
Dans le cycle de développement d’une application web, la sécurité ne doit jamais être reléguée au second plan.
Elle s’invite à chaque étape : dès la phase de conception, lors des choix d’architecture, tout au long du développement, mais aussi après le déploiement, au travers de tests continus.
Parmi les différentes approches pour évaluer la sécurité d’une application, l’audit de code source tient une place de choix. Contrairement aux tests d’intrusion en boite noire ou grise, cette méthode permet de plonger au cœur du fonctionnement interne de l’application, d’en comprendre les mécanismes et d’identifier des failles parfois invisibles en surface.
Dans cet article, nous explorerons les principes et objectifs d’un audit de code source d’application web. Nous détaillerons également une méthode d’audit de code source basé sur l’analyse des « sources » et des « sinks », des implémentations sécurité, des dépendances, etc. Enfin, nous présenterons des exemples concrets de vulnérabilités identifiables dans le code source afin de mieux comprendre comment cette méthodologie peut être appliquée.
Guide complet sur la méthodologie d’audit de code source
Qu’est-ce qu’un audit de code source ?
L’audit de code source est une démarche d’analyse approfondie du code d’une application afin d’identifier des failles de sécurité, des erreurs de logique et des mauvaises pratiques de développement.
Cette analyse repose sur une approche mixte combinant des outils automatisés et l’intervention d’experts en sécurité. Les outils permettent de balayer l’ensemble du code pour détecter des vulnérabilités connues. Toutefois, ils sont souvent limités. C’est pourquoi l’intervention humaine reste indispensable. Grâce à une lecture ciblée et une compréhension fine du contexte, un pentester est en mesure d’identifier des failles complexes spécifiques à l’application, souvent indétectables par des outils.
Dans cette optique, la collaboration avec les développeurs est essentielle. Leur connaissance de l’architecture et des fonctionnalités leur permet d’orienter les auditeurs vers les composants critiques, en particulier ceux qui manipulent des données sensibles, interagissent avec le système de fichiers, exécutent des commandes ou effectuent des requêtes vers d’autres services.
Il est également important de prêter une attention particulière aux fonctionnalités jugées complexes, mal documentées ou potentiellement problématiques dans leur implémentation. Pour guider efficacement cette analyse, l’accès à une documentation technique détaillée ou à une cartographie de l’architecture applicative est un véritable atout. Cela permet de mieux comprendre les flux de données, les points d’entrée utilisateurs, les interactions entre modules, et donc d’anticiper les vecteurs d’attaque les plus probables.
Suite à cette phase préparatoire, l’analyse du code peut commencer.
Audit de code source via analyse des « sources » et des « sinks »
Un audit de code source ne consiste pas à examiner chaque ligne une à une. Une telle approche serait inefficace, chronophage et contre-productive. L’enjeu est de cibler les portions du code les plus sensibles, celles qui présentent un risque pour la sécurité de l’application.
Pour ce faire, une des approches les plus courantes en audit de code consiste à analyser les « sources » et les « sinks », ainsi que les chemins qui les relient.
- Une source représente une donnée en entrée de l’application, typiquement fournie par un utilisateur via un formulaire, une URL, un en-tête HTTP ou le corps d’une requête.
- Un sink, à l’inverse, désigne un point du code où cette donnée est utilisée de façon potentiellement dangereuse : exécution d’une commande système, insertion dans une requête SQL, rendu HTML non échappé, etc.
L’audit consiste alors à tracer les chemins que parcourent les données entre leur point d’entrée et leur point de sortie potentiellement vulnérable. Ce travail permet d’évaluer si des protections sont en place pour valider, filtrer ou transformer ces données avant leur usage. Par exemple, une chaîne de caractères passée en paramètre pourrait être nettoyée pour supprimer les caractères spéciaux, ou encodée pour éviter toute interprétation indésirable.
Le fait d’avoir accès au code source permet de comprendre précisément la logique de ces filtres. On peut ainsi découvrir qu’un contrôle ne couvre pas tous les cas, qu’un caractère dangereux a été oublié, ou que le filtre est mal positionné dans la chaîne de traitement.
Analyse des sources
Comprendre les différentes sources de données
Les sources directes correspondent aux valeurs fournies directement par l’utilisateur lors de son interaction avec l’application. Elles peuvent être transmises via l’URL (segments du chemin, paramètres de requête), les en-têtes HTTP (comme les en-têtes d’autorisation, les en-têtes spécifiques ou les cookies), ou dans le corps d’une requête.
Il existe également des sources indirectes, souvent plus difficiles à identifier. Par exemple, au lieu qu’une valeur soit transmise directement à un composant, le code peut la récupérer depuis une base de données. Cette donnée pourrait avoir été insérée préalablement par l’utilisateur via une autre fonctionnalité. Une autre forme de source indirecte peut survenir lorsqu’un serveur effectue une requête à un autre serveur et utilise sa réponse.
En disposant d’un contexte sur la source, comme l’endroit où elle est utilisée et son format, il devient possible d’anticiper les vulnérabilités potentielles liées à sa manipulation. Par exemple :
- Si la source est un champ de commentaire sur un article de blog, une vulnérabilité de type Cross-Site Scripting (XSS) est probable.
- Si la source correspond à un modèle de génération d’email, une injection de template côté serveur (SSTI) est envisageable.
- Et si la source représente un identifiant de ressource, une vulnérabilité de type Insecure Direct Object Reference (IDOR) peut être présente.
Suivre les flux et les usages dans le code source
Une fois que le contexte autour de la source est suffisamment compris, l’étape suivante consiste à suivre toutes les utilisations de cette source dans le code. Il faut relever comment la valeur est manipulée, transformée ou conditionnée à certains contextes. Il est également crucial de prendre en compte les interactions entre plusieurs sources. Par exemple, une source peut indiquer à l’application d’appliquer une transformation sur une autre source.
Enfin, certains chemins d’exécution aboutissent à un stockage de la donnée dans un emplacement qui sera utilisé ultérieurement par un autre composant. Par exemple, une entrée utilisateur peut être enregistrée en base de données pour être affichée sur d’autres pages. Cela crée une nouvelle source indirecte dérivée de la source initiale. Dans ce cas, les portions de code qui récupèrent cette donnée stockée deviennent un nouveau point de départ pour une analyse approfondie.
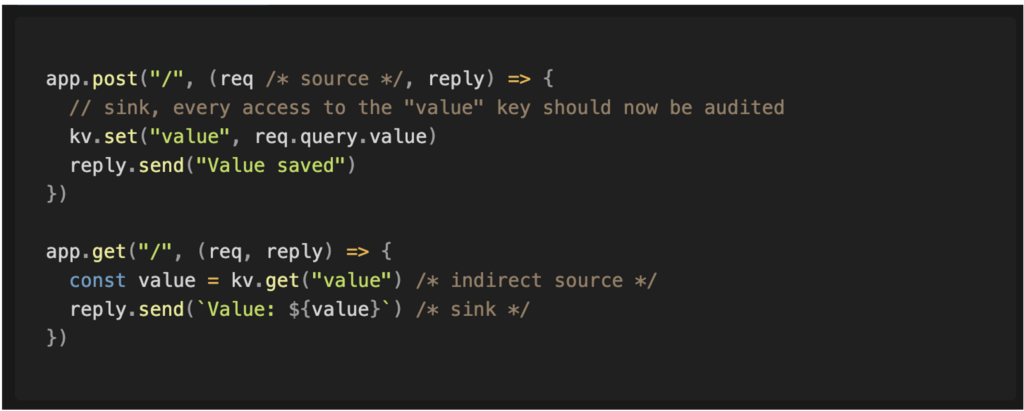
Prioriser les analyses en fonction des risques
Cette approche permet de couvrir l’ensemble de l’application. Elle offre également la possibilité d’identifier des sinks jusqu’alors inconnus, notamment des fonctions potentiellement dangereuses issues de bibliothèques tierces.
Cependant, cette méthode est particulièrement chronophage, car tous les chemins analysés ne débouchent pas nécessairement sur des sinks pertinents ou exploitables. Il faut donc accepter une part d’exploration peu fructueuse.
Une fois que tous les chemins ont été identifiés et répertoriés, il devient possible de les classer en fonction du niveau de dangerosité des sinks atteints. Cette étape permet de prioriser l’analyse et les actions correctives en se concentrant sur les zones les plus sensibles du code.
Audit des sinks
Cette méthode adopte une approche inverse de la précédente : l’analyse ne part plus des sources, mais directement des sinks.
L’intérêt est qu’en ciblant d’emblée les points critiques du code, on peut interrompre l’analyse dès qu’un filtre efficace est détecté, rendant l’exploitation du sink impossible ou improbable.
Pour identifier les sinks présents dans l’application, on peut rechercher dans le code des motifs connus comme dangereux, par exemple l’usage de requêtes SQL non préparées ou de fonctions exécutant des commandes système.
Il existe des outils permettant d’automatiser cette détection. Semgrep, par exemple, permet d’identifier l’utilisation de méthodes sensibles. Toutefois, il s’appuie sur des modèles créés par d’autres utilisateurs, ce qui présente plusieurs limites.
Certains sinks évidents peuvent ne pas être détectés, et inversement, l’outil peut générer de nombreuses fausses alertes sur des modèles inoffensifs. Ce phénomène, connu sous le nom de fatigue d’alerte, peut entraîner une lassitude et un désengagement des développeurs face aux rapports de sécurité.
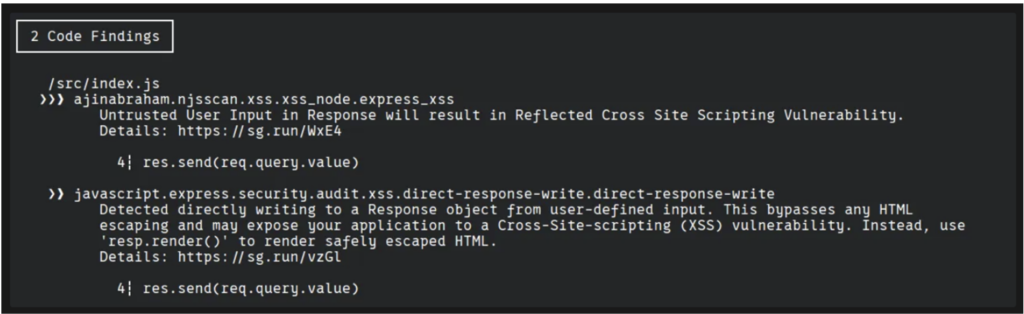
Il est possible de créer des règles personnalisées pour renforcer la sécurité du code. Par exemple, une règle peut imposer que toutes les routes d’une application soient protégées par des mécanismes d’authentification et d’autorisation.
Comme pour l’analyse orientée sources, un sink peut être indirectement influencé par une donnée utilisateur. Si la valeur transmise à un sink provient d’une base de données, alors toute insertion passée dans cette base devient un nouveau point d’entrée potentiel, à explorer comme un sink à part entière.
Quelle approche choisir entre analyse des sources et audit des sinks ?
Chaque méthode présente ses avantages et ses limites. L’analyse orientée sources génère souvent un grand nombre de chemins à examiner, mais elle permet une meilleure couverture des sinks présents dans l’application.
À l’inverse, l’approche par les sinks est plus rapide et permet de réduire le nombre de chemins à analyser, car on peut stopper l’exploration dès qu’un filtre rend la donnée inoffensive.
En pratique, un audit de code source efficace combine les deux approches afin de bénéficier à la fois de la précision de l’analyse orientée sinks et de l’exhaustivité de l’analyse orientée sources.
Revue des implémentations sécurité dans le code source
Une fois qu’un chemin entre une source et un sink a été identifié, l’étape suivante consiste à vérifier que la valeur transite de fonction en fonction sans être altérée de manière à empêcher l’exploitation du sink.
Tout au long de ce parcours, la donnée peut traverser des filtres ou des transformateurs. Un filtre peut, par exemple, bloquer certains caractères, tandis qu’un transformateur peut accepter la valeur mais supprimer les éléments considérés comme invalides.
L’objectif est donc de documenter toutes les transformations subies par la donnée, afin de pouvoir construire une entrée qui franchisse chaque étape du traitement tout en conservant la capacité d’exploiter le sink final.
Analyse des listes d’interdiction (deny lists ou listes noires)
Une stratégie de filtrage basée sur une liste d’interdictions consiste à bloquer une valeur si elle présente certaines caractéristiques ou si elle appartient à une liste explicite d’éléments interdits.
Par exemple, un code peut tenter de détecter la présence de caractères non valides dans une chaîne avant de procéder à son insertion.
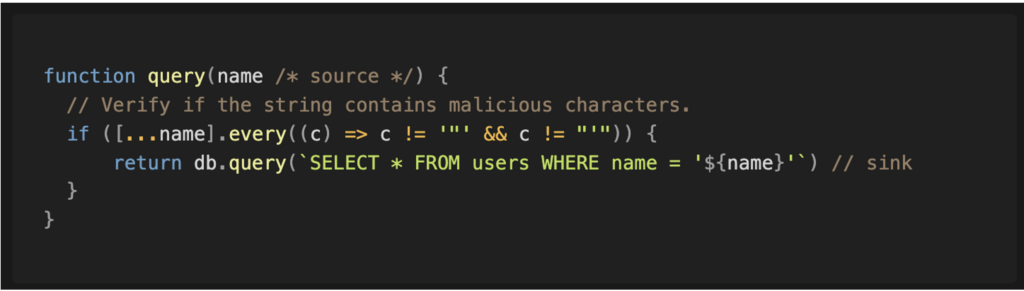
Cependant, tous les filtres ne se valent pas. Un filtre fondé sur une liste de valeurs interdites est souvent considéré comme faible, car il ne bloque que les éléments explicitement connus comme dangereux.
Des cas peuvent avoir été oubliés ou tout simplement méconnus, ce qui laisse une marge importante à un attaquant pour introduire des valeurs inattendues capables d’altérer le comportement du programme.
Par exemple, le caractère antislash (\) ajouté en fin de chaîne peut permettre d’échapper une apostrophe. Avec MariaDB, si une autre propriété manipulable intervient ensuite dans la requête, cela pourrait être exploité pour exécuter des requêtes SQL arbitraires.
Analyse des listes d’autorisation (allow lists ou listes blanches)
Une stratégie basée sur une liste d’autorisations consiste à n’accepter que certaines valeurs spécifiques. Ce type de filtre est généralement considéré comme plus robuste, car l’ensemble des valeurs autorisées est défini à l’avance, ce qui facilite leur revue et limite les comportements inattendus.
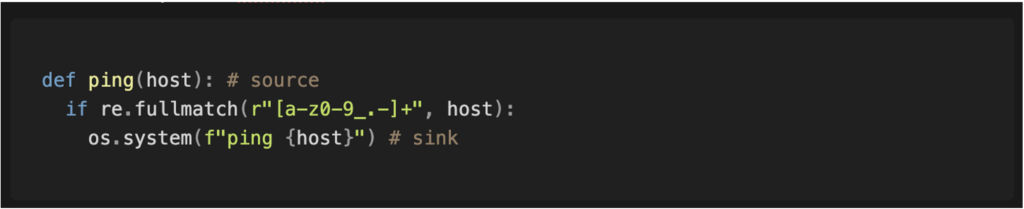
Adopter une telle approche renforce significativement la sécurité, en réduisant considérablement les possibilités d’attaque. Par exemple, en l’absence d’un filtre adéquat, un attaquant pourrait injecter des caractères spéciaux pour exécuter des sous-commandes et ainsi obtenir une exécution de code arbitraire sur le service ciblé.
Cependant, même une stratégie basée sur une liste d’autorisation n’est pas infaillible. Dans l’exemple évoqué, le paramètre "host" reste interprété par le programme. Le filtre en place autorise l’utilisation du tiret (-) en début de valeur, ce qui peut être détourné pour injecter des arguments supplémentaires dans la commande et contourner les protections.
Neutralisation
Les filtres doivent être appliqués lorsque la valeur peut atteindre un sink capable de l’interpréter de manière dangereuse. Cependant, la meilleure solution reste d’éviter d’avoir des sinks dangereux dès le départ.
Il existe souvent des alternatives plus sûres aux méthodes à risque, permettant de garantir que la valeur transmise ne sera pas utilisée de façon spéciale ou malveillante. Les développeurs devraient privilégier l’usage de méthodes sécurisées plutôt que d’ajouter des filtres par-dessus des méthodes intrinsèquement dangereuses.
Par exemple, dans les cas évoqués précédemment, il est préférable d’utiliser des requêtes SQL préparées plutôt que des requêtes brutes. Dans un autre cas, il vaut mieux utiliser une méthode qui n’exécute pas la commande via un shell, et, si possible, recourir au séparateur d’options de fin de commande pour éviter toute interprétation indésirable.

La neutralisation consiste donc à s’assurer que la valeur n’est pas traitée avec une signification particulière susceptible d’être exploitée.
Plusieurs mesures de protection peuvent être mises en place sur le chemin menant à sink. La meilleure pratique pour les développeurs est de toujours placer les contre-mesures les plus robustes le plus près possible du sink.
Par exemple, dans une même fonction, il est conseillé d’appliquer les filtres juste avant l’appel au sink dangereux. Cela facilite l’analyse du code source, car cela garantit que tous les chemins menant au sink passent obligatoirement par ces filtres.
En revanche, si les filtres sont placés trop en amont, près de la source, il existe un risque que de nouveaux chemins vers le sink apparaissent sans passer par ces protections.
Analyse des dépendances
Des alertes de sécurité peuvent être publiées lorsqu’une vulnérabilité est découverte dans une bibliothèque. Une vulnérabilité est souvent signalée lorsqu’une fonctionnalité censée être sécurisée peut être exploitée de manière inattendue.
Cependant, si la bibliothèque est conçue pour fournir des méthodes non sécurisées, il est possible qu’aucune CVE ne soit publiée à son sujet.
Il est donc important d’examiner les dépendances utilisées par l’application afin d’identifier si l’une d’entre elles propose des méthodes dangereuses, comme l’exécution de requêtes SQL brutes ou l’accès à des fichiers locaux. Ces méthodes à risque doivent être intégrées à la liste des sinks à analyser.
Dans certains cas, des contre-mesures sont mises en œuvre via des fonctions utilitaires fournies par des bibliothèques tierces. Par exemple, une fonctionnalité d’upload de fichiers peut utiliser une fonction externe pour déterminer le type du fichier.
Pour s’assurer qu’un filtre empêche effectivement d’atteindre un sink, il peut être nécessaire d’analyser le code de ces bibliothèques afin de vérifier si des valeurs spéciales, non anticipées par les développeurs, peuvent être exploitées.
Exemples de vulnérabilités identifiées lors d’un audit de code source d’une application web
Dans le cas le plus simple, la source et le sink sont proches l’un de l’autre. Cependant, la plupart des situations sont plus complexes et impliquent un flux de données passant par plusieurs fonctions et plusieurs fichiers.
Mass Assignment
Les vulnérabilités de type mass assignment apparaissent souvent dans les applications où les utilisateurs peuvent modifier leur profil.
L’application utilise alors toutes les propriétés reçues et les enregistre en base de données, sans vérifier précisément quels champs sont modifiés.
Souvent, l’application ne contrôle que l’autorisation de modifier l’utilisateur lui-même, ce qui signifie que modifier l’utilisateur courant est autorisé, mais cela ne garantit pas que les champs modifiés le soient également.
Dans certains cas, cela peut même permettre d’écrire des propriétés ou des objets liés de manière non désirée.
Lors de l’analyse du code source de l’application, il est important d’identifier tous les points d’entrée. On peut commencer par examiner le routeur de l’application.
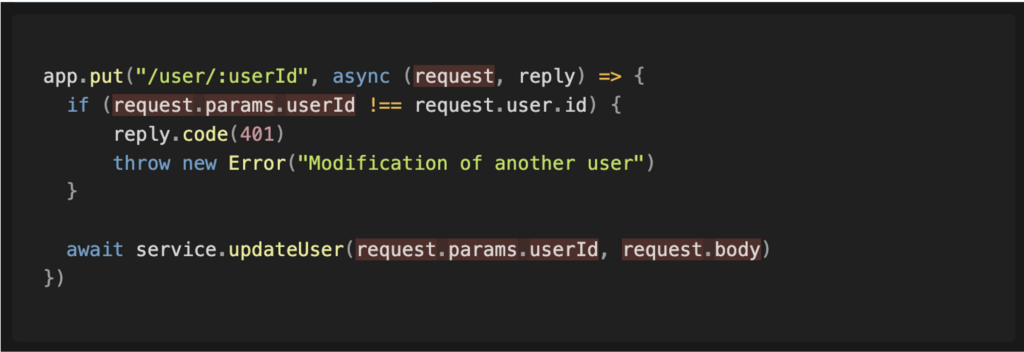
Le paramètre « request » constitue la source à analyser. On remarque dans les lignes suivantes que cette valeur est utilisée dans une comparaison avant d’être passée à une fonction, ce qui permet de poursuivre l’analyse dans cette fonction.
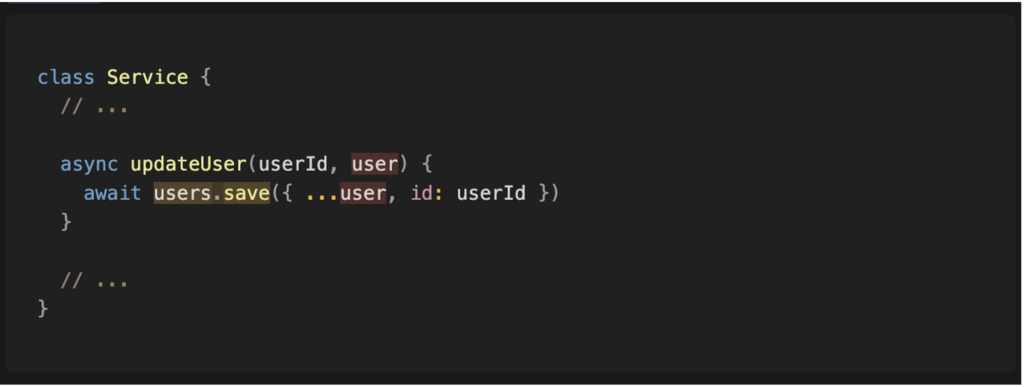
Dans la fonction finale, on observe que la valeur contrôlée par l’utilisateur atteint la méthode « save ». Nous disposons ainsi d’un chemin complet entre la source et le sink.
File Path Traversal
Il arrive parfois que des développeurs cherchent à simplifier le processus et, au lieu de créer une couche d’indirection sécurisée, laissent les utilisateurs spécifier directement le chemin du fichier qu’ils souhaitent accéder.
Lors de l’analyse des sinks de l’application, on cherche à identifier toutes les fonctions dangereuses susceptibles d’être appelées. Par exemple, on peut commencer par rechercher les appels à la fonction file_get_contents dans le code de l’application.
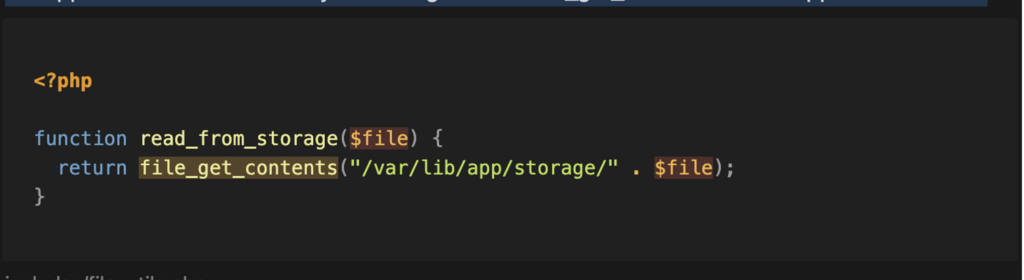
On remarque que cette fonction est utilisée dans la fonction read_from_storage . La source de cette fonction passe par une mesure de sécurité qui ajoute un dossier au début du chemin du fichier. Malheureusement, cette mesure est insuffisante, et un attaquant pourrait exploiter une vulnérabilité de type path traversal pour accéder à n’importe quel fichier du serveur.
Les étapes suivantes consistent à considérer cette fonction comme un sink et à rechercher toutes ses utilisations dans le code de l’application.
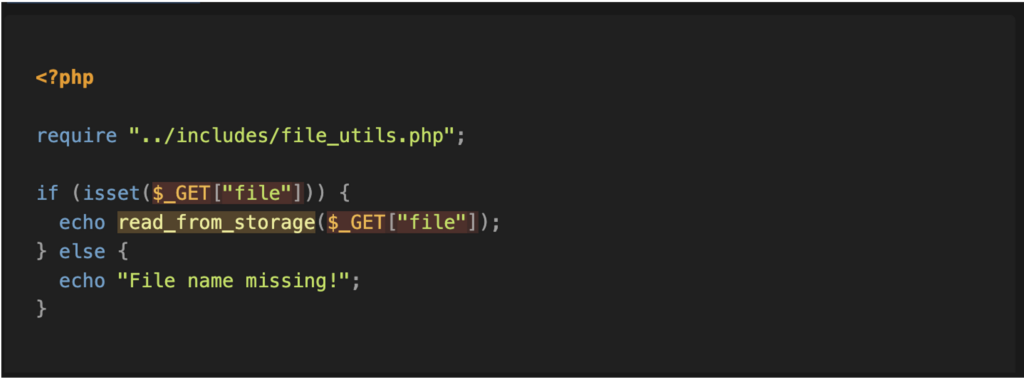
Enfin, on constate que la chaîne complète est présente : il est possible de fournir le paramètre de requête « file » (source) pour atteindre la fonction « file_get_contents » (sink) et lire le contenu du fichier.
Conclusion
Étant donné que les audits de code source sont limités dans le temps, différentes stratégies sont utilisées pour effectuer une analyse plus efficace.
L’utilisation d’une stratégie source-sink permet d’identifier les chemins dans le code qui peuvent être compromis par un attaquant ou les contre-mesures mises en œuvre pour protéger un sink. De cette façon, un auditeur peut se concentrer sur les lignes les plus pertinentes de l’application.
Même s’il existe des outils pour aider à la découverte des sinks, ces derniers ne sont pas encore assez aboutis pour identifier tous les cas. Ils peuvent toutefois être intégrés dans les cycles de développement afin de sensibiliser les développeurs aux modèles susceptibles d’être exploités par des attaquants. Quoi qu’il en soit, les outils automatisés ne sont pas encore prêts à remplacer l’analyse manuelle.
Auteur : Arnaud PASCAL – Pentester @Vaadata