
Développé en 2012 et rendu open source en 2015 par Facebook, GraphQL (Graph Query Language) est depuis 2019 sous la tutelle de “GraphQL Foundation”.
GraphQL est un langage de requêtes, c’est à dire un langage utilisé pour accéder aux données d’une base de données ou tout autre système d’information, au même titre que le SQL (Structured Query Language).
C’est aussi un SDL (Specification and Description Language). En effet, il n’y a pas d’implémentation officielle fournie par ses créateurs. Les diverses implémentations déjà existantes (Apollo Server, Express GraphQL, graphql-yoga et bien d’autres!) suivent les spécifications liées à GraphQL.
Comme toute API, GraphQL permet de transférer de la donnée entre un client et un serveur. Il s’agit d’une alternative aux APIs REST (Representationnal State Transfer). Le principal avantage de GraphQL est de pouvoir fournir une application via une requête unique, en déléguant au serveur la tâche de structurer les données.
En 2023, une enquête menée par Postman montre que les API GraphQL sont la troisième architecture API la plus utilisée. Ainsi, un pentester sera régulièrement confronté à ce type d’API lors de pentests.
Dans cet article, nous détaillerons le fonctionnement des APIs GraphQL, les vulnérabilités et attaques courantes sur ce type de systèmes, ainsi que les bonnes pratiques et mesures à implémenter pour sécuriser vos systèmes. Nous reviendrons également sur la méthodologie et les outils utilisés lors d’un pentest d’API GraphQL.
Avant de se plonger dans l’exploitation des différentes vulnérabilités liées à ce type d’API, il est important de prendre le temps de le comprendre.
Du point de vue d’un auditeur, une compréhension approfondie du fonctionnement de GraphQL est cruciale.
Nous allons donc commencer par détailler la structure et les principaux concepts de GraphQL, avant d’aborder les différents vecteurs d’attaque et vulnérabilités exploitables possibles.
Le schéma est l’élément central d’une API GraphQL. Il en constitue la structure fondamentale, définissant l’ensemble des interactions possibles entre le serveur et le client. Pour une API donnée, il n’existe qu’un seul schéma qui fait office de référence.
C’est dans le schéma que sont spécifiés les types de requêtes qu’un client peut soumettre, les types de données récupérables depuis le serveur, ainsi que les relations existantes entre ces différents types de données.
Toutes les données manipulées sont organisées par « types ». Nous allons à présent découvrir les types les plus couramment rencontrés et ceux qui retiendront notre attention dans le cadre d’un pentest.
Le type scalaire est le type de données le plus élémentaire dans GraphQL. Il représente les données primitives qui sont affectées au champs :
L’exemple suivant illustre l’utilisation de types scalaires pour définir l’objet Book, qui comporte trois champs de types respectifs String, String et Int :

Ce sont les briques de base permettant de construire des types plus complexes que nous verrons par la suite.
Le type objet est la construction centrale permettant de modéliser des structures de données complexes avec GraphQL. La vaste majorité des types définis dans une API GraphQL sont des objets.
Un objet est composé de champs, chacun ayant son propre type de données associé. Ce type peut être un scalaire (String, Int, etc.) pour les données primitives, mais aussi un autre objet pour représenter des données imbriquées.
D’autres types plus avancés comme les énumérations, unions, ou interfaces peuvent également être utilisés, mais nous ne les présenterons pas ici.
Si l’on reprend l’exemple précédent, Book est un objet composé uniquement de champs scalaires.
On peut imaginer un objet plus complexe, Library. Il va nous permettre d’introduire les listes et les non-null, ainsi que de découvrir une implémentation un peu plus complexe d’un objet.
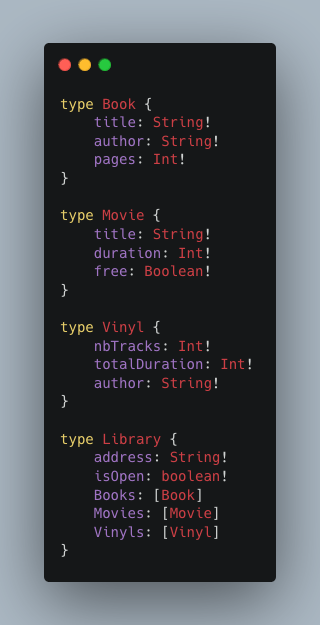
La notation [Type!] indique une liste dont les éléments sont obligatoirement de type Type. Le point d’exclamation indique que ce champ ne peut pas être null (attention a ne pas confondre une liste vide et une liste null).
Les objets sont des briques essentielles en GraphQL, qui permettent de structurer des modèles de données.
Si la plupart des types définis dans un schéma GraphQL sont des objets, il existe aussi deux types spéciaux : les queries et les mutations.
Ce sont ces types que nous utiliserons pour récupérer ou modifier des données.
Une Query sert à récupérer des données depuis le serveur GraphQL. Elle suit le principe fondateur de GraphQL en ne renvoyant que les champs explicitement demandés dans la requête.
Voici un exemple de query basique pour récupérer certains champs de l’objet Book :

Nous avons ici une query très basique, nommée GetLibrary, ou nous demandons explicitement certains champs. Nous obtiendrons en réponse uniquement les champs demandés.
Les queries peuvent être bien plus complexes en ajoutant des arguments, des variables, des fragments, des directives, etc. Nous n’entrerons pas dans ces détails pour l’instant.
À l’inverse, les Mutations permettent de modifier les données côté serveur (création, mise à jour, suppression). Une Mutation peut également renvoyer des données dans sa réponse.
Imaginons que nous voulions ajouter un nouveau livre à notre bibliothèque. Nous pourrions utiliser une mutation comme celle-ci :
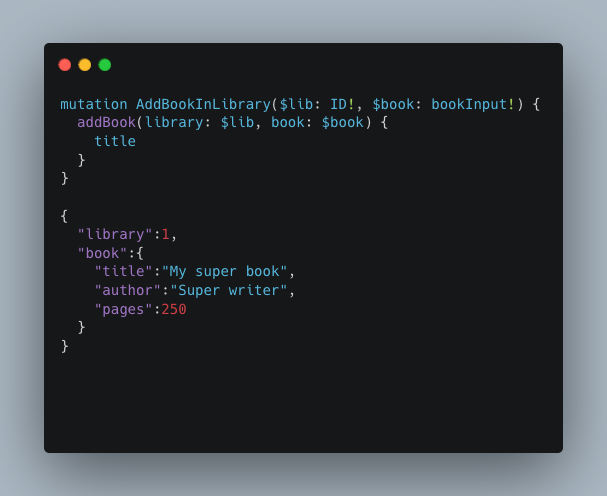
Cette mutation nous permet d’ajouter un livre dans une bibliothèque. AddBookInLibrary spécifie les champs attendus pour cette mutation, et addBook est le champ qui sera exécuté. Nous demandons en retour le champ title, il sera renvoyé dans la réponse si la requête est correctement effectuée.
Tout comme les Queries, les Mutations peuvent être très complexes et imbriquées selon les besoins. Mais ce simple exemple illustre leur rôle principal de modification des données.
Nous avons à présent compris la base de GraphQL. Une compréhension approfondie de ces concepts est essentielle pour bien maîtriser ce langage et optimiser les tests d’intrusion sur les APIs l’utilisant.
Avant de rentrer dans le vif du sujet, il est important de rappeler que le pentest d’une API GraphQL suit globalement les mêmes règles que pour les autres types d’API.
La méthodologie de tests sera donc similaire. Cependant, GraphQL ayant ses spécificités, certaines étapes et certains vecteurs d’attaque lui sont propres.
Une phase de reconnaissance est nécessaire pour évaluer la surface d’attaque, à moins que le client fournisse une documentation complète de l’API. Nous détaillerons plus bas les outils et techniques à notre disposition.
Une fois en possession de ces informations, nous procéderons à la partie d’identification de failles. Nous testerons ici des vulnérabilités communes à toutes les API (injections, défaut de contrôle d’accès, exposition de données accessibles, etc.) mais aussi des vulnérabilités spécifiques à GraphQL.
Pour en savoir plus sur les objectifs et la méthodologie de tests d’un pentest API, nous vous renvoyons vers notre article dédié sur le sujet : Pentest API : objectifs, méthodologie, tests en boite noire, grise et blanche.
La première étape cruciale lors du pentest d’une API GraphQL est de découvrir son point d’entrée. Cela n’est pas toujours évident, notamment si l’API n’est utilisée que pour certaines fonctionnalités ou en fonction de rôles particuliers.
Nous allons alors “fuzz” notre cible pour trouver le point d’entrée, en utilisant par exemple cette wordlist de Seclists, avec comme corps de requêtes “query{__typename}”.
Si nous obtenons une réponse contenant {”data”:{”__typename”:”Query”}}, alors cela confirmera la présence d’une API GraphQL sur l’URL testée.
On peut aussi simplement utiliser l’application de manière légitime et l’endpoint graphql sera découvert.
Une fois le point d’entrée découvert, nous pouvons commencer la partie de découverte et d’énumération du schéma.
Lors d’un pentest d’API GraphQL, les auditeurs peuvent s’appuyer sur divers outils pour faciliter leur tâche à différentes étapes.
Voici un tour d’horizon des principaux outils à connaître :
L’introspection n’est pas un outil, mais une fonctionnalité de GraphQL. Elle permet de récupérer le schéma complet d’une API, qui définit sa structure de données.
On utilisera cette requête d’introspection :
{__schema{queryType{name}mutationType{name}subscriptionType{name}types{…FullType}directives{name description locations args{…InputValue}}}}fragment FullType on __Type{kind name description fields(includeDeprecated :true){name description args{…InputValue}type{…TypeRef}isDeprecated deprecationReason}inputFields{…InputValue}interfaces{…TypeRef}enumValues(includeDeprecated :true){name description isDeprecated deprecationReason}possibleTypes{…TypeRef}}fragment InputValue on __InputValue{name description type{…TypeRef}defaultValue}fragment TypeRef on __Type{kind name ofType{kind name ofType{kind name ofType{kind name ofType{kind name ofType{kind name ofType{kind name ofType{kind name}}}}}}}}Si elle est activée, cette requête retournera une réponse JSON détaillant l’ensemble des types, champs, arguments, etc. définis dans le schéma.
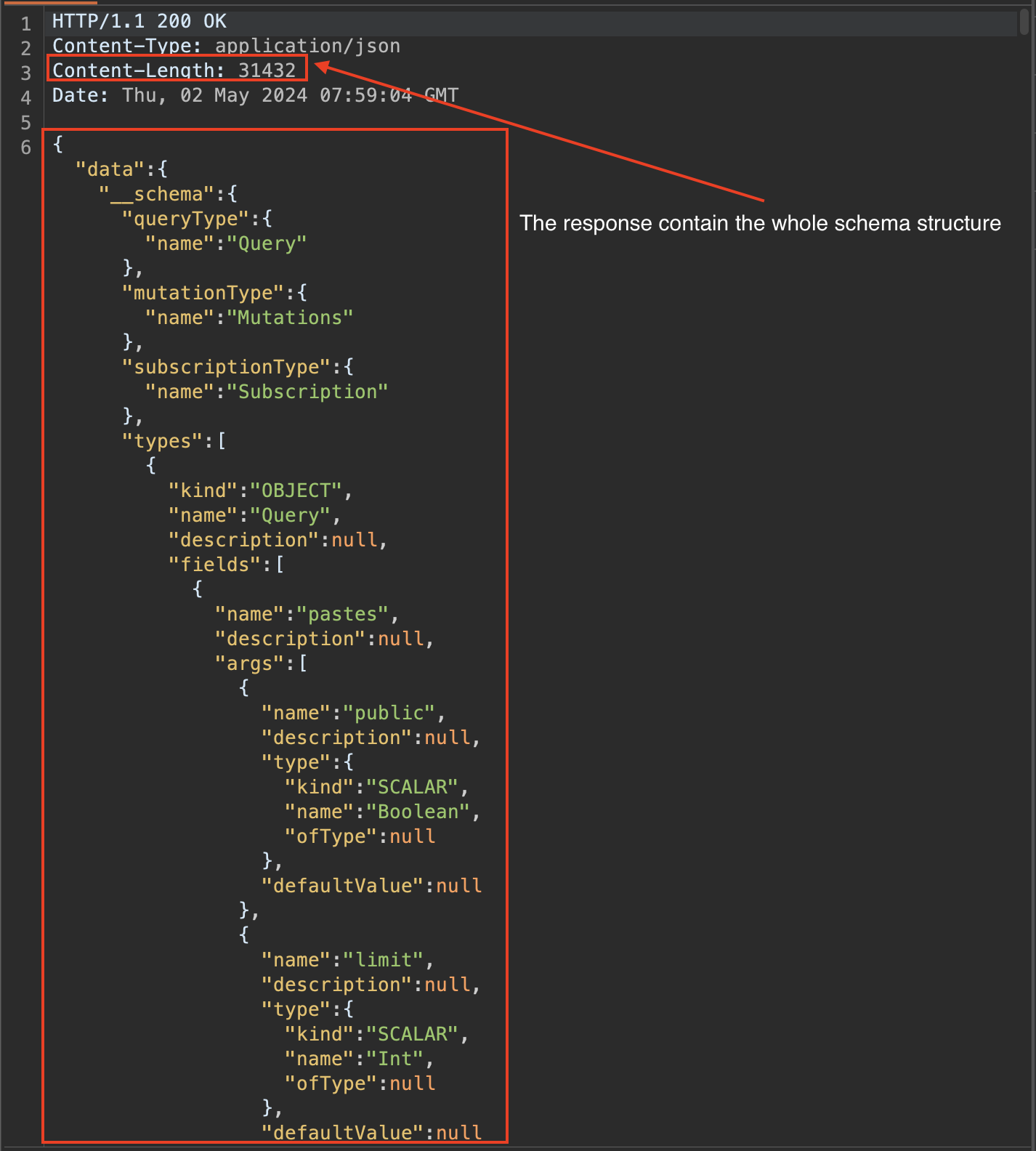
Avoir accès au schéma complet est d’une grande utilité, et permet de terminer la phase d’énumération.
En effet, une fois en notre possession, il est possible d’identifier des zones potentiellement sensibles ou des données qui ne devraient pas être exposées publiquement.
Cependant, pour des raisons de sécurité, l’introspection est généralement désactivée sur les API GraphQL en production (en théorie).
Lorsque l’introspection du schéma est désactivée sur une API GraphQL, l’outil Clairvoyance peut être utilisé comme alternative pour tenter de reconstituer le schéma.
Son fonctionnement repose sur l’utilisation d’une wordlist.
A travers l’envoi de plusieurs requêtes l’outil va s’appuyer sur une fonctionnalité de GraphQl, les suggestions. A noter qu’il est possible qu’elles ne soient pas renvoyées côté client, rendant totalement inefficace cet outil.
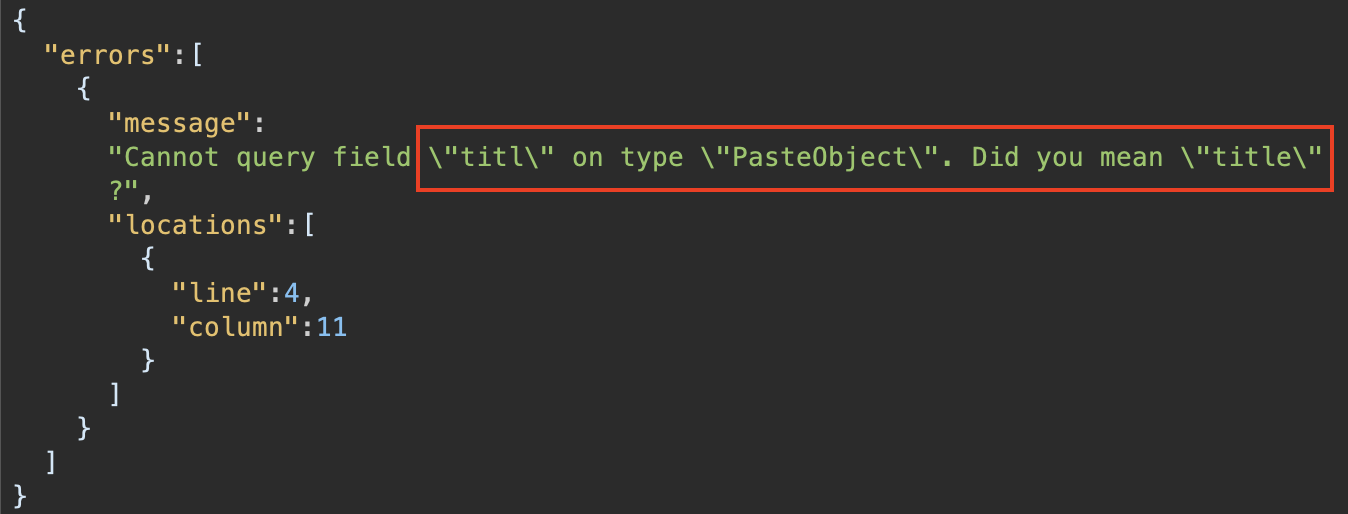
En analysant ces réponses, Clairvoyance parvient à reconstruire une partie du schéma de l’API sous forme de JSON.
Bien que moins complète que l’introspection, cette technique permet d’obtenir une bonne vision d’ensemble du schéma.
GraphQL Voyager est un outil précieux qui permet de visualiser le schéma d’une API GraphQL, à partir du schéma que nous avons pu récupérer en utilisant l’introspection ou Clairvoyance.
Il est possible de récupérer une query d’introspection depuis son interface.
Une fois le schéma chargé, l’outil va générer une représentation graphique de la structure du schéma. Tous les types, champs et relations sont affichés, et cela facilite grandement la compréhension de l’architectures de l’API.
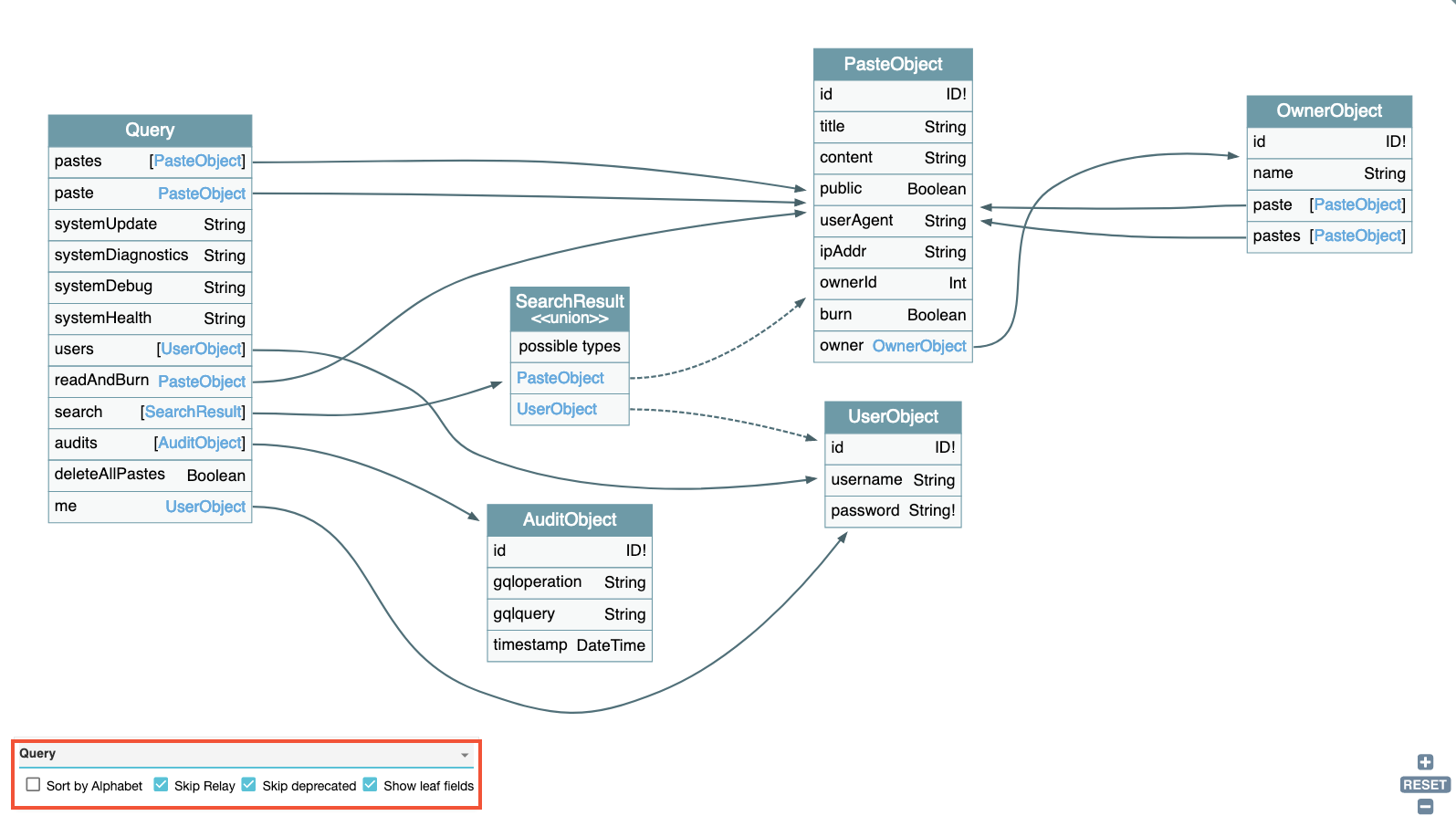
Un panel en bas en gauche permet d’explorer plus en détail la liste des query, mutation et subscription disponibles.
En résumé, GraphQL Voyager s’avère très utile pour rapidement identifier les zones d’intérêt à investiguer.
Postman est un outil initialement conçu pour développer et tester les APIs. Son utilisation durant un audit peut se révéler être un précieux atout, facilitant ainsi la répétition des requêtes avec son interface intuitive.
Une fois le point d’entrée GraphQL configuré dans Postman, celui-ci va automatiquement effectuer une requête d’introspection et générer une documentation interactive de l’API. Tous les types, requêtes, mutations et souscriptions sont ainsi listés.
L’interface dédiée permet de construire et rejouer des requêtes en sélectionnant les champs et arguments voulus. Les variables peuvent également être définies simplement.
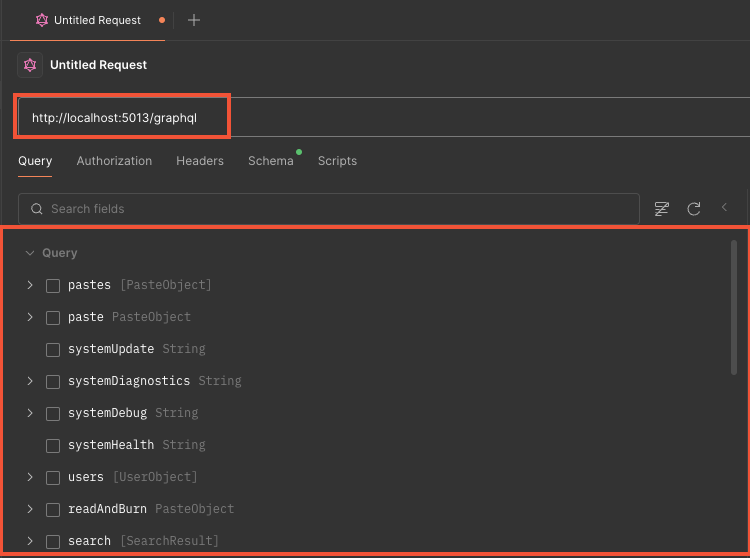
Le travail d’un auditeur peut ainsi être grandement simplifié en utilisant cet outil pour un pentest d’API.
InQL, qui est une extension du proxy Burp Suite est spécialement conçu pour tester des APIs GraphQL. En termes de fonctionnalités, il est similaire à Postman. On peut l’installer à partir du BApp Store de Burp, rubrique Extensions.
Il est possible d’effectuer une requête d’introspection pour récupérer le schéma de deux manières différentes.
La première, directement depuis une requête GraphQL :
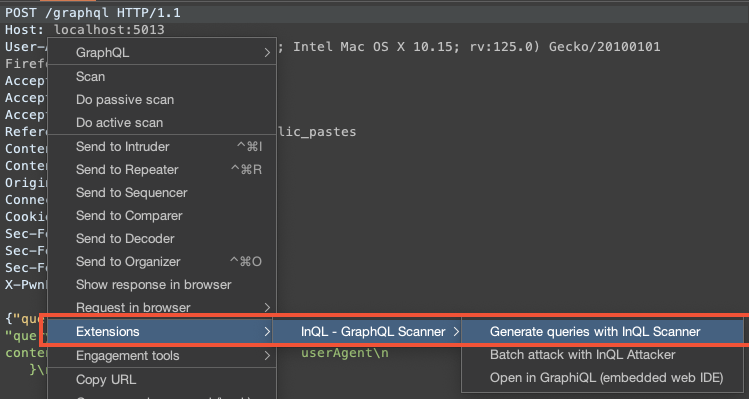
Et la deuxième, depuis l’onglet InQL :
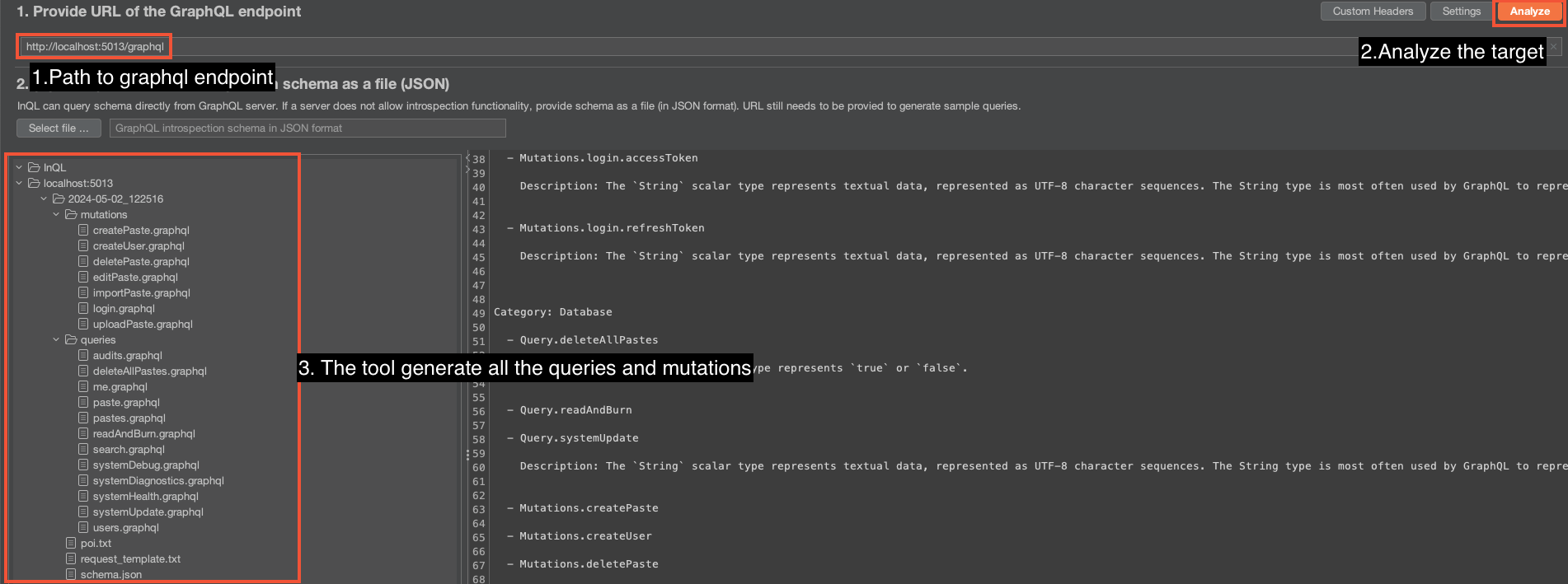
Quelle que soit la méthode utilisée, nous pourrons ensuite accéder à la liste des queries et mutations depuis l’interface de l’extension. Elle liste les paramètres requis ainsi que les champs disponibles.
Nous pouvons ensuite directement envoyer ces requêtes dans le panel Repeater, afin d’effectuer nos tests sur les routes choisies.
Le prochain outil que nous allons décrire, Graphql-cop permet de lister les principales vulnérabilités susceptibles d’être présentes sur une API GraphQL. C’est un outil open source disponible sur github. A noter cependant qu’il n’est plus maintenu depuis 2022.
Son utilisation est très simple :
Ainsi, en précisant uniquement l’URL de notre cible, l’outil va tenter de retrouver des chemins graphql par défaut. A noter que la liste de ses chemins est très limitée :

Il est donc préférable de ne pas se reposer sur cet outil pour trouver l’endpoint graphql.
Une série de tests vont ensuite être effectués, incluant :
Et encore bien d’autres.
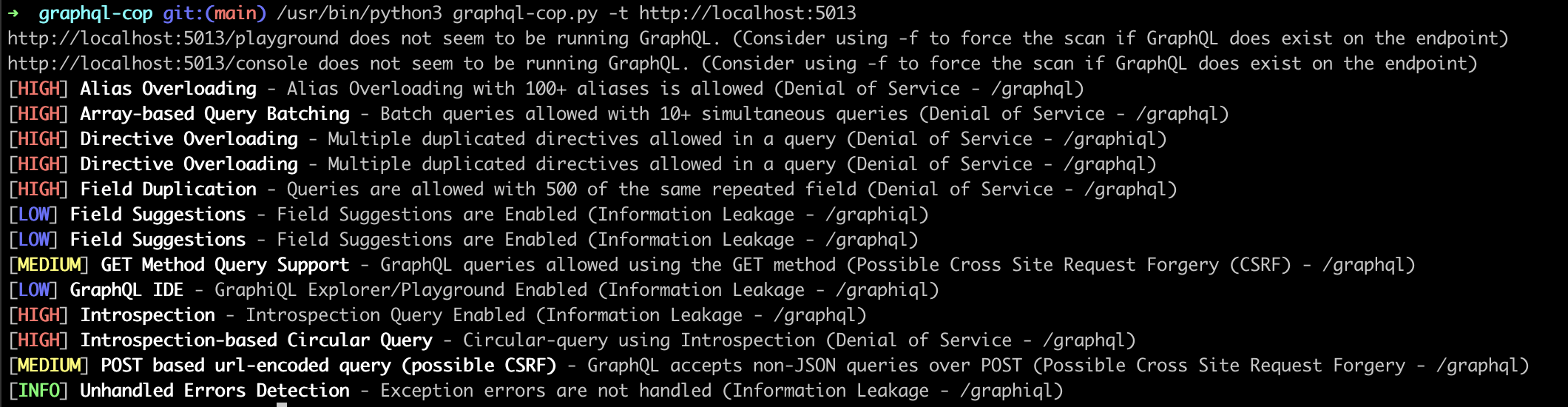
Une fois terminé, on peut observer la liste des vulnérabilités auxquelles notre cible est vulnérable.
Le dernier outil dont nous allons discuter ici est graphw00f. Comme mentionné précédemment, GraphQL n’a pas d’implémentation propre et nécessite un moteur d’exécution (engine) pour fonctionner.
C’est dans ce contexte que l’outil graphw00f entre en jeu. Il fonctionne en envoyant des requêtes GraphQL spécialement conçues à l’API et sera capable d’identifier le moteur grâce à des signatures uniques présentes dans les erreurs renvoyées ou dans les métadonnées.
A partir de là, on peut ensuite se référer à ce tableau qui identifie les potentielles vulnérabilités en fonction de l’implémentation :
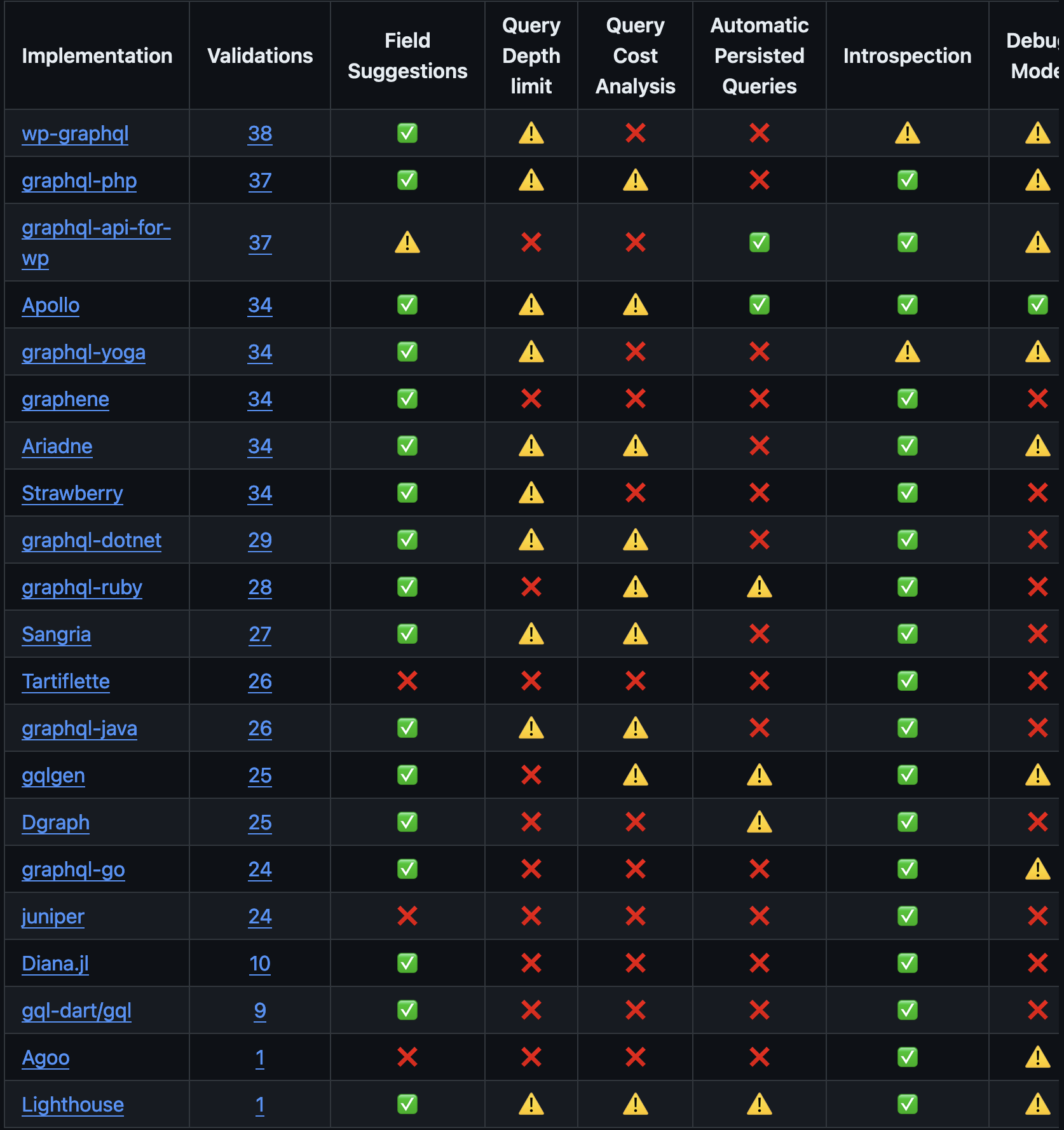
Comme évoqué avec graphql-cop, la liste d’endpoint pour trouver le chemin reste limitée :
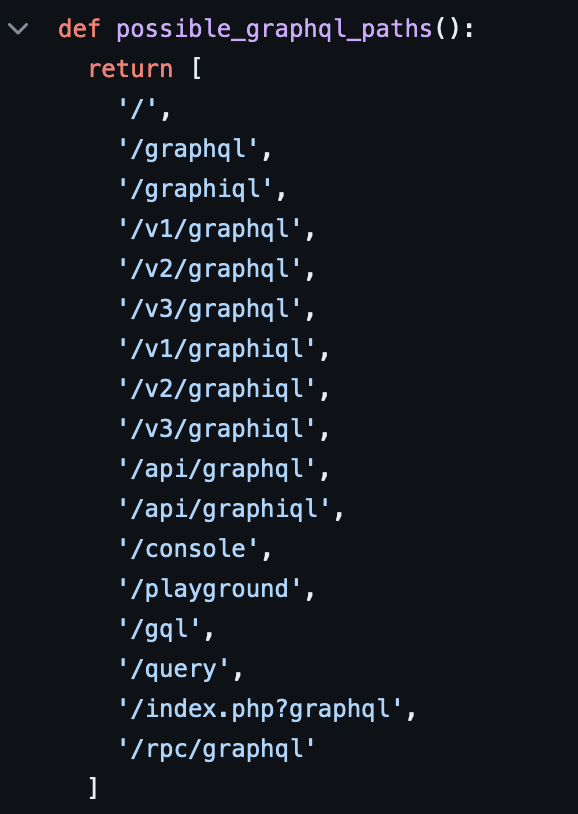
Il est ainsi préférable de l’identifier avant de l’utiliser, ou de préciser une wordlist custom à utiliser en utilisant le flag -w. On utilisera -t pour préciser l’URL de notre cible, et nous obtiendrons un output de ce genre en cas d’identification réussie :
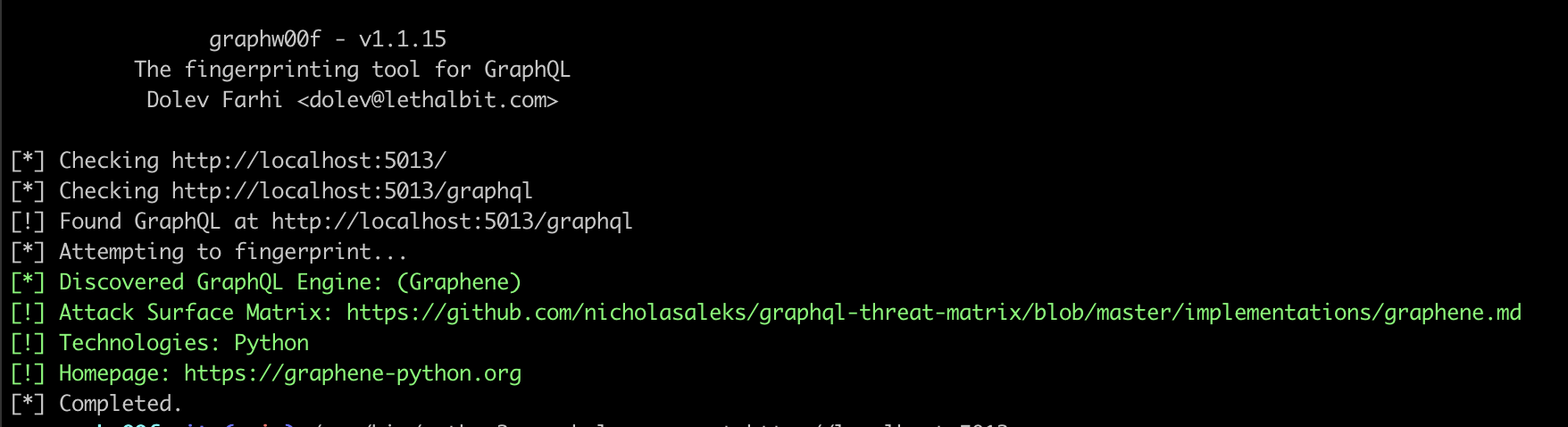
Sur cet exemple, le moteur Graphene à été identifié.
Arrivé à ce niveau, l’énumération de notre cible est terminée, et il faut maintenant passer à la phase de tests des routes disponibles. De multiples tests sont effectués durant nos audits, nous ne les présenterons pas tous ici, mais nous allons en découvrir certains pour mieux comprendre leur fonctionnement.
Certains de ces tests seront directement liés à l’architecture et au fonctionnement de GraphQL, les autres concerneront les APIs en général.
Les attaques de déni de service (Denial of Service) visent à surcharger le serveur ciblé, dans le but de le rendre beaucoup plus lent voire inaccessible durant le temps de l’attaque.
Cela à un fort impact pour l’experience des autres utilisateurs, les empêchant ainsi de l’utiliser, et atteignant aussi l’image de l’entreprise.
Les APIs GraphQL peuvent être particulièrement vulnérables à ce type d’attaque si il n’y a pas de limite à la profondeur des querys.
Pour se le représenter, prenons l’image suivante :
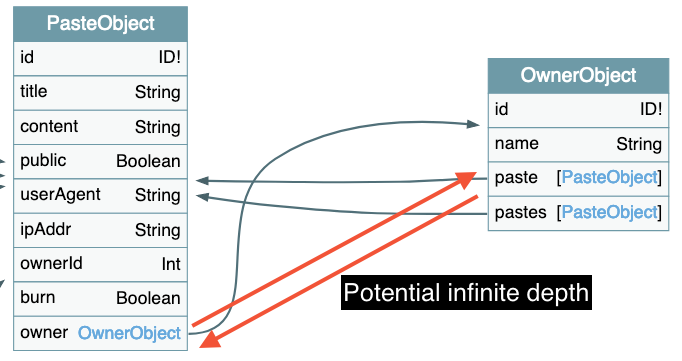
Lorsque nous effectuons une requête getPaste référençant un owner, référençant lui même des pastes, et ainsi de suite, cette requête peut devenir extrêmement lourde pour le serveur. Une telle structure risque de compromettre le bon fonctionnement de l’application.
Le nombre d’objets que le serveur va renvoyer est exponentielle avec le niveau de profondeur, ce qui provoque la surcharge.
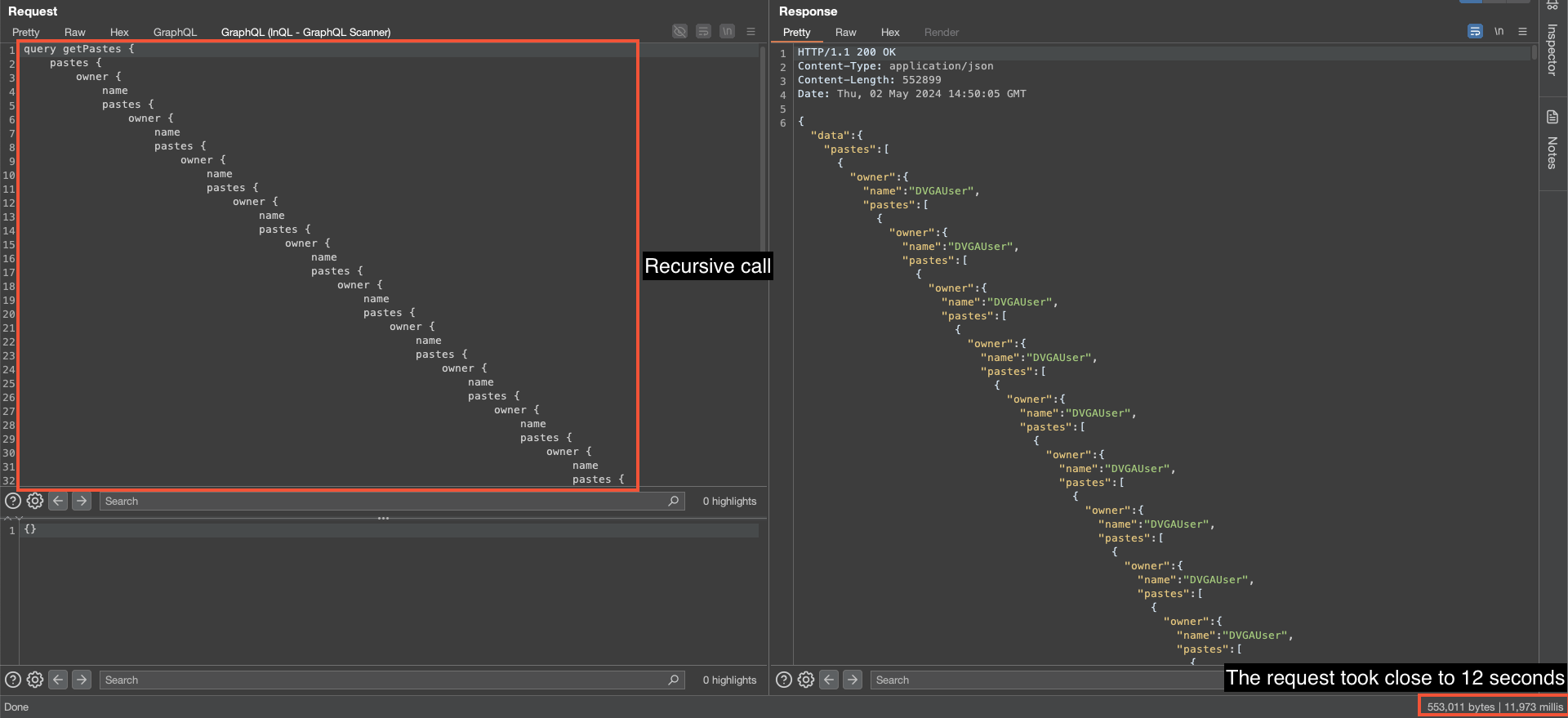
On peut s’apercevoir que le serveur à subi une surcharge momentanée, ce qui a conduit à obtenir une réponse extrêmement longue (presque 12 secondes). Durant ce laps de temps, le serveur était indisponible.
C’est dû au fait que cette requête était particulièrement exigeante en termes de ressources. Une query encore plus profonde aurait ainsi rendu indisponible le serveur pendant un laps de temps plus élevé, et aurait même pu provoquer l’arrêt complet.
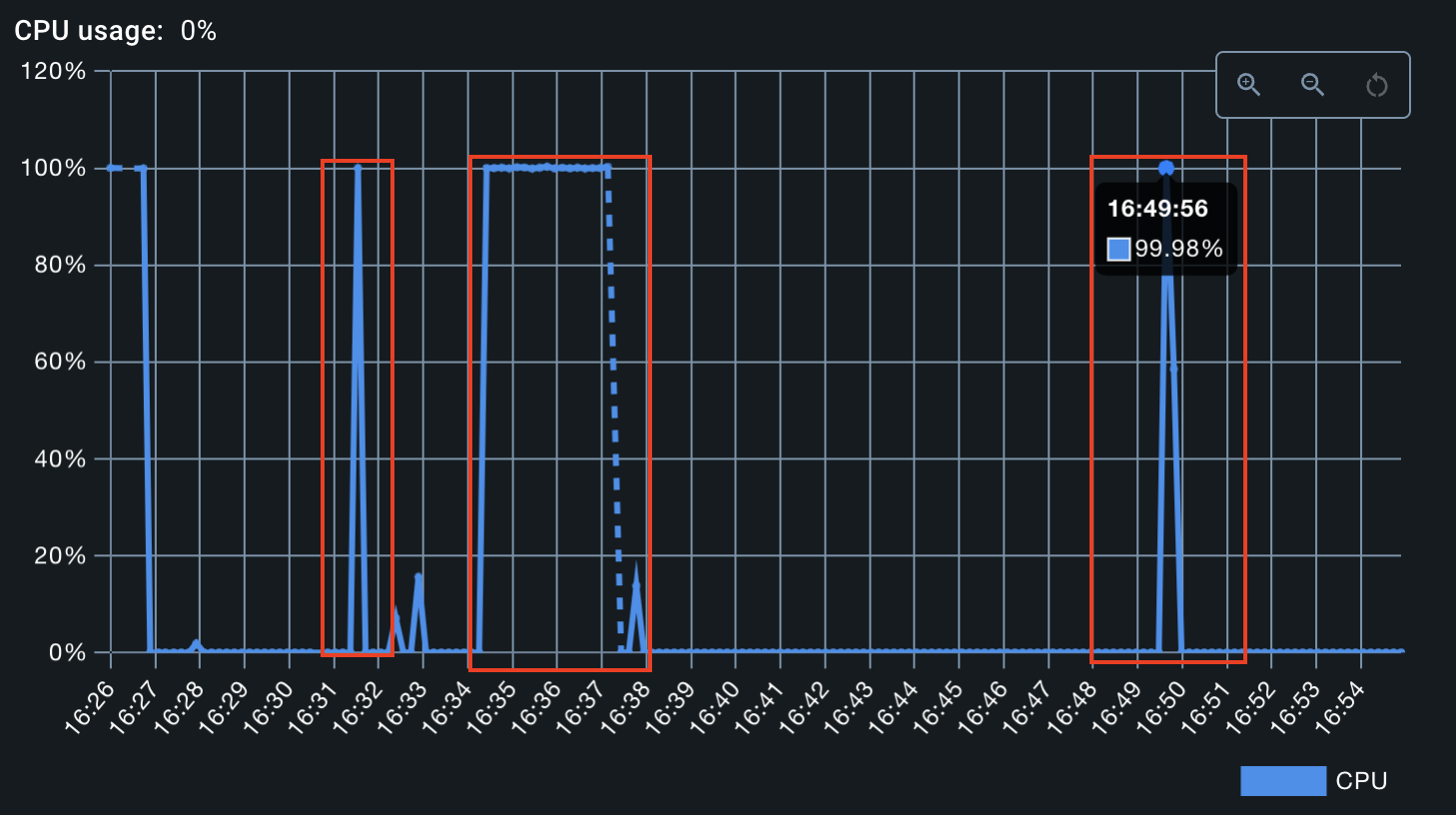
Il convient de garder à l’esprit que ces tests ont été effectués localement sur notre propre machine, ce qui explique l’impact significatif observé. En règle générale, les serveurs d’entreprise sont plus robustes et peuvent gérer plusieurs requêtes simultanées (en théorie).
Toutefois, envisageons un scénario où cette attaque serait lancée depuis plusieurs machines en même temps ; cela pourrait aboutir aux mêmes conséquences.
Les batched queries et les alias constituent une autre facette pouvant engendrer des vulnérabilités sur GraphQL. Bien que l’on puisse les considérer du point de vue du déni de service, nous allons, dans cet exemple, les utiliser dans un scénario d’attaque brute force.
Imaginons qu’un client ait mis en place une limite de requêtes HTTP sur un formulaire de connexion, autorisant uniquement l’envoi de 10 requêtes par seconde à partir de la même adresse IP. Cette mesure vise à contrer les attaques brute force sur le formulaire de connexion.
Si les batched queries ou les alias sont autorisés, cela ne suffira pas à stopper l’attaquant. En effet, celui-ci pourrait envoyer une multitude de requêtes dans une seule et même requête HTTP, contournant ainsi la limitation et réussissant son attaque.
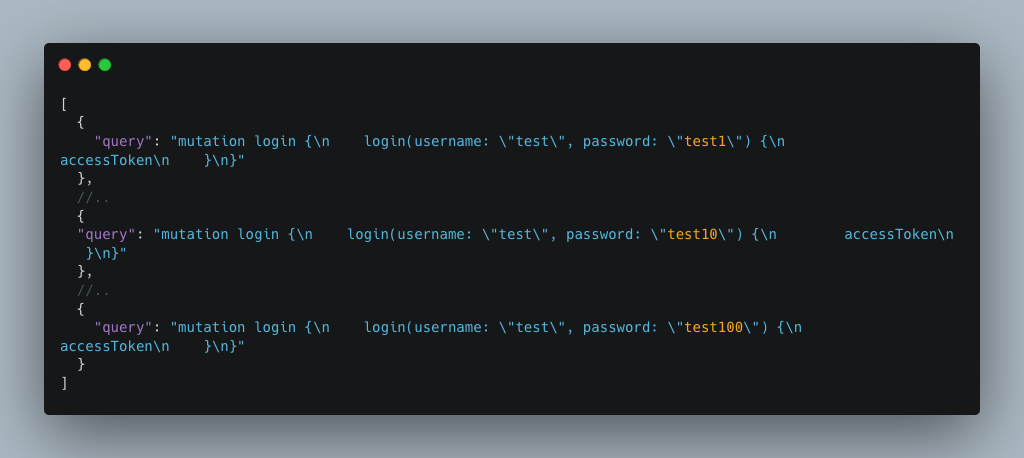
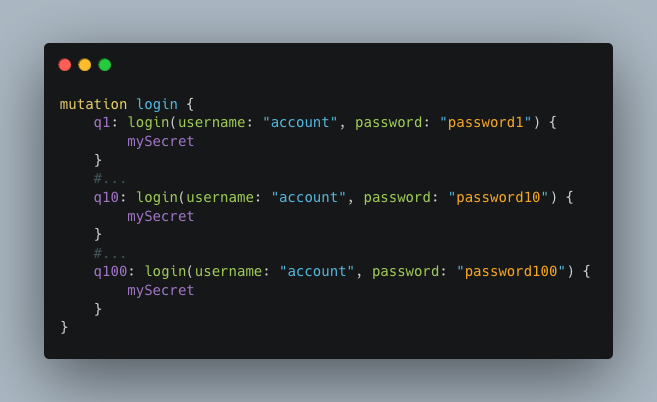
Cette méthode permet d’accélérer considérablement une attaque brute force. En envoyant 100 requêtes contenant chacune 100 alias ou batched queries, l’attaquant réalise déjà 10 000 tentatives d’authentification.
La multiplication des requêtes dans une seule demande HTTP augmente de manière exponentielle l’efficacité de l’attaque.
Il est courant d’utiliser des listes blanches (whitelist) ou des listes noires (blacklist) pour autoriser ou interdire les utilisateurs à effectuer des requêtes GraphQL. Cependant, cette approche peut être vulnérable si elle n’est pas correctement mise en œuvre.
Considérons une API GraphQL qui expose une requête systemHealth qui vérifie l’état du serveur. Cette requête nécessite une authentification en tant qu’administrateur. Sans un jeton d’authentification valide, la requête est rejetée, ce qui est un comportement attendu.
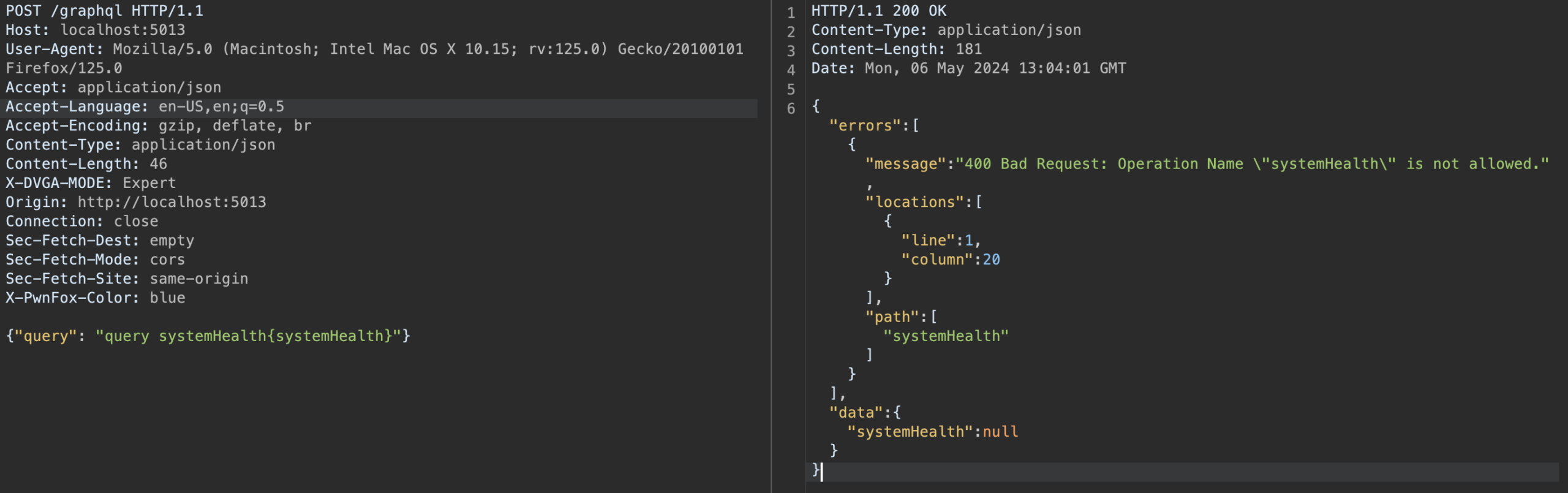
Cependant, il est possible de contourner cette restriction en utilisant un nom d’opération autorisé sans jeton d’authentification, tout en requêtant le champ systemHealth qui devrait être protégé.
Par exemple, supposons qu’un utilisateur non authentifié soit autorisé à exécuter une requête getPastes. Un attaquant pourrait alors envoyer la requête suivante :
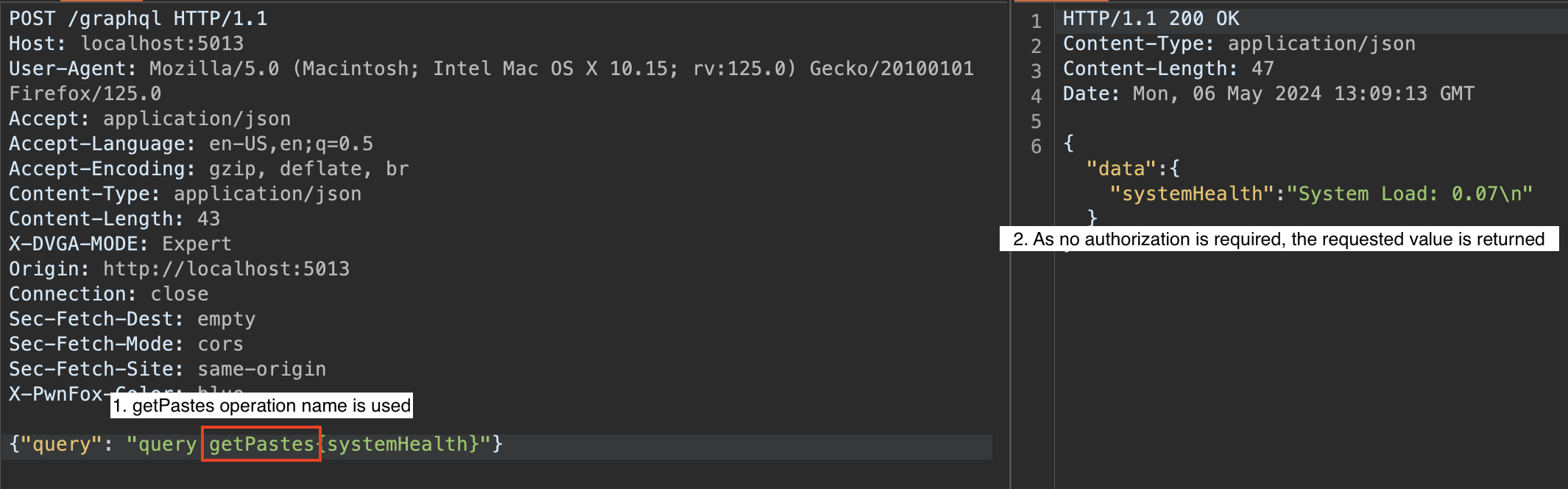
La problème présenté ici est que le nom d’opération demandé est soumis à un contrôle d’autorisation, la ressource demandée ne l’est pas.
Dans cette requête, le nom d’opération getPastes est autorisé pour un utilisateur non authentifié. Cependant, l’attaquant a également inclus le champ systemHealth, auquel il ne devrait pas avoir accès.
Le problème ici est que le contrôle d’autorisation est effectué uniquement sur le nom d’opération tandis que les ressources demandées ne sont pas vérifiées individuellement.
Bien que GraphQL introduise des vulnérabilité spécifiques, il ne faut pas perdre de vue qu’une API GraphQL reste fondamentalement une API web.
À ce titre, elle peut être exposée aux mêmes types de vulnérabilités que les autres types d’APIs. Nous allons passer en revue 3 vulnérabilités susceptibles d’être rencontrées durant un audit.
Une faille de type Cross-Site Scripting (XSS) stockée peut avoir des conséquences graves. Elle permet à un attaquant d’injecter du code JavaScript malveillant qui sera stocké côté serveur, généralement dans une base de données. Ce code malveillant sera ensuite exécuté dans le navigateur de tout utilisateur où la valeur malveillante sera reflétée.
Les conséquences peuvent êtres multiples, allant d’un défacing de la page web jusqu’au vol de compte d’utilisateurs.
Pour en savoir plus sur les failles XSS, nous vous renvoyons vers notre article : Failles XSS (Cross-site Scripting) : principes, types d’attaques, exploitations et bonnes pratiques sécurité.
Prenons l’exemple d’une plateforme de forum où les utilisateurs peuvent publier des messages. Ces messages sont ensuite repris et affichés sur les pages publiques de l’application web.
Ainsi, l’utilisation attendue de cette fonctionnalité ressemblerait à ça :
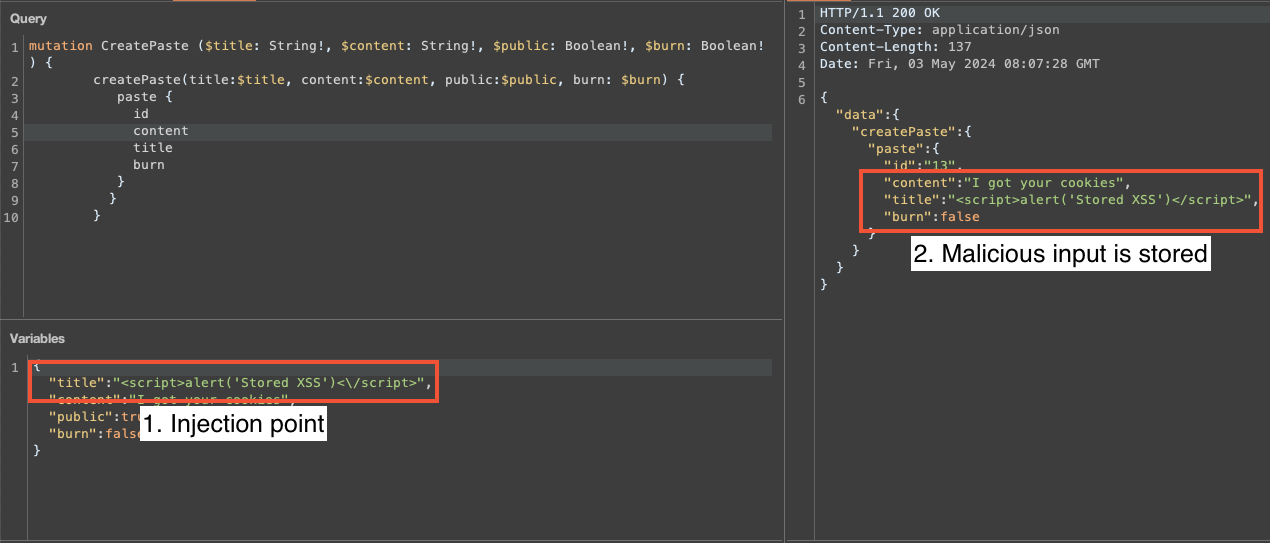
Ajoutons maintenant un utilisateur malveillant, qui décide de tester cette application et poste un message malveillant. On peut remarquer que le commentaire est envoyé en utilisant l’API, mais on voit qu’il est stocké sans avoir validé l’input de l’utilisateur.
Le contenu infecté est ensuite repris et affiché publiquement, sans encoder les caractères spéciaux, et ainsi le code Javascript est interprété puis exécuté, rendant vulnérable les utilisateurs légitimes du site:
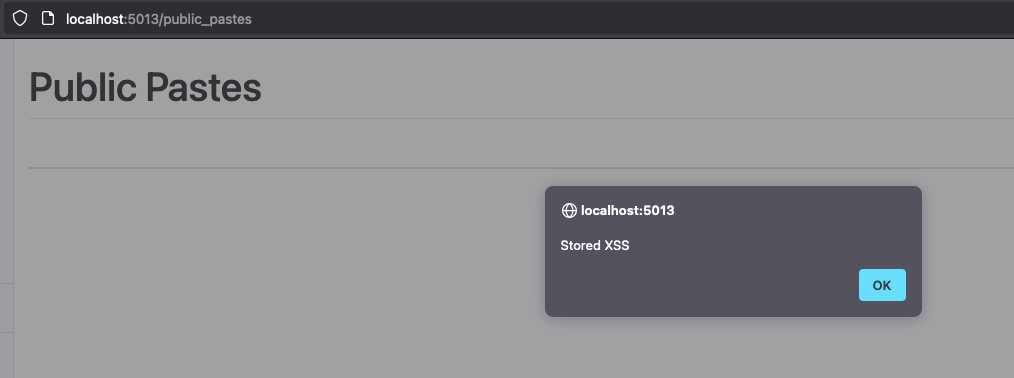
Un autre type de vulnérabilité que l’on peut rencontrer durant un pentest d’API est l’upload de fichier arbitraire combiné à un path traversal.
Si elle est correctement exécutée et que les conditions sont réunies, cette vulnérabilité peut avoir des conséquences désastreuses, en permettant d’écrire des fichiers malveillants sur le serveur.
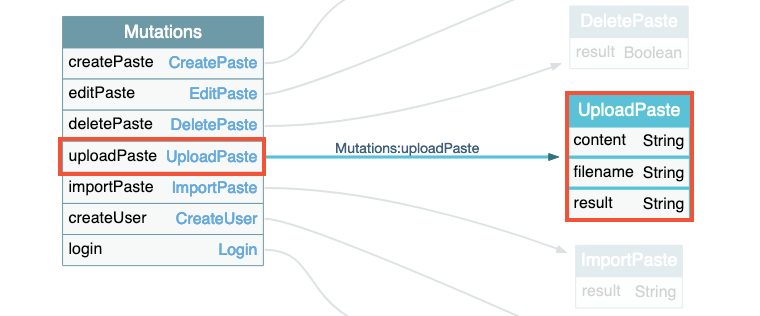
Nous avons découvert une mutation pendant notre exploration permettant d’uploader des fichiers sur le serveur. Cette mutation attend 2 champs en entrée, le nom du fichier ainsi que son contenu, et nous retournera le résultat.
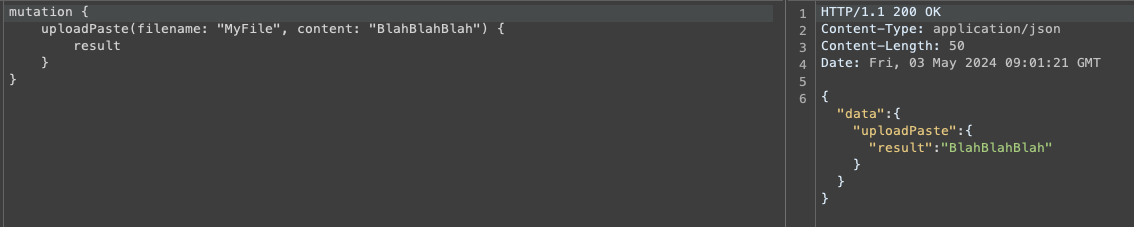
Un upload classique fonctionne de manière tout à fait normal, et une réponse est renvoyée avec le contenu du fichier qui à été upload.
En jetant un coup d’oeil à ce qu’il se passe du côté serveur, on peut observer que tout s’est bien passé, et on retrouve ce nouveau fichier à la location /opt/dvga/pastes :
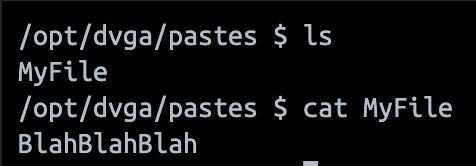
En modifiant le nom du fichier pour “../../../tmp/pwn”, la query fonctionne toujours mais on constate que le fichier n’est pas présent au chemin attendu. A la place, nous pouvons le retrouver dans le dossier /tmp.
En observant le code source responsable de l’enregistrement de notre fichier, on s’aperçoit qu’il n’y à aucun contrôle d’effectué sur le nom du fichier, expliquant ainsi sa présence dans l’autre dossier.
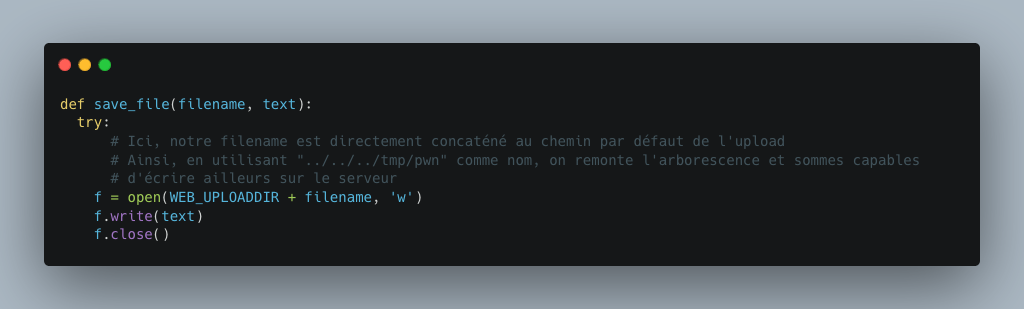
Une des vulnérabilités les plus critiques que l’on puisse trouver durant un pentest est l’exécution de commande sur un serveur distant ou RCE. Cela peut mener à bien des conséquences, incluant entre autres le vol de données, élévation de privilèges, mise en place d’une backdoor, etc.
Nous allons utiliser la mutation importPaste pour l’exploitation de cette vulnérabilité.
A l’origine, cette fonctionnalité est conçue pour importer des données depuis une URL entrée par l’utilisateur, pour l’enregistrer sur le serveur.
L’implémentation d’une telle fonctionnalité doit être particulièrement précautionneuse d’un point de vue sécurité, et c’est le genre de features auquel les auditeurs porterons un intérêt tout particulier.
Voici l’implémentation :
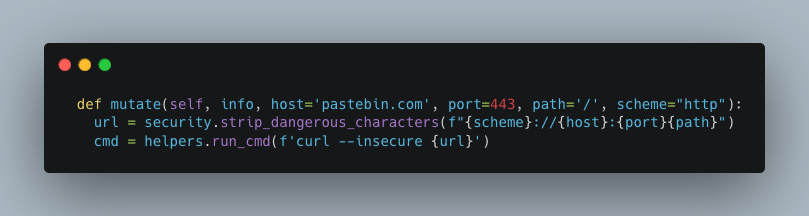
La mutation GraphQL correspondante attend différents paramètres, host, port, path et scheme. Ainsi, une requête ‘bien’ formée pourrait ressembler à ça:

Considérons maintenant qu’un utilisateur malveillant décide de ne pas se conformer à ce qui est attendu, et de remplacer ‘/’ dans le paramétre path par ‘/; sleep 10’.
Ainsi, la commande finale exécutée par le serveur deviendrait: “curl http://example.com:80/; sleep 10”, et les deux commandes seraient exécutée.
Si l’on observe du côté serveur, on confirme cette théorie.
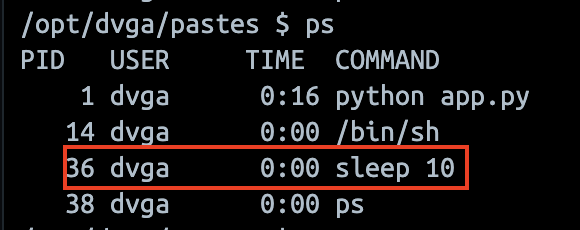
Un attaquant pourrait ainsi tenter d’élever ses privilèges, pivoter dans le réseau interne, interrompre le bon fonctionnement de l’application, etc.
Nous avons maintenant fait un tour d’horizon de GraphQL, de son fonctionnement et des principales vulnérabilités que l’on peut rencontrer lors d’un audit.
Comme nous avons pu le constater, GraphQL n’est pas à l’abri des vecteurs d’attaques impactant les APIs web traditionnelles, mais comporte aussi des vulnérabilités propres à son implémentation. Une sécurisation rigoureuse doit donc être mise en place.
Pour assurer une protection d’un point de vue global sur une API GraphQL, plusieurs protections peuvent être mise en place.
Par défaut, les implémentations GraphQL ont des configurations par défaut qui devraient être changées:
GraphQL est particulièrement vulnérable aux attaques de déni de service si la configuration est mal effectuée. Ce genre d’attaque impacter la disponibilité et la stabilité de l’API, la rendant plus lente voir même indisponible.
Voici quelques recommandations que l’on peut suivre pour se protéger de ce genre d’attaque:
Comme nous avons pu le voir précédemment, les attaques de batching peuvent être utilisée pour effectuer des attaque de bruteforce. Pour se défendre contre ce type d’attaque, il est nécessaire d’imposer des limites sur les requêtes entrantes:
Une solution peut être de créer une limite de requête concurrente au niveau du code sur le nombre d’objet qu’un utilisateur peut demander. Ainsi, si la limite est atteinte, les autres requêtes de l’utilisateur serait bloquées, même si elle étaient contenue dans la même requête HTTP.
Il est nécessaire de valider strictement l’input de l’utilisateur envoyé à l’API GraphQL. Cet input est souvent réutilisé dans de multiples contexte, que ce soit des requêtes HTTP, SQL ou autres. Si il est mal validé, cela pourrait mener à des vulnérabilités d’injection.
Pour valider l’input de l’utilisateur, on peut suivre ces quelques recommendations:
Sources :
Auteur : Théo ARCHIMBAUD – Pentester @Vaadata


