
La mauvaise configuration de sécurité est un problème préoccupant puisqu’il occupe la cinquième place du Top 10 de l’OWASP. En effet, nous rencontrons assez fréquemment de nombreuses vulnérabilités de ce type lors de nos tests d’intrusion d’application web. Par ailleurs, cette problématique sécurité toucherait un grand nombre d’applications web (90% selon l’OWASP).
Dans cet article, nous vous présentons ce type de failles à travers le prisme de l’OWASP Top 10, et ce via des scénarios d’attaques. Nous y détaillons également les bonnes pratiques et les mesures à mettre en œuvre pour s’en prémunir.
Quels sont les causes de mauvaises configurations de sécurité ?
Les vulnérabilités de type mauvaise configuration de sécurité sont souvent le résultat du manque de clarté de la documentation qui accompagne les outils et les plateformes utilisés pour développer des applications web.
En effet, les développeurs peuvent parfois mal interpréter les paramètres de sécurité ou ne pas comprendre pleinement les implications de leurs choix de configuration.
De plus, il arrive que certains produits aient une configuration par défaut vulnérable. Ainsi, les utilisateurs, par ignorance ou par négligence, peuvent ne pas modifier ces paramètres par défaut, ce qui laisse des failles de sécurité béantes dans leurs applications.
Pour mieux comprendre l’impact de la mauvaise configuration de sécurité, nous allons examiner deux exemples concrets. Ces exemples illustreront comment des erreurs de configuration peuvent potentiellement compromettre la sécurité des applications web et mettre en danger les données utilisateurs.
Exemples d’exploitations de mauvaises configurations de sécurité sur des applications web
Spring Boot Actuator
Lors d’un test d’intrusion en boite noire, nous avons identifié que l’application web cible utilisait le framework « Spring Boot« . Cette conclusion a été tirée notamment grâce à l’inspection du compte GitHub de l’entreprise, où nous avons remarqué que plusieurs projets étaient basés sur ce framework.
De fait, nous avons supposé qu’il était probable que les développeurs aient activé le module « Spring Boot Actuator, » qui est un sous projet du framework « Spring Boot ». Ce module offre la possibilité de surveiller et de gérer une application en exposant des endpoints HTTP spécifiques.
Cependant, ces endpoints exposés peuvent rapidement devenir critiques puisqu’ils permettent entre autres d’accéder aux fichiers de log, de faire des dumps mémoires, etc. Par ailleurs, dans les versions antérieures à la mise à jour 1.5, les endpoints sensibles de ce module sont accessibles sans nécessiter d’authentification par défaut. Et même si les versions ultérieures à la version 1.5 viennent sécuriser ces endpoints sensibles, il arrive tout de même que les développeurs désactivent cette sécurité.
Dans le cas de notre pentest, nous avons observé que la majorité des interactions avec l’application se faisaient via une API. Cette API peut constituer une cible clé puisqu’elle peut très bien faire l’objet d’un monitoring par les développeurs.
Brute force des endpoints de l’API et récupération des cookies utilisateurs
Notre objectif était de bruteforcer tous les endpoints de l’API avec une liste contenant les actuators Spring Boot.
Pour ce faire, nous avons élaboré une liste exhaustive de tous les endpoints de l’API en extrayant ces informations directement à partir des fichiers JavaScript de l’application.
Nous avons ensuite procédé au brute force de chacun de ces endpoints avec une liste contenant les « Actuators Spring Boot ».
Il existe plusieurs méthodes pour effectuer un brute force. Ici, nous avons utilisé l’attaque « Cluster Bomb » de l’outil Burp Suite.
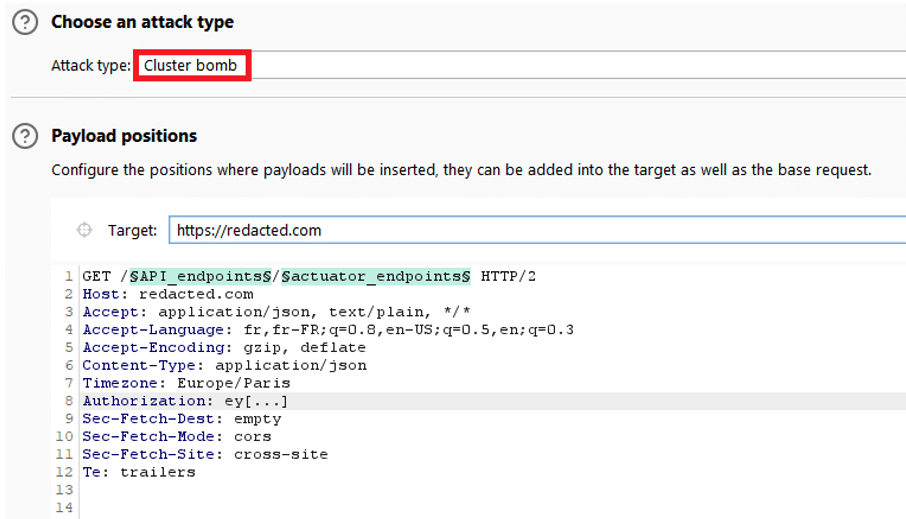
Généralement, plusieurs exploitations sont possibles. Lors de notre pentest, nous avons trouvé l’endpoint heapdump exposé.
Le heapdump est une copie de la mémoire du serveur à l’instant T.
À l’aboutissement de notre attaque, nous nous retrouvons avec l’endpoint « /heapdump » accessible sur un des endpoints de l’API . Cet Endpoint effectue une copie de la mémoire vive à un instant T.
Après avoir téléchargé le « heapdump » qui se présente sous la forme d’un fichier hprof.gz, on peut exploiter ces données à l’aide de VisualVM qui est un outil permettant d’interagir avec les données de notre fichier en ligne de commande.
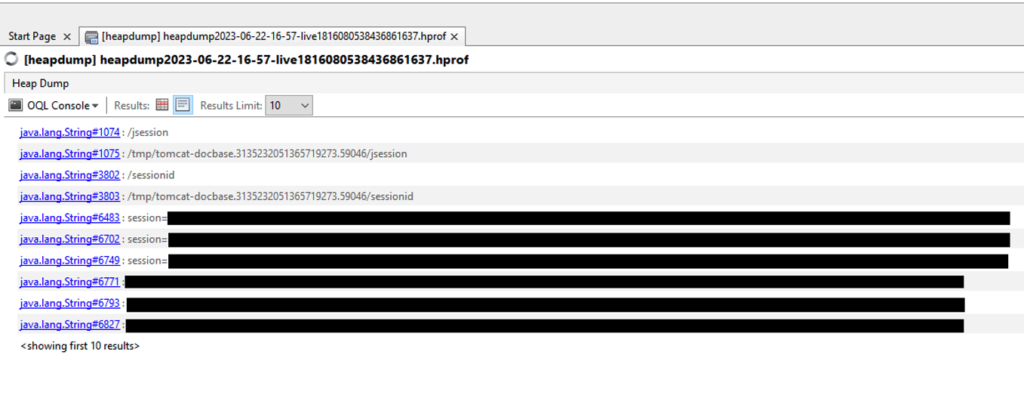
Le fichier étant assez large, nous avons donc ciblé les mots clés susceptibles de contenir les informations les plus critiques.
Dans notre cas, nous avons réussi à collecter les cookies de sessions de tous les utilisateurs.
Comment prévenir ce type d’exploitation ?
La documentation officielle Spring conseille de protéger les endpoints sensibles à l’aide du framework « spring security« , qui permet d’ajouter une authentification et un contrôle d’accès sur les différents endpoints.
Mauvaise configuration bucket S3
Amazon S3 (Simple Storage Service) est un service de stockage en ligne qui offre la possibilité de conserver divers types de données dans le cloud.
Pour mieux comprendre la terminologie propre à Amazon S3, il est important de noter que les données sont organisées et stockées en tant qu’objets à l’intérieur de conteneurs appelés « buckets ». Chaque objet est identifiable de manière unique grâce à une « object key », qui sert d’identifiant à l’intérieur d’un bucket.
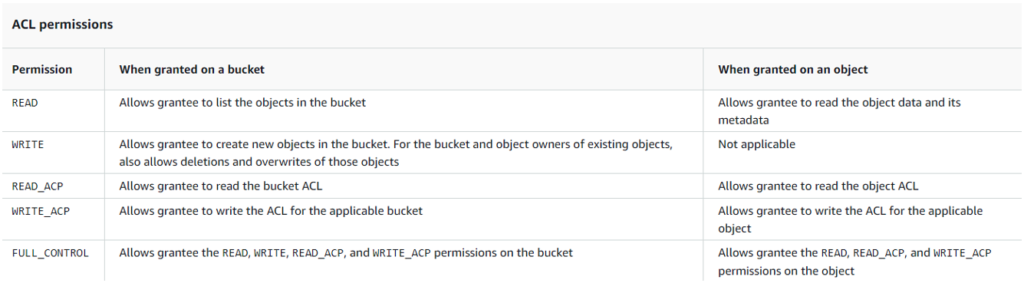
En ce qui concerne la sécurité des données stockées dans ces buckets, Amazon S3 propose plusieurs mécanismes pour la gestion des autorisations et des contrôles d’accès qui peuvent varier en fonction du contexte et des besoins spécifiques de l’application.
- Les « IAM policies » (Identity and Access Management policies) permettent de définir les droits d’accès des utilisateurs et des ressources pour l’ensemble des actions AWS.
- Les « S3 bucket policies » sont spécifiques aux buckets et offrent la possibilité d’ajouter des règles de contrôle d’accès au niveau du bucket lui-même. Ces politiques permettent de définir qui peut accéder au bucket et quelles actions il est possible d’effectuer.
- Les « S3 ACLs » ajoutent un niveau de granularité supplémentaire en permettant de définir des contrôles d’accès au niveau des objets à l’intérieur d’un bucket. Cela signifie qu’on peut spécifier des autorisations différentes pour chaque objet, en plus des contrôles d’accès définis au niveau du bucket.
Exploitation défaut de contrôle d’accès
Lors d’un pentest en boite grise, nous avons identifié, en inspectant le code source HTML de l’application, qu’un Bucket S3 était utilisé pour stocker les ressources associées à notre compte.
Généralement, L’URL d’un Bucket S3 suit le format standard : « https://nom_bucket.s3-region-.amazonaws.com/ », ou « nom_bucket » est le nom unique du Bucket, et « region » indique la région géographique dans laquelle le Bucket est situé.
Et lorsqu’on tombe sur des Bucket Amazon, on teste systématiquement les droits d’accès afin de voir s’ils sont trop permissifs. La documentation Amazon est assez claire et nous indique toutes les permissions qu’il est possible d’accorder.
Pour tester ces permissions, on utilise l’interface de ligne de commande Amazon. À noter qu’il est nécessaire d’avoir ajouté les clés d’API Amazon dans les fichiers de configuration du CLI.
On effectuera toutes nos requêtes en étant anonyme à l’aide de l’option « –no-sign-request ».
L’accès en lecture permet de faire le listing de tous les objets du bucket.
aws s3 ls s3://nom_bucket --no-sign-requestL’accès en écriture permet de créer, de supprimer et de modifier les objets du bucket.
aws s3 cp fichier.txt s3://nom_bucket/fichier.txt --no-sign-requestLa permission « READ_ACP » permet de lire les ACL du bucket.
aws s3api get-bucket-acl --bucket nom_bucket --no-sign-requestDe la même manière, la permission « WRITE_ACP » permet d’écrire des ACL sur le bucket.
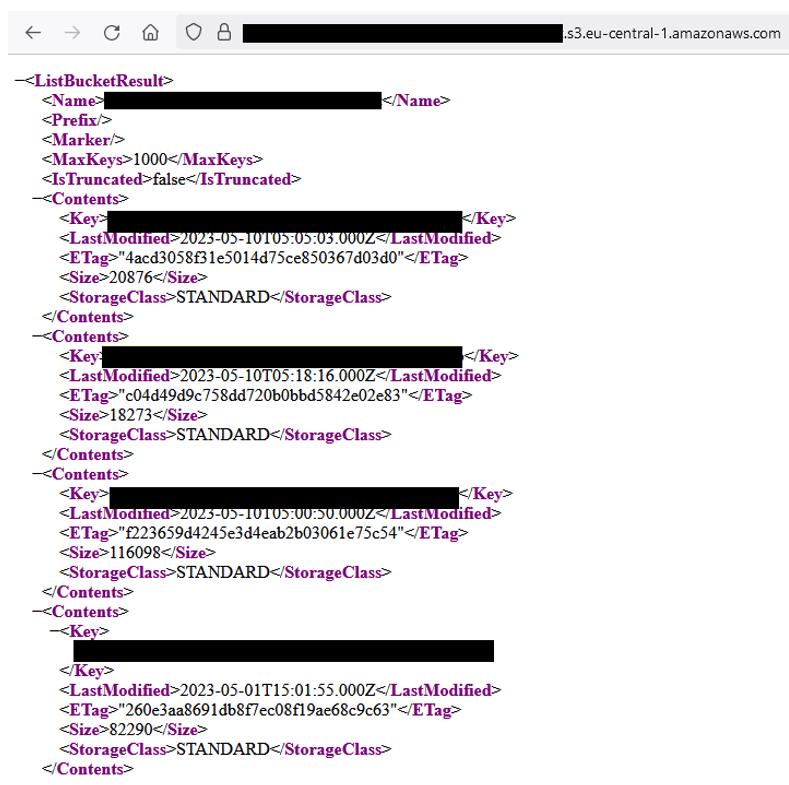
aws s3api put-bucket-acl --bucket nom_bucket --access-control-policy file://acl.json --no-sign-requestDans le cas de notre pentest, nous avions l’accès en lecture anonyme activé, ce qui nous a permis de lister tous les « object-keys ». Les objets n’étant pas présignés, nous avions accès à tous les fichiers stockés dans le bucket.
L’impact de ce problème de configuration est lié aux données stockées sur le bucket. Dans notre cas, le bucket était utilisé pour stocker des données sensibles d’utilisateurs.
Comment corriger les problèmes de droits ?
Afin de corriger les problèmes de droits, il faut cloisonner les permissions du bucket afin que tous les utilisateurs externes ne puissent plus avoir accès aux ressources.
Cela passe par :
- La suppression de l’accès anonyme en lecture et en écriture au bucket
- La suppression de l’accès anonyme en lecture et en écriture aux ACL (permission read_acp / write_acp)
- L’utilisation d’URLs présignées
Auteur : Yacine DJABER – Pentester @Vaadata