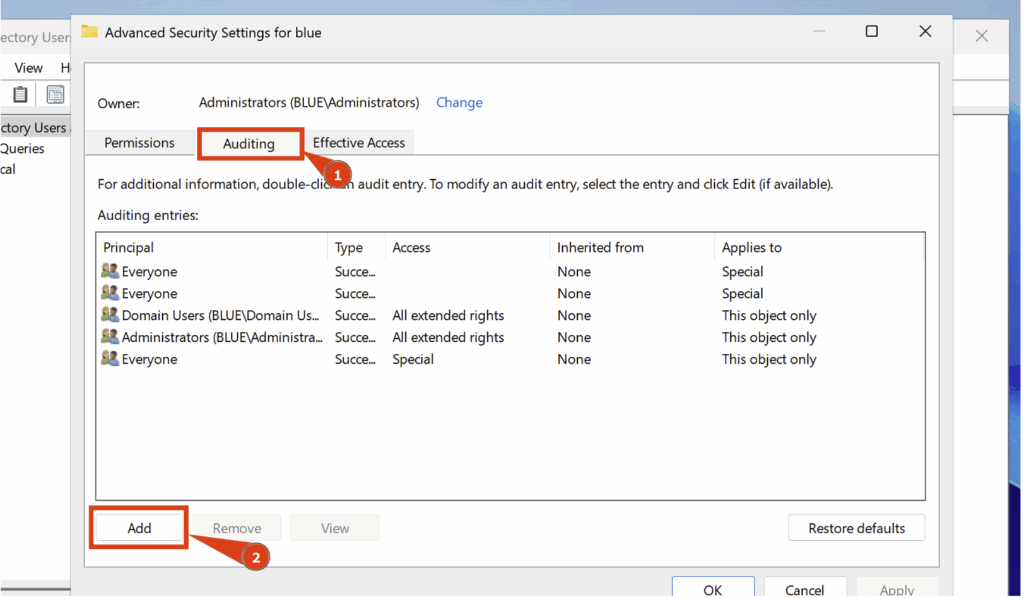
Configurez ensuite les paramètres suivants :
- Principal > Everyone
- Type > All
- Applies to > This object and all descendant objects
Vous devez également cocher les deux cases suivantes : Read all properties et Read permissions :
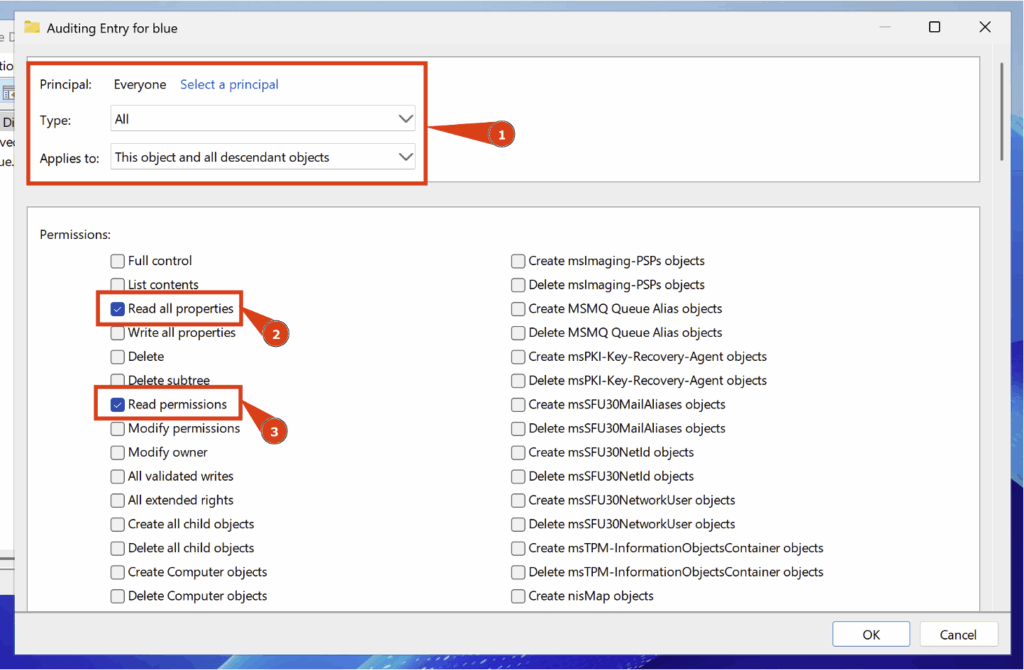
Avec cette configuration, un Security Event ID 4662 sera généré lorsqu’un membre du groupe Everyone tentera de lire une propriété d’un objet de l’Active Directory.
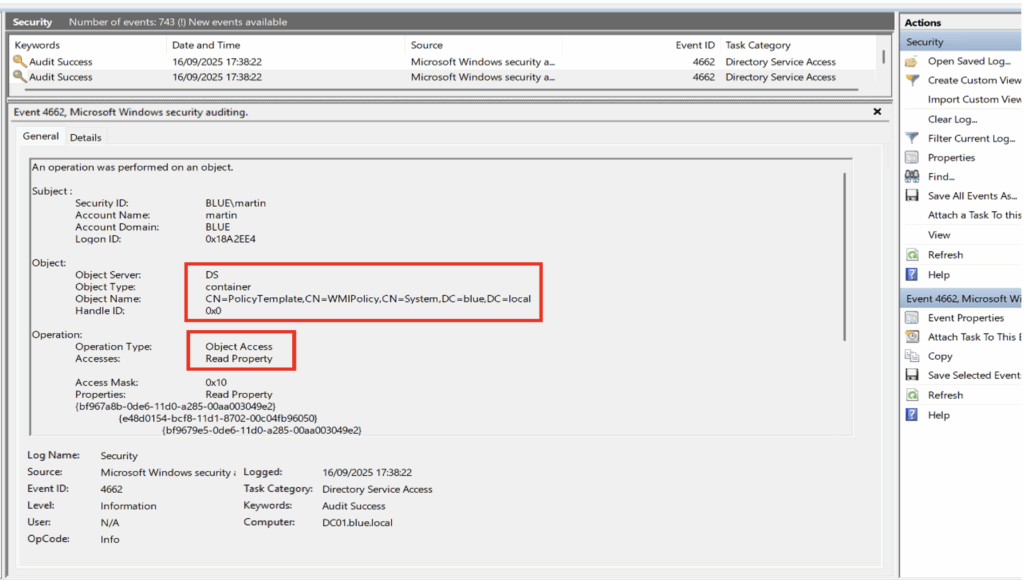
Dans l’exemple ci-dessous, l’utilisateur « martin » a effectué une extraction de l’Active Directory à l’aide de l’outil SharpHound. Cette action a entraîné la génération de nombreux événements 4662, chacun correspondant à un accès en lecture sur un objet spécifique.
Voici un exemple illustrant ce comportement avec un objet de type container :
Implémenter une surveillance LDAP étendue
Par défaut, les requêtes LDAP ne sont pas journalisées sur un contrôleur de domaine.
Pour activer cette fonctionnalité, il est nécessaire de modifier la clé de registre suivante et de lui attribuer la valeur 5 :
HKEY_LOCAL_MACHINE\SYSTEM\CurrentControlSet\Services\NTDS\Diagnostics\Field Engineering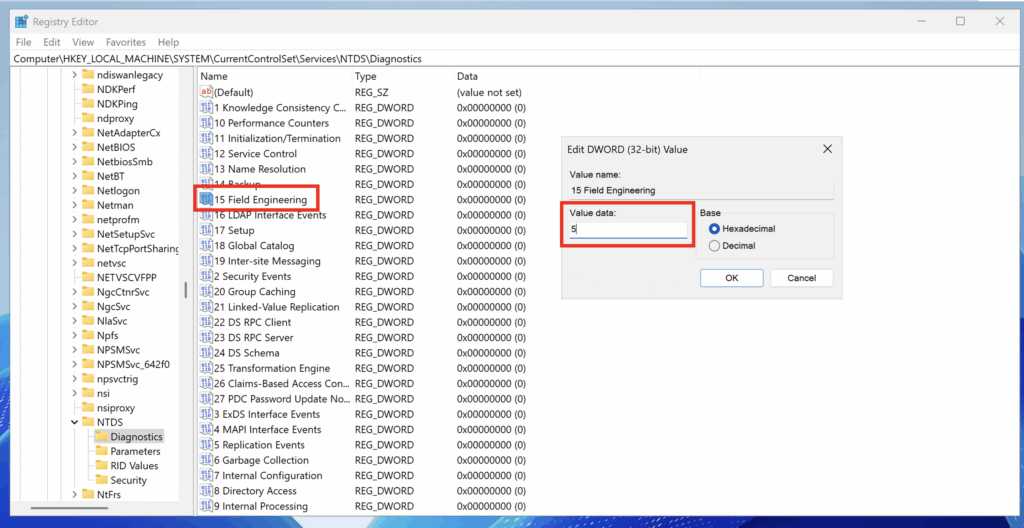
Après avoir activé la journalisation, seules certaines requêtes LDAP sont enregistrées par défaut. En effet, cette fonctionnalité a été conçue à l’origine pour identifier les requêtes considérées comme coûteuses ou inefficaces.
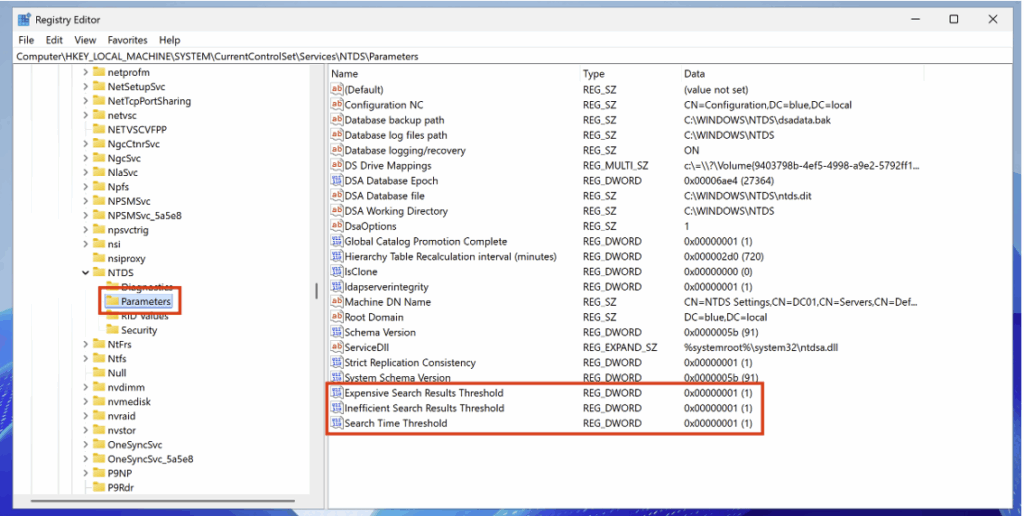
Les seuils appliqués par défaut sont les suivants :
- Expensive Search Results Threshold (10 000) : une requête LDAP est jugée coûteuse si elle parcourt plus de 10 000 entrées.
- Inefficient Search Results Threshold (1 000) : une requête LDAP est considérée comme inefficace si elle parcourt plus de 1 000 entrées et que les résultats représentent moins de 10 % des entrées visitées.
- Search Time Threshold (30s) : une requête LDAP est classée comme coûteuse ou inefficace si son exécution dure plus de 30 secondes.
Ces seuils peuvent être ajustés en créant des clés de registre spécifiques et en attribuant des valeurs inférieures afin d’obtenir une surveillance plus fine.
Pour une journalisation complète de toutes les requêtes LDAP, il convient de définir la valeur de chaque seuil à 1.
| Chemin d’accès au registre | Type | Valeur |
|---|---|---|
HKEY_LOCAL_MACHINE\SYSTEM\CurrentControlSet\Services\NTDS\Parameters\Expensive Search Results Threshold | DWORD | 1 |
HKEY_LOCAL_MACHINE\SYSTEM\CurrentControlSet\Services\NTDS\Parameters\Inefficient Search Results Threshold | DWORD | 1 |
HKEY_LOCAL_MACHINE\SYSTEM\CurrentControlSet\Services\NTDS\Parameters\Search Time Threshold | DWORD | 1 |
Après avoir ajouté les clés de registre avec la valeur définie et redémarré le contrôleur de domaine, les événements associés apparaissent désormais avec l’ID 1644 dans l’Event Viewer.
Ils sont accessibles via le chemin suivant : Applications and Services Logs > Directory Service.
Politique d’audit des machines du domaine (Client-Side Monitoring)
La politique d’audit des contrôleurs de domaine reste la source principale pour les événements liés au protocole LDAP.
Toutefois, il est pertinent d’ajouter une surveillance côté postes (machines membres) pour capturer les requêtes LDAP émises par ces machines : ces deux approches forment le Client-Side Monitoring et améliorent la visibilité du SOC en complément de la journalisation côté contrôleur.
Contrairement au contrôleur de domaine (où l’on active la journalisation LDAP étendue via la clé de registre Field Engineering pour obtenir les Event ID 1644), les machines membres utilisent un canal d’événements distinct basé sur ETW : Microsoft-Windows-LDAP-Client.
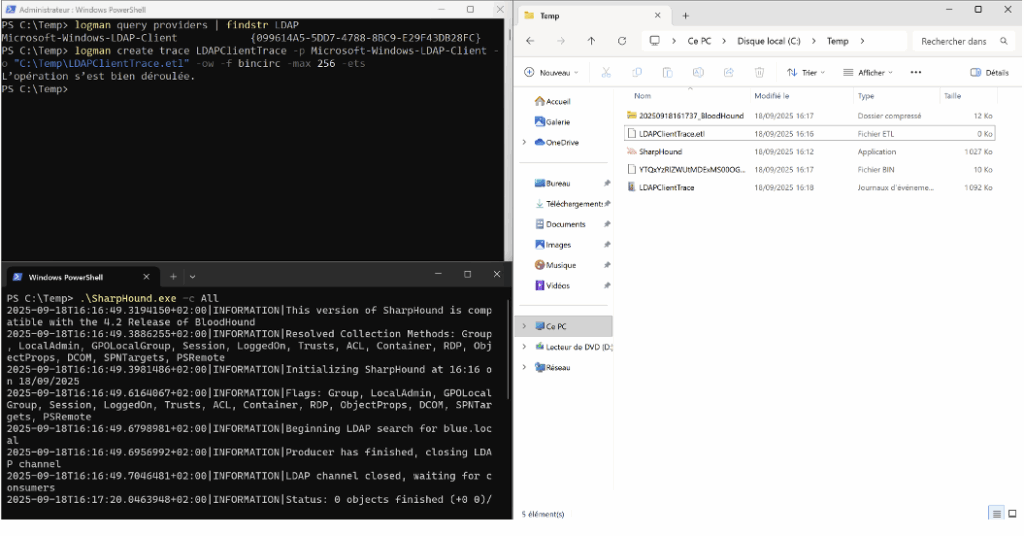
Sur la machine cliente, lancez la commande PowerShell suivante pour démarrer une trace ETW et enregistrer les événements LDAP du client :
Logman create trace LDAPClientTrace -p Microsoft-Windows-LDAP-Client -o C:\Temp\LDAPClientTrace.elt -ow -f bincirc -max 256 -etsCette commande crée une trace nommée LDAPClientTrace et écrit le fichier C:\Temp\LDAPClientTrace.elt.
Pour simuler une activité malveillante depuis la machine cliente (par ex. ingestion du domaine), vous pouvez exécuter SharpHound.exe sur cette machine. Les requêtes LDAP générées par l’outil seront alors consignées dans la trace ETW et permettront d’observer le comportement client-side.
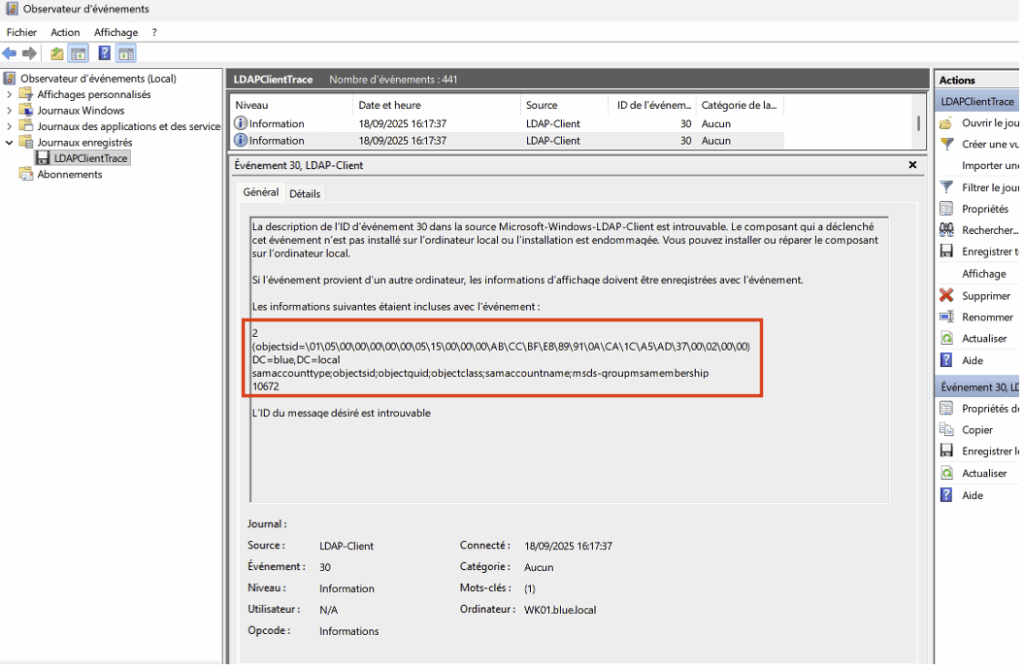
Vous pouvez importer le fichier LDAPClientTrace.etl dans Event Viewer pour consulter les événements clients LDAP, notamment les Event ID 30.
Attention : contrairement à la journalisation étendue côté contrôleur de domaine, il n’existe pas de seuils configurables (taille, durée, nombre de requêtes) pour cette trace côté client.
Par ailleurs, toute utilisation de la bibliothèque wldap32.dll (appelée par des applications légitimes ou malveillantes) peut générer un Event ID 30, ce qui impose de corréler ces événements pour distinguer le trafic normal des activités suspectes.
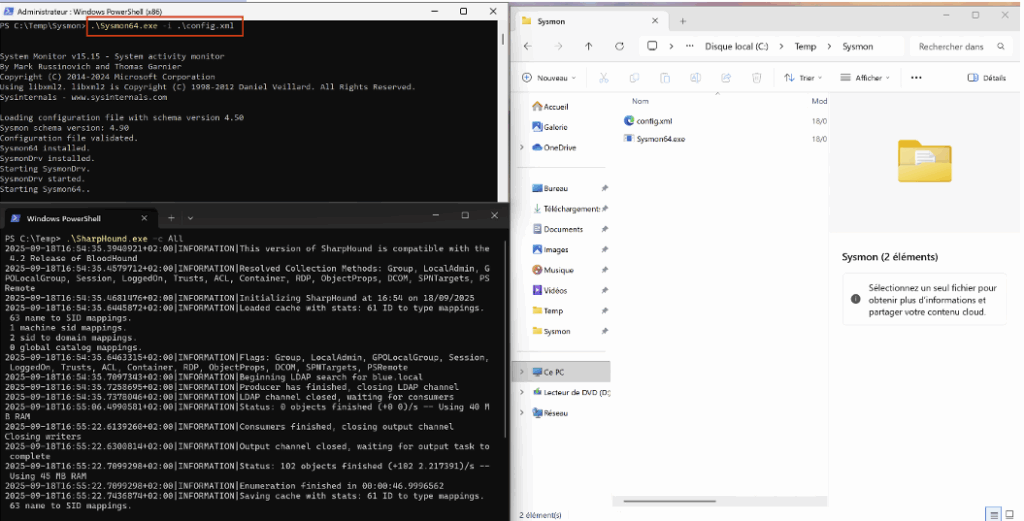
Pour compléter la visibilité client-side, vous pouvez déployer Sysmon avec une configuration minimale afin de journaliser toutes les connexions sortantes vers LDAP (389) et LDAPS (636). Cela permet d’identifier précisément quel processus sur la machine établit la connexion vers les contrôleurs de domaine.
Exemple de fichier config.xml :
<Sysmon schemaversion="4.50">
<EventFiltering>
<NetworkConnect onmatch="include">
<!-- Ports LDAP et LDAPS -->
<DestinationPort condition="is">389</DestinationPort>
<DestinationPort condition="is">636</DestinationPort>
</NetworkConnect>
</EventFiltering>
</Sysmon>On peut l’activer directement via PowerShell :
.\Sysmon64.exe -i .\config.xmlCette commande installe Sysmon avec la configuration fournie et commencera à loguer les événements NetworkConnect correspondant aux ports LDAP/LDAPS.
Pour tester ou simuler un scénario malveillant depuis la machine cliente, relancez SharpHound : les connexions LDAP/LDAPS générées devraient apparaître dans les événements Sysmon, avec le processus à l’origine de la connexion.
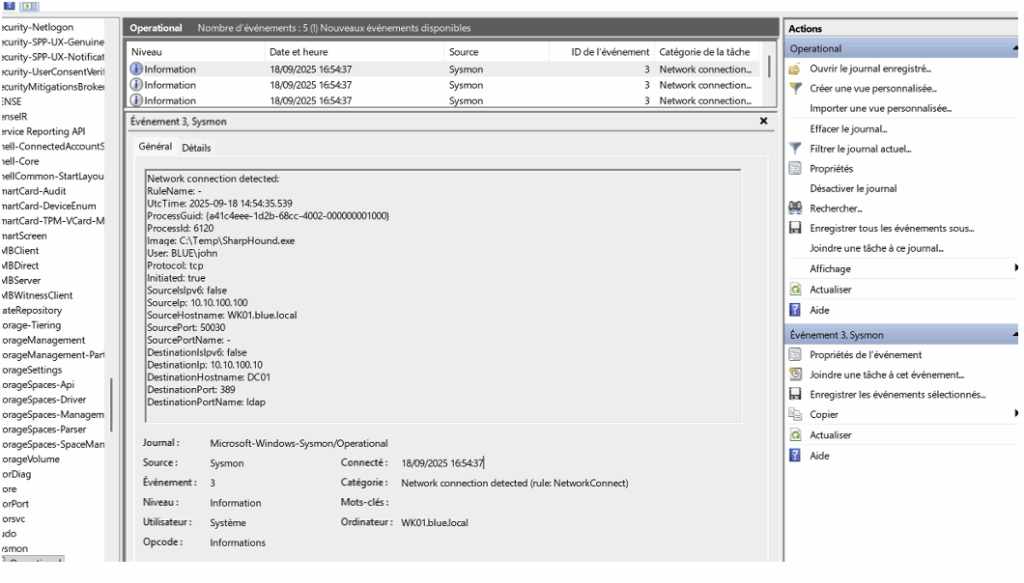
Après l’installation, les connexions journalisées par Sysmon apparaissent sous l’Event ID 3 dans l’Event Viewer. Vous pouvez les consulter ici : Applications and Services Logs > Microsoft > Windows > Sysmon.
Ces événements fournissent des informations utiles (processus source, PID, adresse IP distante, port, etc.) pour identifier quel processus a initié une connexion LDAP/LDAPS depuis la machine cliente.
Surveillance par le réseau
La surveillance réseau complète utilement la visibilité obtenue côté contrôleurs de domaine et côté postes clients en capturant les flux réseau eux-mêmes, plutôt que de se limiter aux journaux Windows.
Elle permet d’observer les requêtes échangées entre postes et serveurs indépendamment du système de journalisation, d’identifier des comportements anormaux (par exemple un poste qui effectue des interrogations massives de l’annuaire) et d’enrichir les investigations en corrélant les flux réseau avec les logs Windows.
Des outils comme Zeek, Suricata/Snort ou des solutions NDR peuvent être utilisés pour cette surveillance, mais il faut garder à l’esprit plusieurs limites opérationnelles : la plupart des communications LDAP utilisées par des outils offensifs s’effectuent via LDAP over TLS ou LDAPS, ce qui rend le contenu des requêtes invisible sans inspection TLS (avec les implications techniques et juridiques que cela suppose).
Par ailleurs, monitorer l’ensemble du trafic LDAP dans un grand domaine peut s’avérer coûteux en ressources ; il est donc essentiel de positionner la sonde de manière stratégique (par exemple en amont des contrôleurs de domaine ou des serveurs sensibles) pour maximiser la valeur des données collectées.
En somme, la surveillance réseau offre une vue indépendante et centralisée qui complète fortement les audits Windows, mais son utilité dépendra toujours des spécificités de votre environnement et de vos capacités d’infrastructure.
Créer des règles personnalisées pour ELK
Elastic Stack (avec Elastic Defend / Detection rules) fournit par défaut un jeu de règles génériques, mais celles-ci sont rarement suffisantes pour une surveillance approfondie de LDAP et d’Active Directory.
À l’état initial, seules deux règles orientées LDAP sont incluses :
Si ces règles constituent un point de départ utile, il est pertinent de renforcer la détection en ajoutant des règles personnalisées.
Nous proposons d’en créer quatre spécifiquement dédiées à l’activité malveillante dans Active Directory.
La conception de ces règles s’appuiera sur les éléments présentés précédemment concernant la configuration et la mise en place de la surveillance LDAP.
Honeypot ASREProasting
L’AS-REP Roasting est une technique offensive qui cible les comptes pour lesquels l’option « Do not require Kerberos pre-authentication » est activée. L’attaquant demande un AS-REP pour ce compte et récupère un bloc chiffré (l’AS-REP) qu’il peut ensuite attaquer hors-ligne par brute force pour tenter de retrouver le mot de passe.
Pour préparer notre honeypot, nous commençons par créer un compte dédié nommé svc_backup.
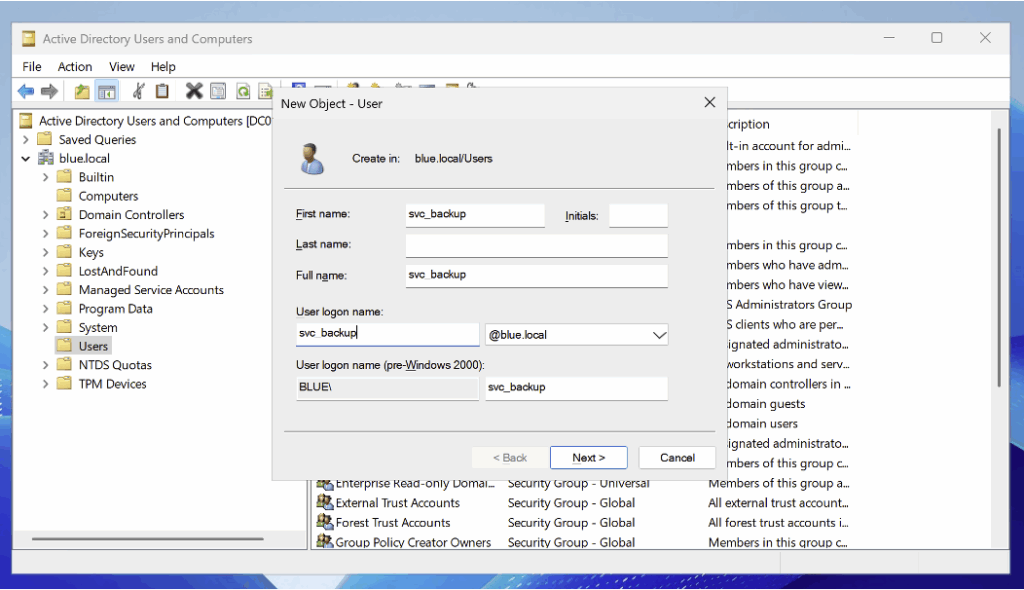
Après avoir ajouté l’utilisateur, ouvrez ses propriétés dans Active Directory Users and Computers et cochez l’option « Do not require Kerberos preauthentication ».
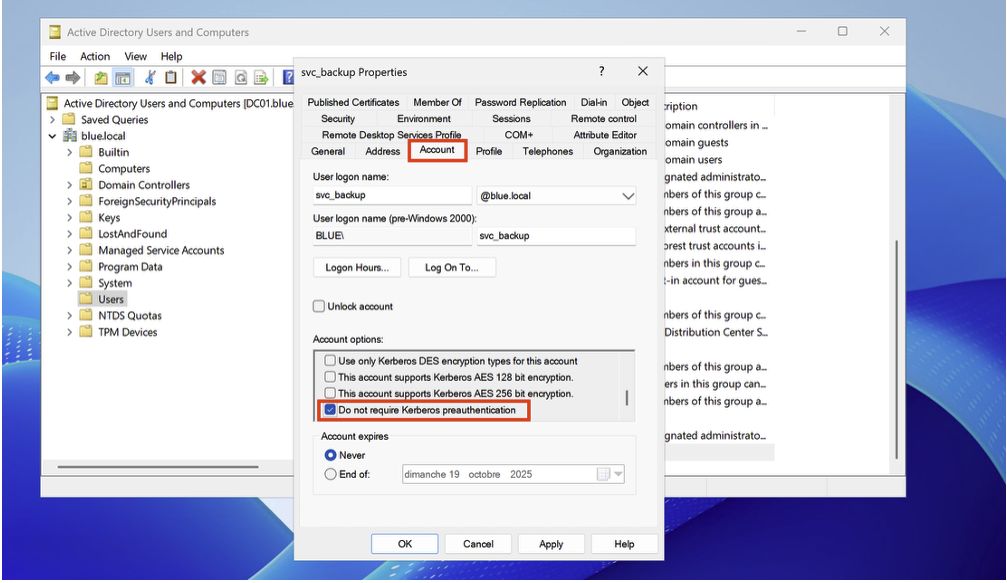
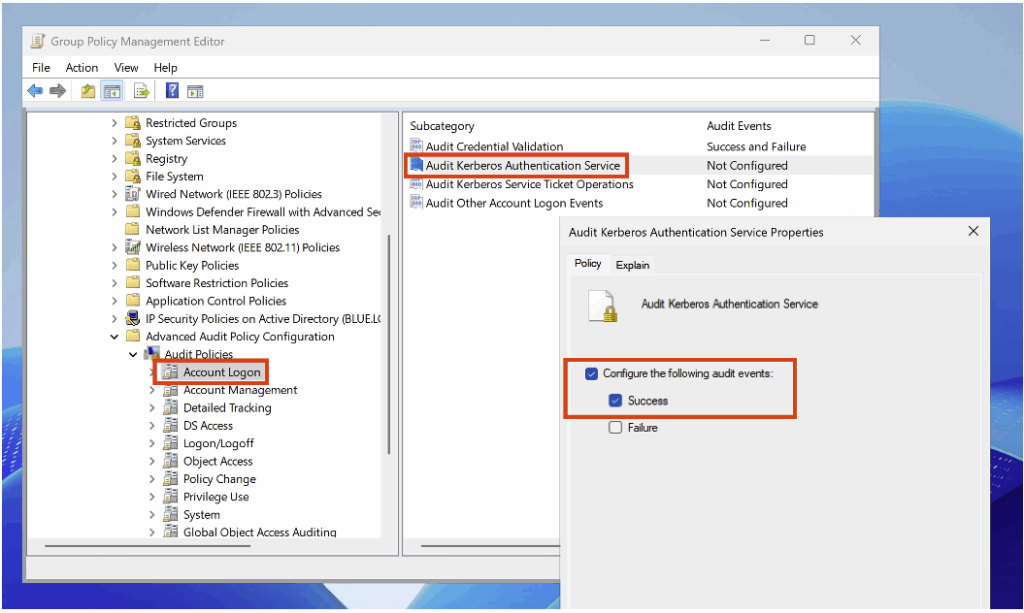
Pour détecter les demandes de ticket Kerberos, activez dans la politique d’audit la sous-catégorie Audit Kerberos Authentication Service (sous Account Logon) en mode Success.
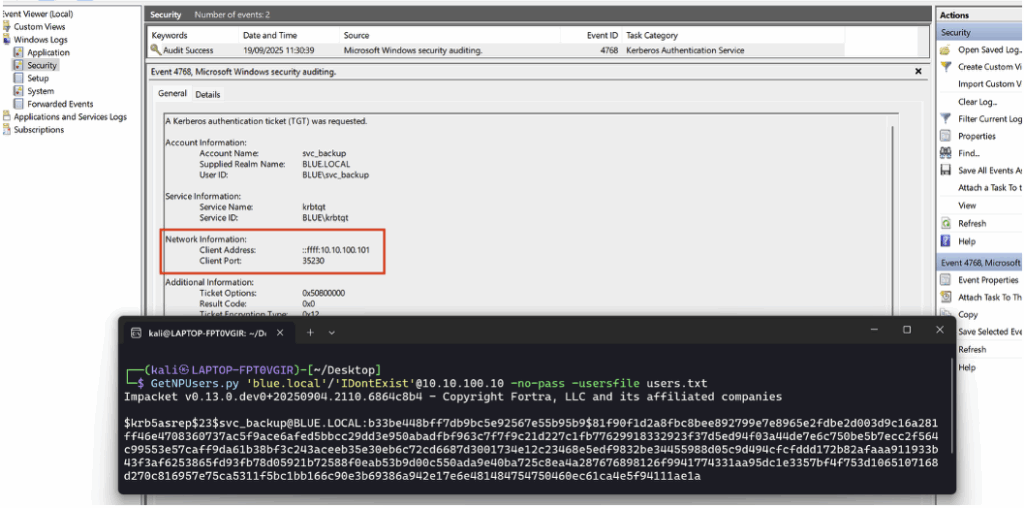
Après configuration, lorsqu’une machine attaquante sollicite le ticket du honeypot AS-REP Roasting, un Event ID 4768 est généré.
Parmi les éléments pertinents pour la détection, on retrouve notamment l’adresse IP de la machine ayant effectué la requête :
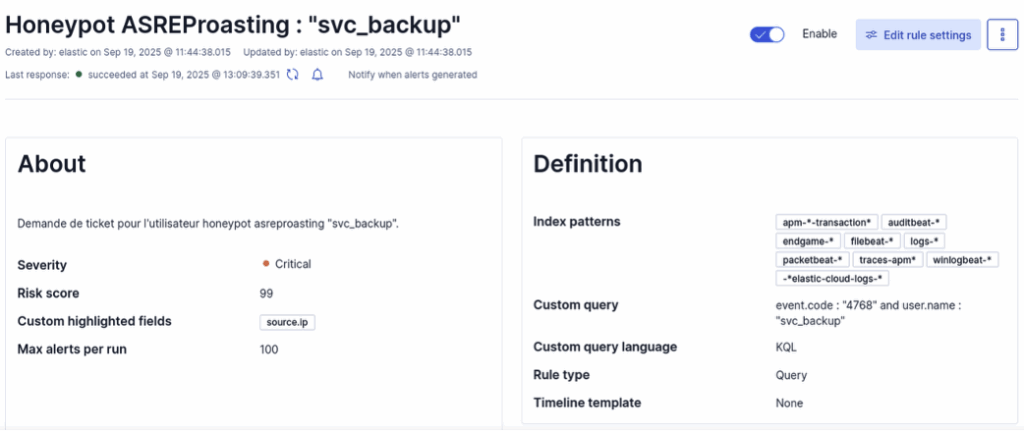
Pour détecter simplement la requête liée au honeypot dans ELK, une règle KQL très concise suffit.
La requête suivante recherche l’Event ID associé au ticket et le nom du compte cible :
event.code : "4768" and user.name : "svc_backup"Voici à quoi ressemble la règle de détection dans le SIEM :
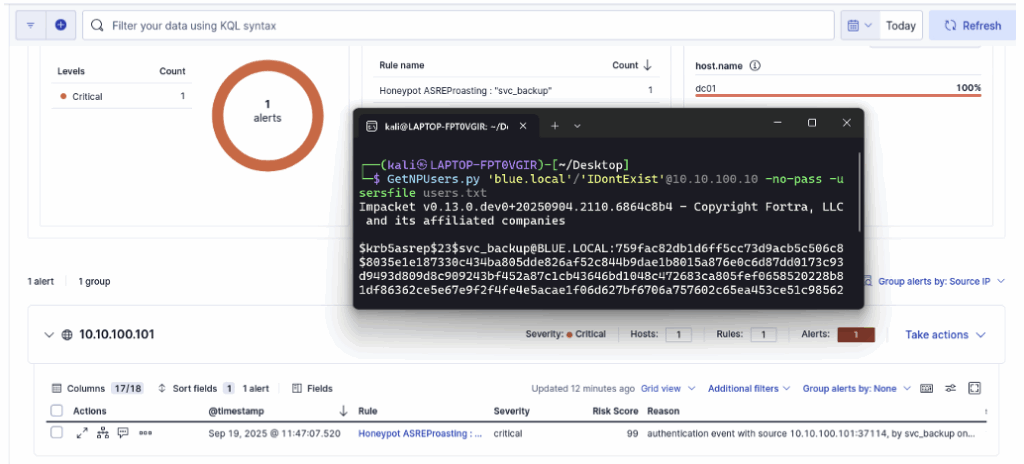
Après avoir ajouté la règle à ELK, relancez l’attaque depuis la machine offensive ; dans le tableau de bord, vous constaterez que la règle s’est bien déclenchée.
La création de la règle et la configuration du compte dans Active Directory restent ici volontairement minimalistes. En environnement réel, il convient d’augmenter la crédibilité du compte, en lui ajoutant un historique d’activité, des attributs cohérents et une utilisation simulée, pour rendre le leurre plus crédible et maximiser l’efficacité du honeypot.
Honeypot Kerberoasting
Le Kerberoasting est une technique offensive où un attaquant demande un ticket de service (TGS) pour un compte disposant de l’attribut servicePrincipalName.
Ce ticket contient une portion chiffrée dérivée du mot de passe du compte de service ; l’attaquant récupère ce bloc chiffré et peut ensuite l’attaquer hors ligne par force brute pour tenter de retrouver le mot de passe.
Pour notre honeypot, nous commençons par créer un compte dédié nommé svc_veeam.
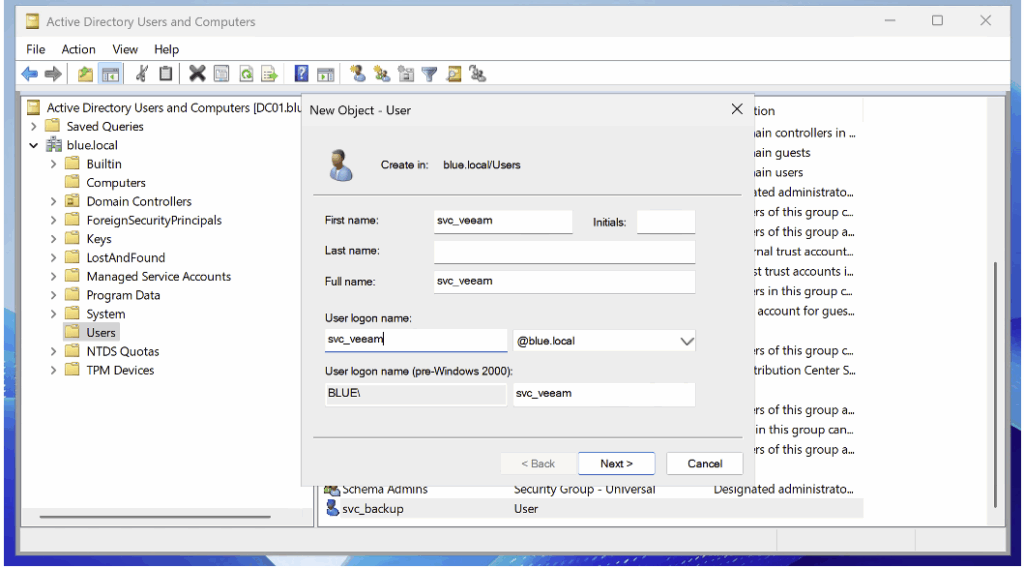
Après avoir ajouté l’utilisateur, ouvrez ses propriétés dans Active Directory Users and Computers et affectez-lui un servicePrincipalName (SPN).
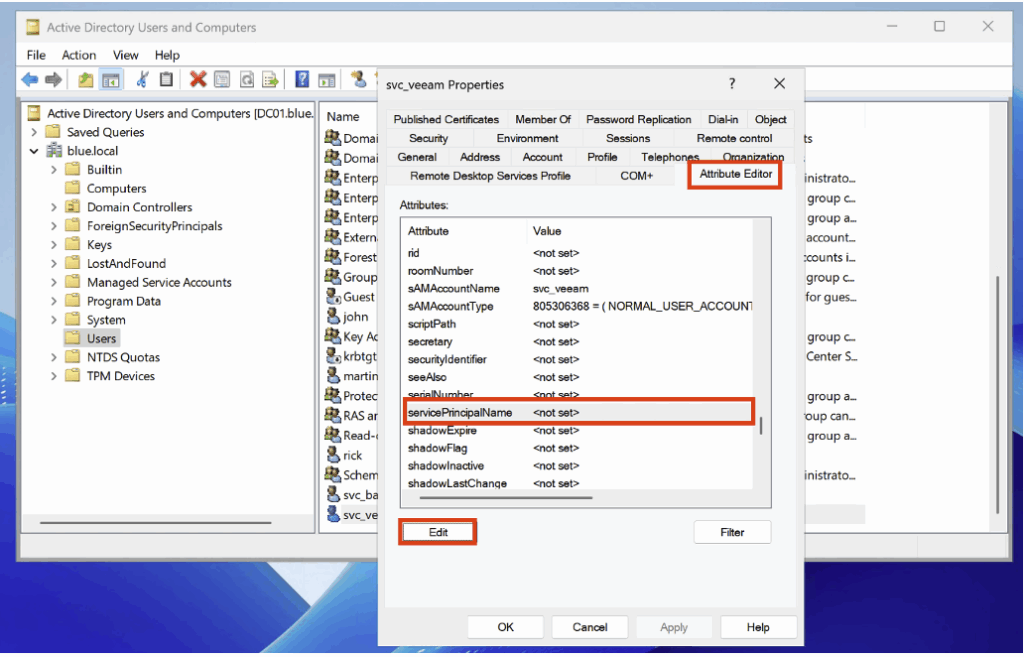
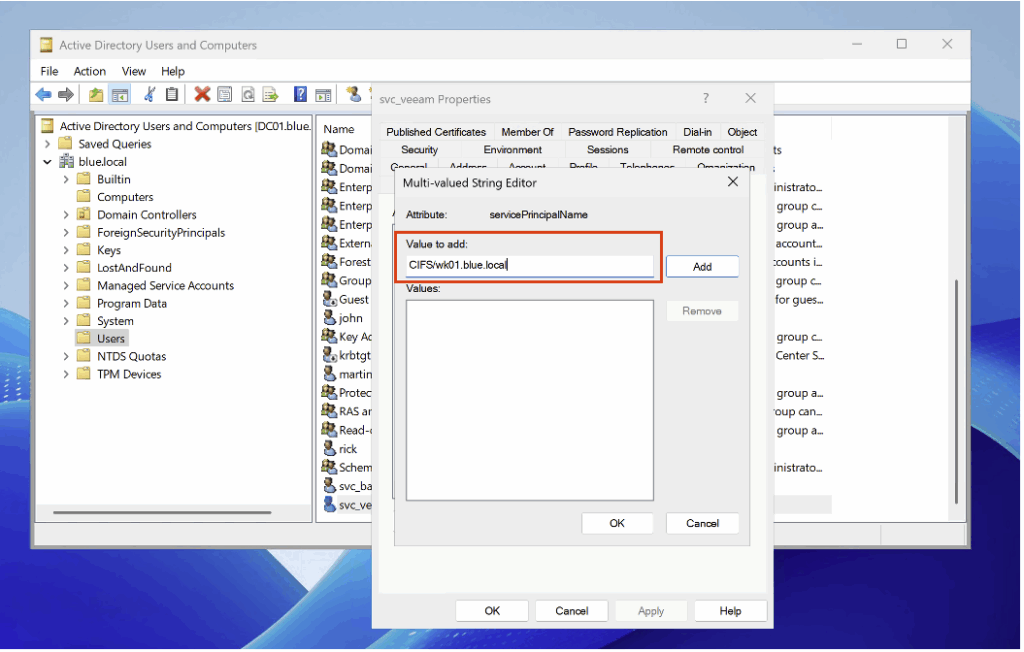
Pour détecter les demandes de ticket liées à un servicePrincipalName, activez dans la politique d’audit la sous-catégorie Audit Kerberos Service Ticket Operations (sous Account Logon) en mode Success.
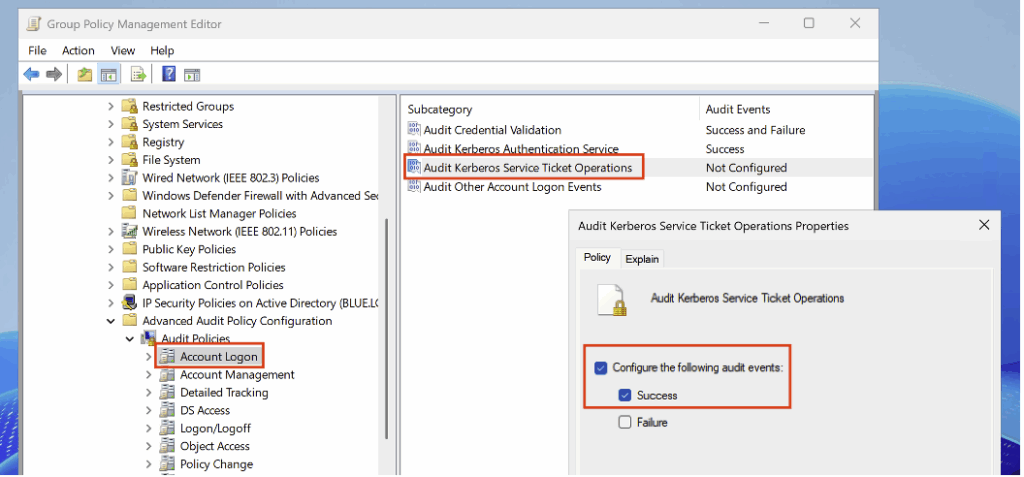
Après configuration, lorsqu’une machine attaquante sollicite le ticket de service du honeypot Kerberoasting, un Event ID 4769 est généré.
Parmi les informations utiles pour la détection figurent le compte ciblé et l’adresse IP de la machine ayant effectué la demande.
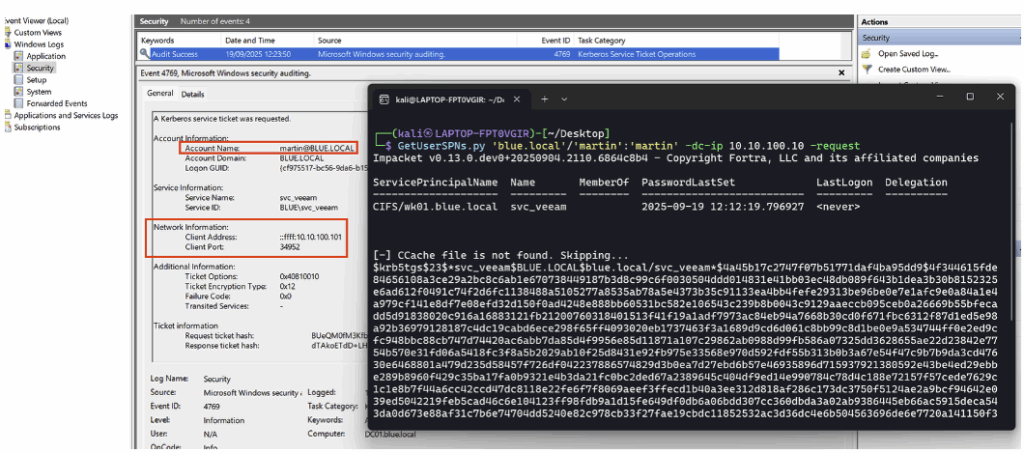
Pour détecter de manière simple une requête Kerberoasting ciblant le honeypot dans ELK, une règle KQL concise suffit. La requête ci-dessous recherche l’Event ID correspondant à la demande de ticket de service ainsi que le nom du service visé :
event.code : "4769" and service.name : "svc_veeam"Voici à quoi ressemble la règle de détection dans le SIEM :
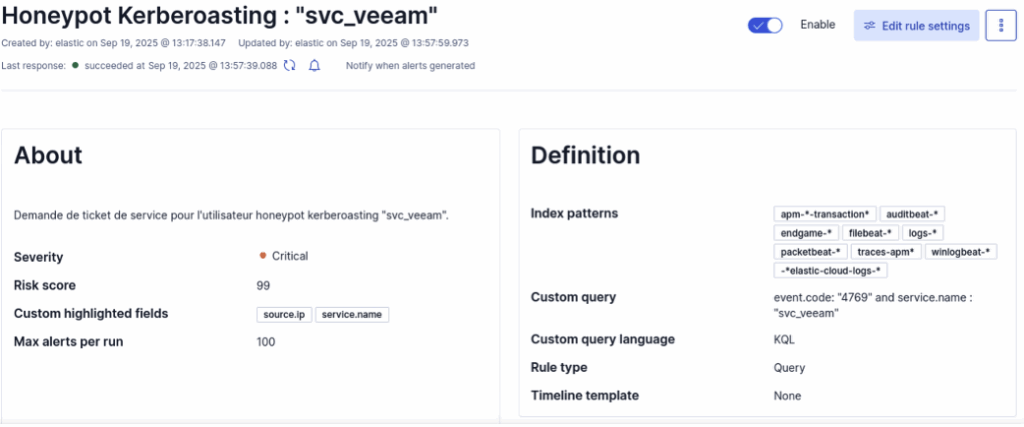
Après avoir ajouté la règle dans ELK, relancez l’attaque ; le tableau de bord affichera que la règle s’est bien déclenchée.
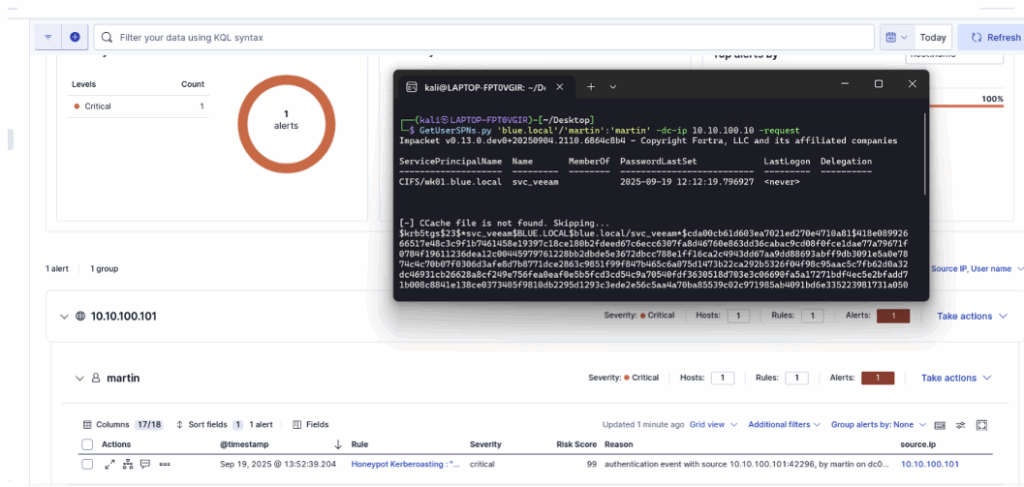
La configuration de la règle de détection et la mise en place du compte dans Active Directory présentées ici restent volontairement minimalistes.
En production, il est nécessaire d’accroître la crédibilité du compte, en lui attribuant un historique d’activité, des attributs cohérents et une utilisation simulée, pour rendre le leurre plus réaliste et maximiser l’efficacité du honeypot.
Détection BloodHound via SMB (IPC$ & named pipes)
BloodHound est un outil offensif conçu pour cartographier les relations et les permissions au sein d’un Active Directory.
Dans notre cas, avec la surveillance LDAP étendue activée, nous avons utilisé SharpHound.exe, l’outil d’ingestion associé à BloodHound.
Pour la règle de détection présentée ici (et la suivante), nous nous intéressons cependant à l’outil externe bloodhound-python. Lorsqu’il est configuré en mode All (scénario fréquent), l’outil se connecte au partage IPC$ pour établir des sessions DCE/RPC et interroge via ce canal plusieurs named pipes exposés par le système, notamment srvsvc, samr et lsarpc.
Pour créer la règle de détection, il faut d’abord repérer les Event IDs correspondant aux accès au partage et aux accès aux named pipes ; cela nécessite d’activer dans la politique d’audit la sous-catégorie Audit File Share en Success, située dans la catégorie Object Access.
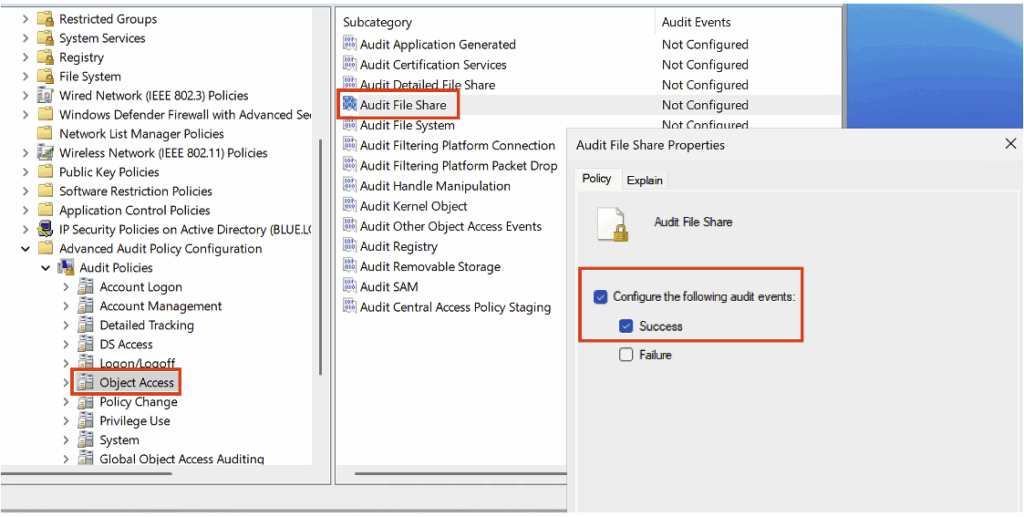
Activez également la sous-catégorie Audit File Detailed File Share (dans la catégorie Object Access) en mode Success dans votre politique d’audit.
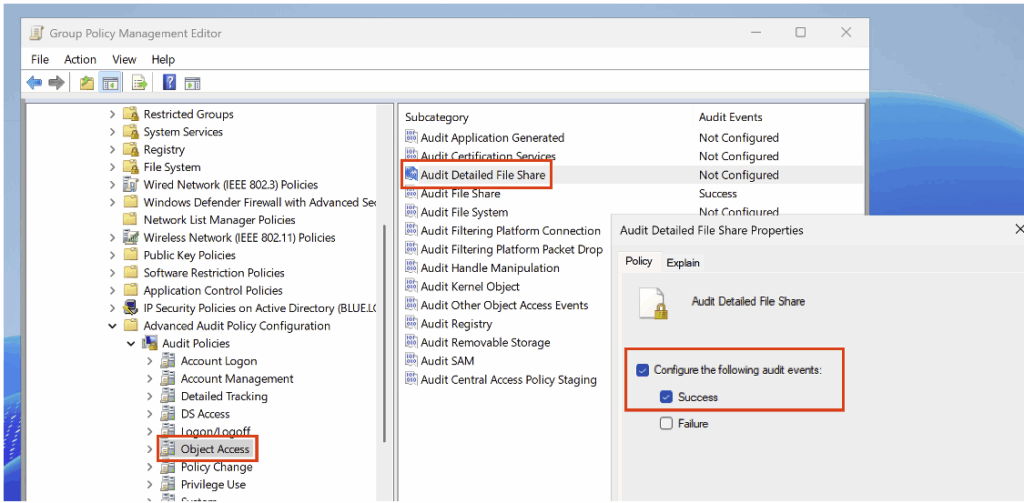
Après activation de la politique d’audit, exécutez bloodhound-python pour observer les Event IDs générés pendant l’ingestion. Par exemple :
bloodhound-python -u 'martin' -p 'martin' -d blue.local -v --zip -c All -dc DC01.blue.local -ns 10.10.100.10Après l’ingestion, nous constatons la génération d’un Event ID 5140 correspondant à l’accès au partage IPC$, accompagné d’une requête de lecture des données.
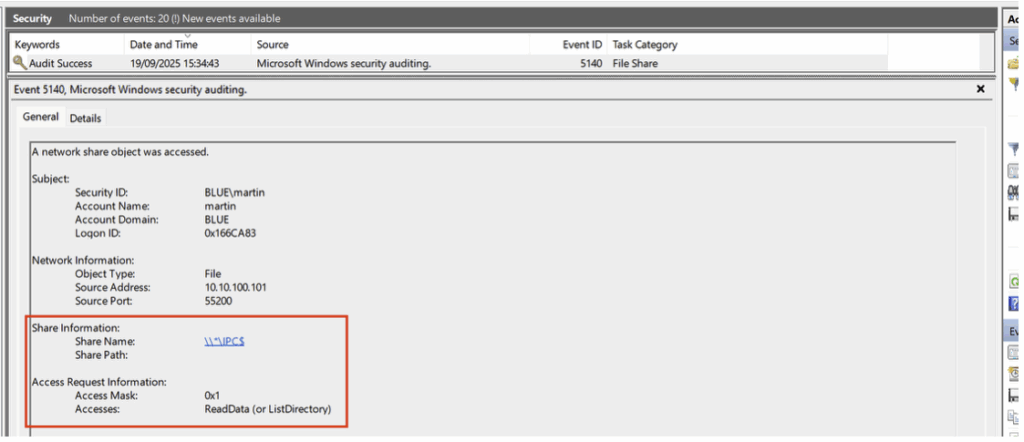
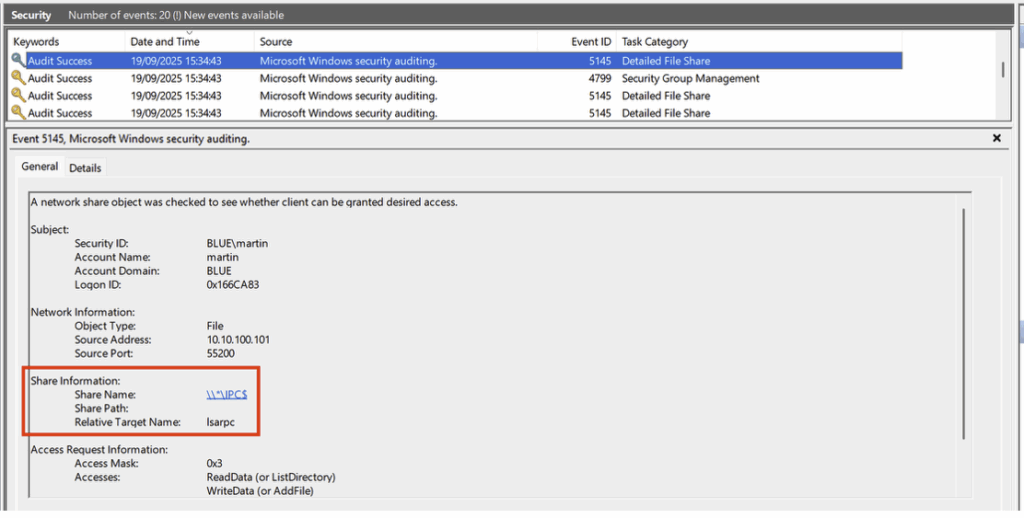
Cet événement est suivi de plusieurs Event ID 5145, également liés à l’accès au partage IPC$. Chacun d’eux cible spécifiquement différents named pipes.
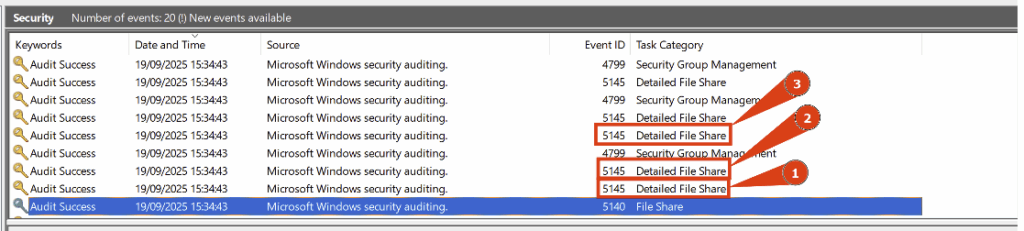
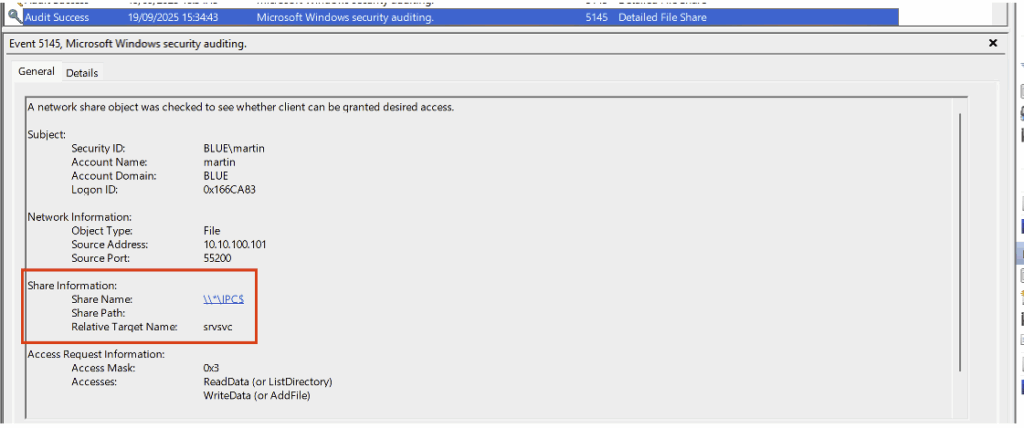
- Accès à la named pipes nommée srvsvc du partage IPC$ :
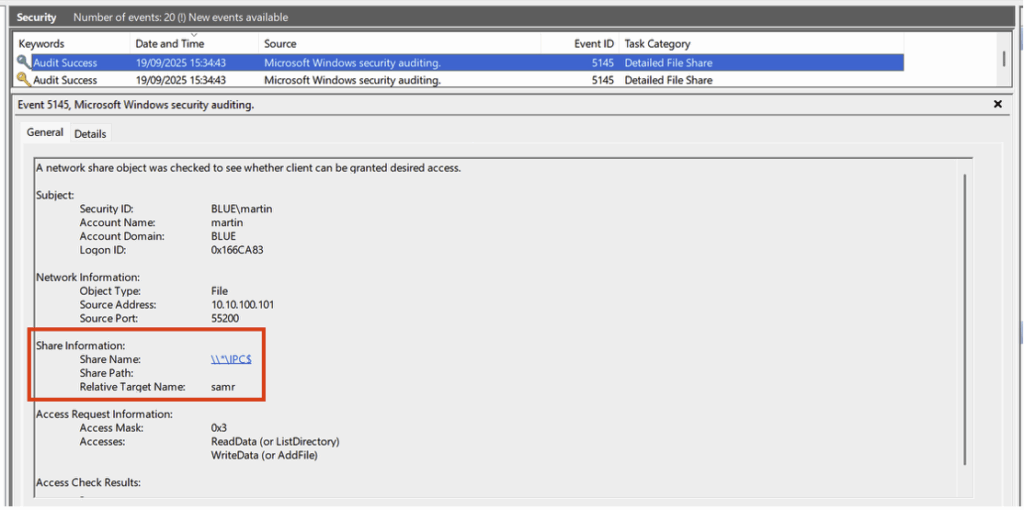
- Accès à la named pipes nommée samr du partage IPC$ :
- Et accès à la « named pipes » nommée lsarpc du partage « IPC$ » :
Pour la création de la règle dans ELK, nous allons adopter une approche minimaliste en utilisant cette fois le langage ES|QL :
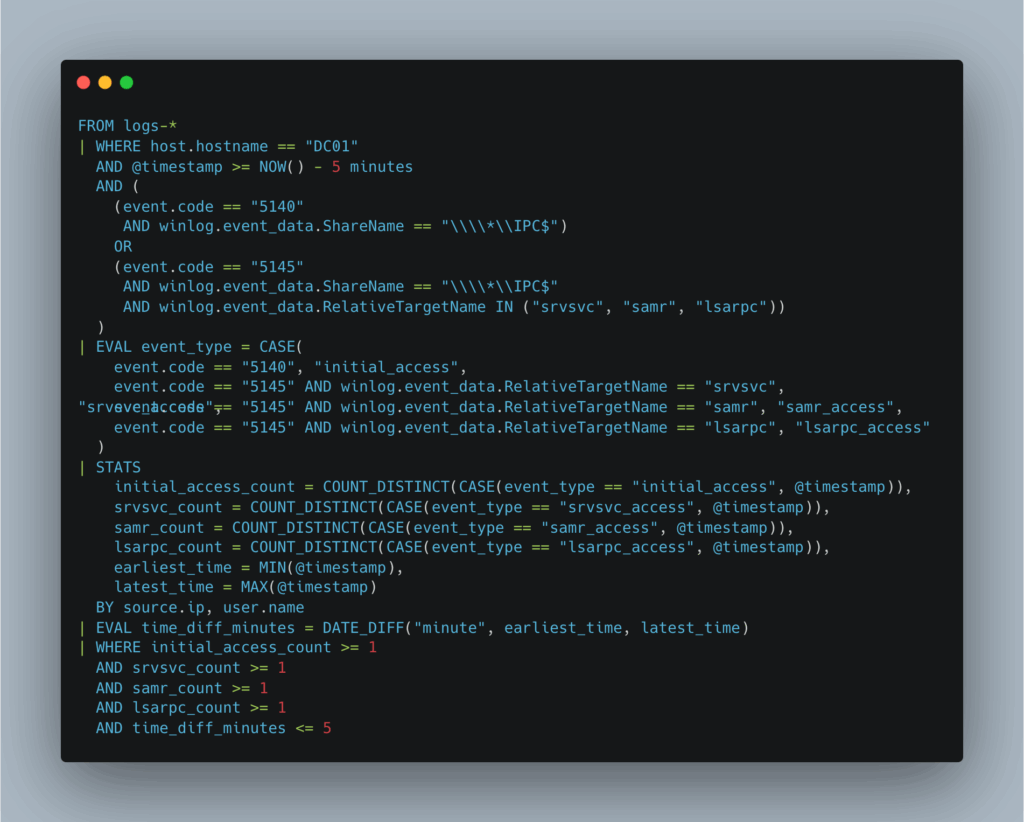
Cette règle surveille, sur une fenêtre de 5 minutes, les événements associés au partage IPC$ (5140) ainsi qu’aux named pipes (5145). Elle recherche une séquence caractéristique composée d’une connexion initiale à IPC$, suivie d’accès aux named pipes srvsvc, samr et lsarpc.
Les événements sont agrégés par adresse IP source et par utilisateur, et l’intervalle de temps entre le premier et le dernier accès est calculé. Enfin, la règle ne se déclenche que si ces quatre étapes sont observées dans un court laps de temps.
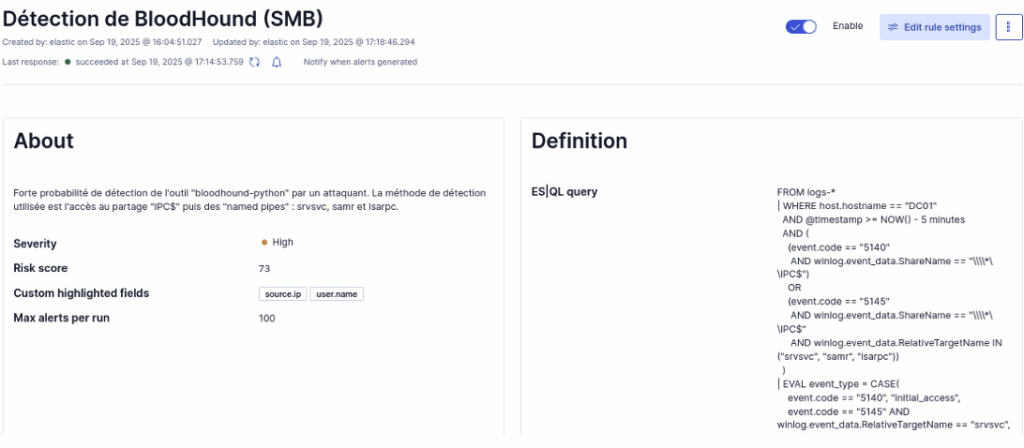
Voici à quoi ressemble la règle de détection dans le SIEM :
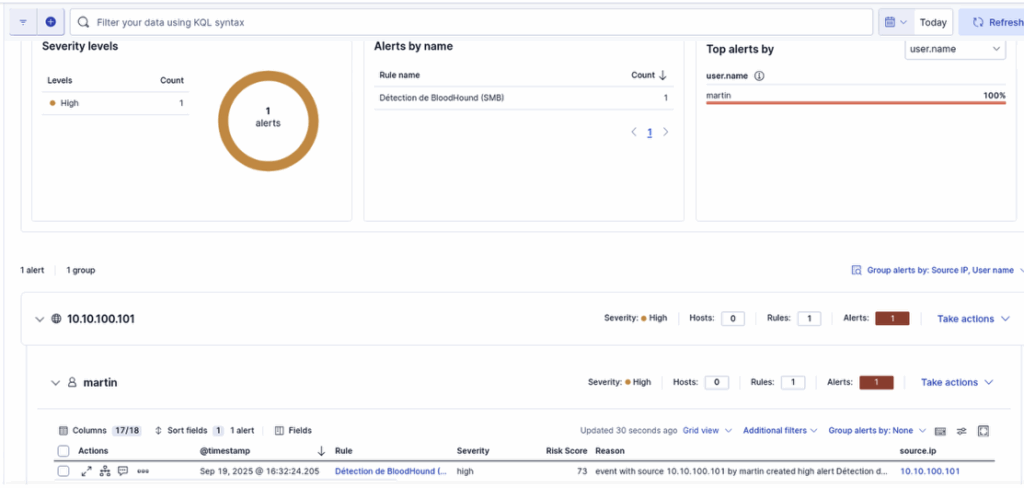
Une fois la règle ajoutée à ELK, nous relançons l’attaque depuis la machine attaquante. Dans le tableau de bord, on constate que la règle s’est bien déclenchée et a généré les alertes attendues.
Détection BloodHound via LDAP
Une autre méthode pour détecter l’utilisation de bloodhound-python consiste à déployer un leurre Active Directory (« AD Decoy »).
Dans notre exemple, le principe est de créer un objet leurre (groupe de domaine, utilisateur, OU, etc.) puis de corréler les Event ID 4662 correspondant à des opérations de lecture de cet objet lorsqu’elles sont effectuées par un compte ou une machine qui n’est ni l’administrateur du domaine ni le contrôleur de domaine, afin de réduire les faux positifs.
Pour implémenter cette règle, nous commençons par créer un groupe de domaine nommé ITAdmins.
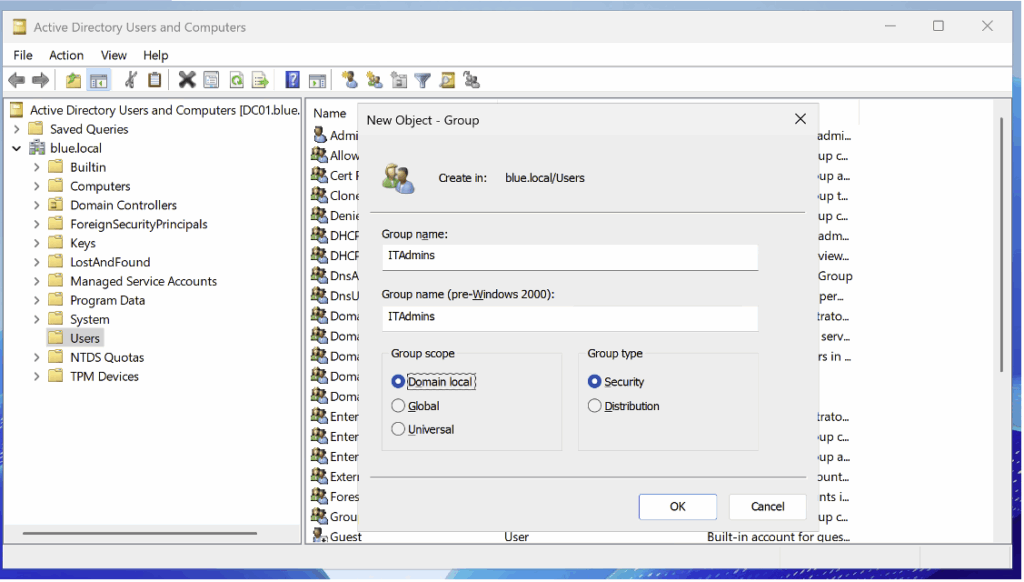
Après création du groupe, nous allons configurer l’audit de sécurité. Pour ce faire, rendez-vous dans les propriétés puis dans Security > Advanced :
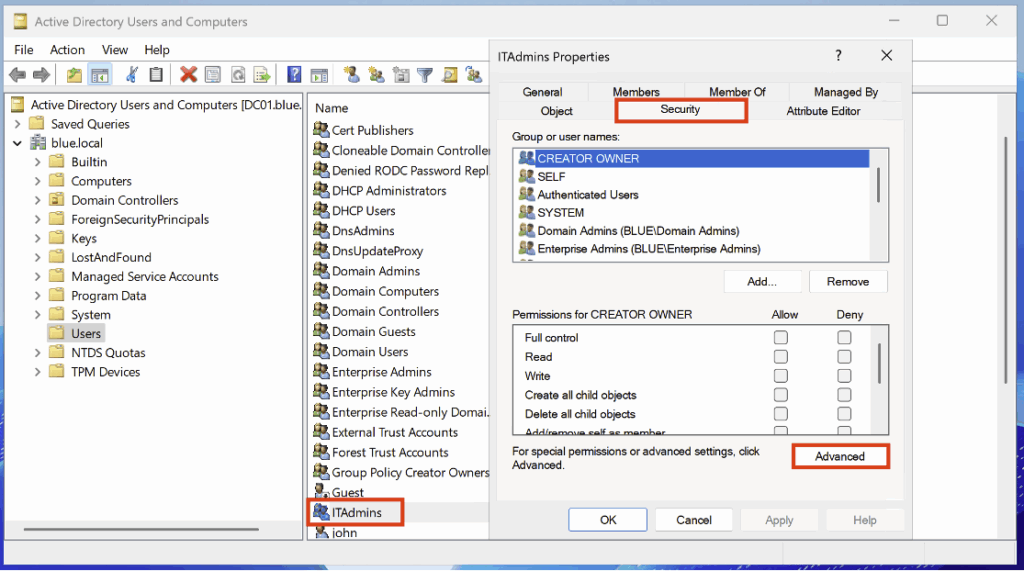
Dans ce nouvel onglet, rendez-vous dans la catégorie Auditing pour configurer les paramètres.
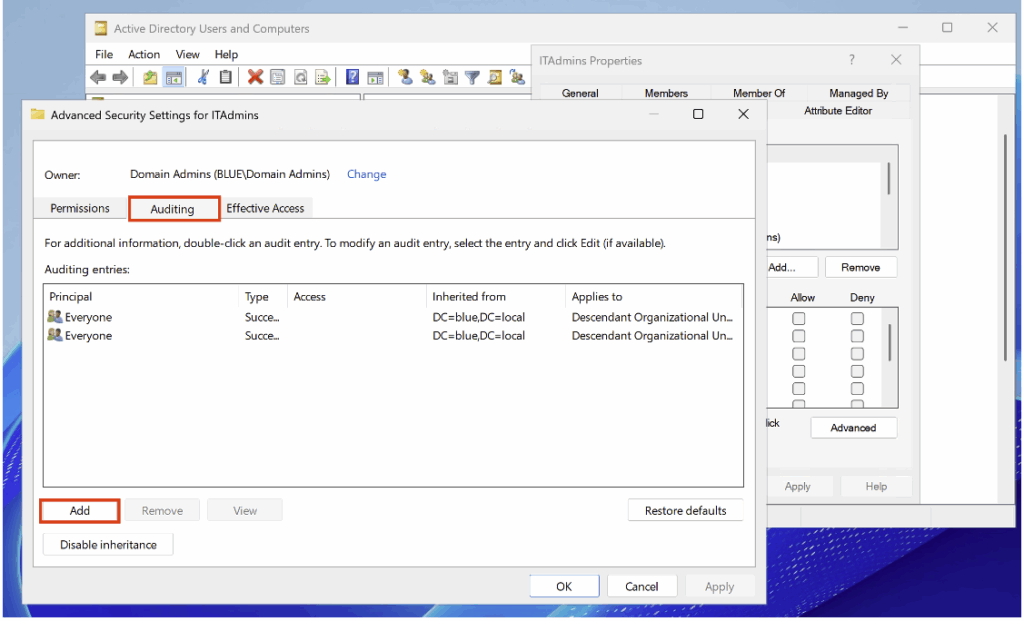
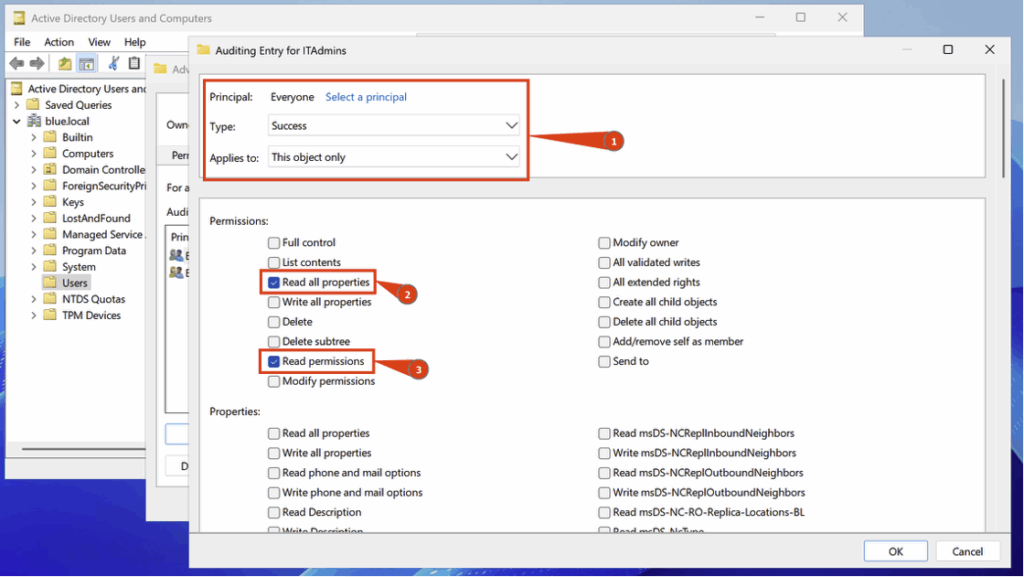
Configurez ensuite les paramètres suivants :
- Principal > Everyone
- Type > Success
- Applies to > This object only
Vous devez également cocher les deux cases suivantes : Read all properties et Read permissions.
Après configuration de la politique d’audit du groupe de domaine, on va lancer bloodhound-python et vérifier qu’on a bien l’Event ID 4662 :
bloodhound-python -u 'martin' -p 'martin' -d blue.local -v --zip -c All -dc DC01.blue.local -ns 10.10.100.10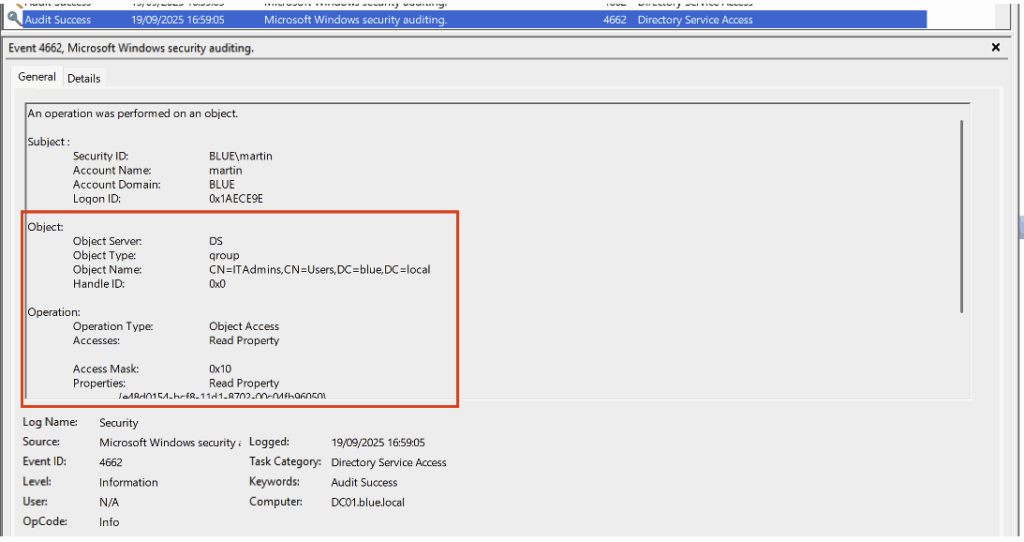
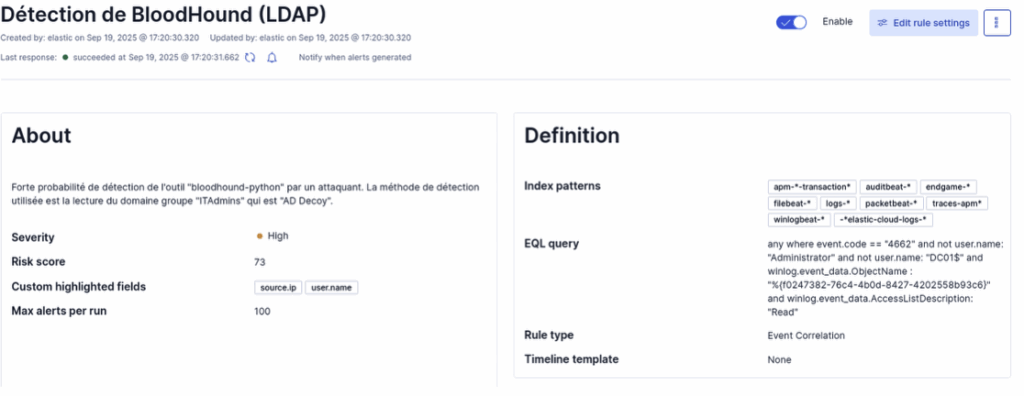
Pour la création de la règle dans ELK, nous allons utiliser cette fois le langage EQL :
any where event.code == "4662" and not user.name: "Administrator" and not user.name: "DC01$" and winlog.event_data.ObjectName : "%{f0247382-76c4-4b0d-8427-4202558b93c6}" and winlog.event_data.AccessListDescription: "Read"Voici à quoi ressemble la règle de détection dans le SIEM :
Une fois la règle ajoutée à notre ELK, on retente l’exécution de l’attaque avec notre machine attaquante. On observe bien dans le Dashboard que la règle a été enclenchée :
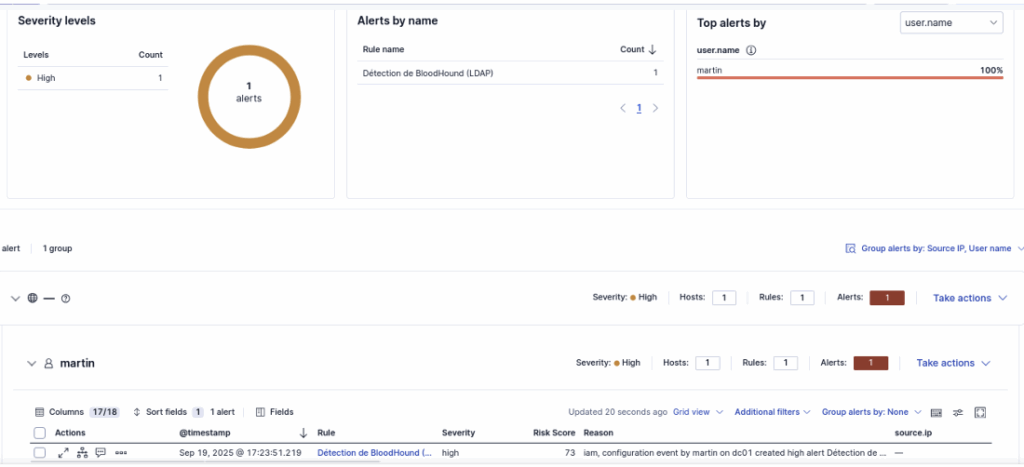
Conclusion
Cet article montre qu’un monitoring efficace d’Active Directory repose sur une approche multi-couches : l’audit côté contrôleurs de domaine, l’analyse côté postes, la collecte réseau et des règles SIEM adaptées se complètent pour offrir une visibilité robuste sur les activités LDAP et les tactiques offensives courantes. La configuration fine des sous-catégories d’audit, l’activation ciblée des SACLs et l’enrichissement par Sysmon ou les traces ETW permettent de transformer des événements bruts en indicateurs exploitables dans ELK.
La mise en place de règles ELK personnalisées et l’emploi de honeypots facilitent la détection des comportements malveillants et offrent des scénarios tests réalistes pour valider la chaîne de détection. Il est toutefois essentiel d’équilibrer sensibilité et coût opérationnel : une journalisation trop verbeuse augmente la charge sur les contrôleurs, le SIEM et l’infrastructure réseau, tandis qu’une couverture trop faible laisse des angles morts. Priorisez donc le ciblage des objets et services critiques, ajustez les seuils en fonction de votre environnement et anticipez l’impact sur le stockage et le traitement.
Enfin, le monitoring d’AD est un processus itératif : configurez, testez (avec des simulations contrôlées ou des exercices Red Team), corrélez, et affinez vos règles et vos seuils. En appliquant ces principes, vous déployerez une posture de détection pragmatique, mesurable et adaptée aux risques propres à votre domaine.
Auteurs : Alexis PARET – Pentester & Amin TRAORÉ – CMO @Vaadata