
Souvent, lorsque nous entendons parler de la sérialisation Java, nous trouvons des ressources ou des challenges qui parlent uniquement de générer et d’exécuter des payloads ysoserial.
Dans certaines situations, cela peut fonctionner. Cependant, dès qu’un client est conscient de cette possibilité, plutôt que de recourir à un format plus sûr, il préfère généralement utiliser à une bibliothèque comme notsoserial qui empêche la désérialisation des classes non autorisées.
Et si l’on bloque l’utilisation de classes intéressantes, nous sommes alors coincés avec une API classique qui utilise des objets sérialisés Java plutôt qu’un format plus répandu tel que JSON.
Cela signifie que nous pouvons effectuer des tests comme nous le ferions avec une API normale, n’est-ce pas ? Techniquement, oui, mais la tâche n’est pas simple. Les objets JSON peuvent être réécrits par des humains et nous pouvons également les lire facilement, ce qui n’est pas le cas des objets sérialisés Java puisqu’ils sont sous format binaire.
Lors d’un pentest d’application web, nous avons été amenés à analyser un objet sérialisé. Pour ce faire, nous avons opté pour l’utilisation d’outils tels que SerializationDumper afin de transformer le flux dans un format verbeux et plus lisible.
Maintenant que nous pouvons analyser les données, nous y trouverons peut-être une chaîne de caractères intéressante. L’outil nous permet également de reconstruire le flux à partir du format lisible, ce qui signifie que nous pouvons patcher des valeurs à l’intérieur, c’est génial non ?
Oui… mais pas vraiment. En effet, si une application utilise peu de messages sérialisés, il est possible de faire ce processus manuellement malgré le temps nécessaire, parfois long, pour extraire le flux sérialisé, exécuter les outils dessus, reconstruire le flux et l’insérer à nouveau dans une requête. Cependant, lorsque l’application les utilise pour chaque message, cela devient très chronophage.
Pour faciliter notre travail, la première étape est l’automatisation. Nous avons commencé par créer une extension Burp qui intègre une version modifiée de SerializationDumper. La version modifiée est intéressante car elle peut être utilisée comme une bibliothèque, ce qui évite d’avoir à écrire un wrapper autour d’un programme que nous devons appeler à chaque fois que nous voulons faire quelque chose.
Malheureusement, la version modifiée ne semble pas supporter la reconstruction des flux Java et, même si nous l’implémentons, nous pensons que le format est encore trop verbeux pour que nous puissions travailler avec. Nous avons donc décidé de tout redévelopper en tenant compte de ces préoccupations.
Nous sommes heureux d’annoncer la sortie d’un de nos outils interne : Java Serde.
Cet outil est utilisé lorsque nous devons interagir avec des objets Java sérialisés car il les rend plus faciles à manipuler. L’idée est de convertir un flux d’objets en un document JSON et vice versa. Cela permet d’identifier plus facilement la forme des objets mais aussi de faciliter le forgeage de nouveaux objets.
Nous avons choisi d’utiliser JSON plutôt qu’un format personnalisé lisible par l’homme parce qu’il s’intègre bien à de nombreux outils déjà existants utilisés pour manipuler les documents JSON.
Pour illustrer le fonctionnement de notre outil, nous prendrons quelques exemples tirés de ressources en ligne, y compris les challenges de PortSwigger que nous risquons de dévoiler un peu. Pour éviter tout spoil, nous vous recommandons de les faire d’abord de votre côté.
Lors de l’authentification sur un challenge de PortSwigger, nous recevons un cookie de session qui contient un flux Java encodé en Base64.

Si nous décodons le cookie, nous obtenons un flux Java brut qui n’est pas facile à manipuler. Nous ne pouvons pas modifier facilement la longueur des chaînes de caractères et nous avons peu d’informations sur la forme de l’objet.
Mais avec notre outil, nous pouvons transformer le binaire en un document JSON.
$ echo "rO0A[…]cg==" | base64 -d | java -jar java-serde.jar decode
[
{
"@handle": 8257538,
"@class": {
"@handle": 8257536,
"@name": "lab.actions.common.serializable.AccessTokenUser",
"@serial": 1824517384844061057,
"@flags": 2,
"@fields": [
{
"@name": "accessToken",
"@type": "Ljava/lang/String;"
},
{
"@name": "username",
"@type": "Ljava/lang/String;"
}
],
"@annotations": [],
"@super": null
},
"@data": [
{
"@values": [
"fi9b2c76gn4pix5wfxadcxp2lbv6j35j",
"wiener"
],
"@annotations": []
}
]
}
]Comme nous pouvons le voir, il y a beaucoup de données mais nous avons au moins un JSON. L’idée est de garder beaucoup d’informations sur le flux original pour faciliter sa reconstruction, mais cela le rend plus verbeux.
Le premier champ que nous pouvons voir est « handle ». Il s’agit d’un numéro attribué aux éléments qui peuvent être référencés plus tard dans le flux. Lorsque vous les éditez, vous pouvez sélectionner n’importe quel numéro, notre programme se chargera d’utiliser le bon lors de l’écriture du flux.
Puis, nous pouvons facilement identifier qu’il y a une classe nommée « AccessTokenUser » et ses champs, « username » et « accessToken », qui sont tous deux des chaînes de caractères.
Enfin, nous pouvons voir les valeurs de chaque champ dans l’ordre où ils sont déclarés dans la description de la classe (c’est une chose qui pourrait changer dans le futur, avec un objet clé-valeur pour rendre les choses plus faciles à lire et à écrire).
Malheureusement, le challenge ne nous demande pas de modifier l’objet (comme changer le nom d’utilisateur).
Imaginez que vous jouez à un jeu trouvé sur GitHub qui utilise des objets Java pour son format de sauvegarde et que vous n’êtes pas très patient ou bon au jeu.
Vous pouvez modifier le fichier de sauvegarde pour qu’il vous donne ce que vous voulez.
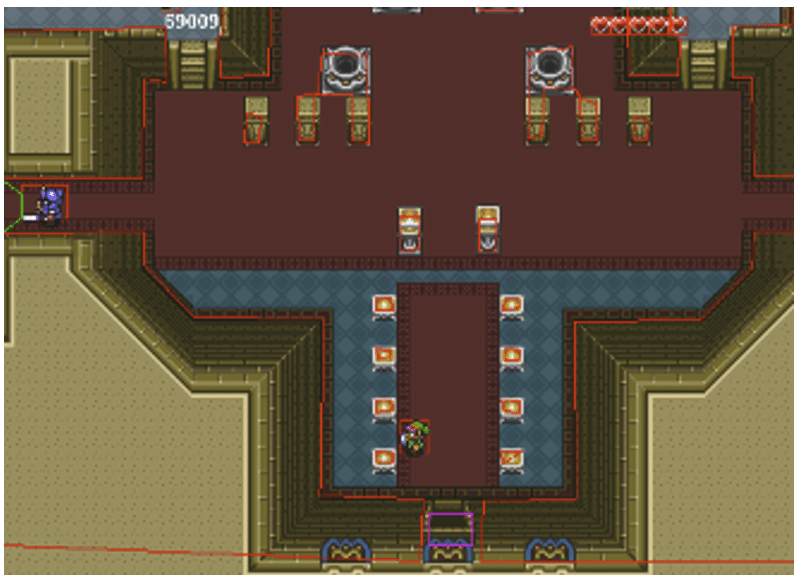
Nous avons trouvé un petit jeu sur GitHub : un RPG inspiré de Zelda.
Lorsqu’on lance le jeu, on voit notre personnage, nos points de vie et notre argent (on voit aussi chaque hitbox, mais c’est un détail). Après avoir frappé quelques ennemis, il ne nous reste que 2 cœurs et nous avons trouvé 5 rubis.

Nous pouvons maintenant utiliser notre programme pour modifier notre fichier de sauvegarde afin de rétablir notre santé et obtenir un peu d’argent de poche.
$ cat Zelda.ser | java -jar java-serde.jar decode
[
{
"@handle": 8257538,
"@class": {
"@handle": 8257536,
"@name": "zelda.engine.SaveData",
"@serial": 40658369698633593,
"@flags": 2,
"@fields": [
{
"@name": "health",
"@type": "I"
},
{
"@name": "rupee",
"@type": "I"
},
{
"@name": "sceneName",
"@type": "Ljava/lang/String;"
}
],
"@annotations": [],
"@super": null
},
"@data": [
{
"@values": [
2,
5,
"ForrestScene"
],
"@annotations": []
}
]
}
]Nous pouvons voir ici que le format de sauvegarde est simple avec uniquement trois informations spécifiques sur le jeu : la santé du joueur, les rubis, et sa position.
Il est possible d’utiliser la commande jq pour modifier le JSON facilement.
$ cat Zelda.ser | java -jar java-serde.jar decode | jq '.[0]."@data"[0]."@values" = [5, 69009, "CastleScene"]' > Zelda.json
$ cat Zelda.json | java -jar java-serde.jar encode > Zelda.ser
Ensuite, si nous redémarrons le jeu, nous pouvons voir nos modifications.
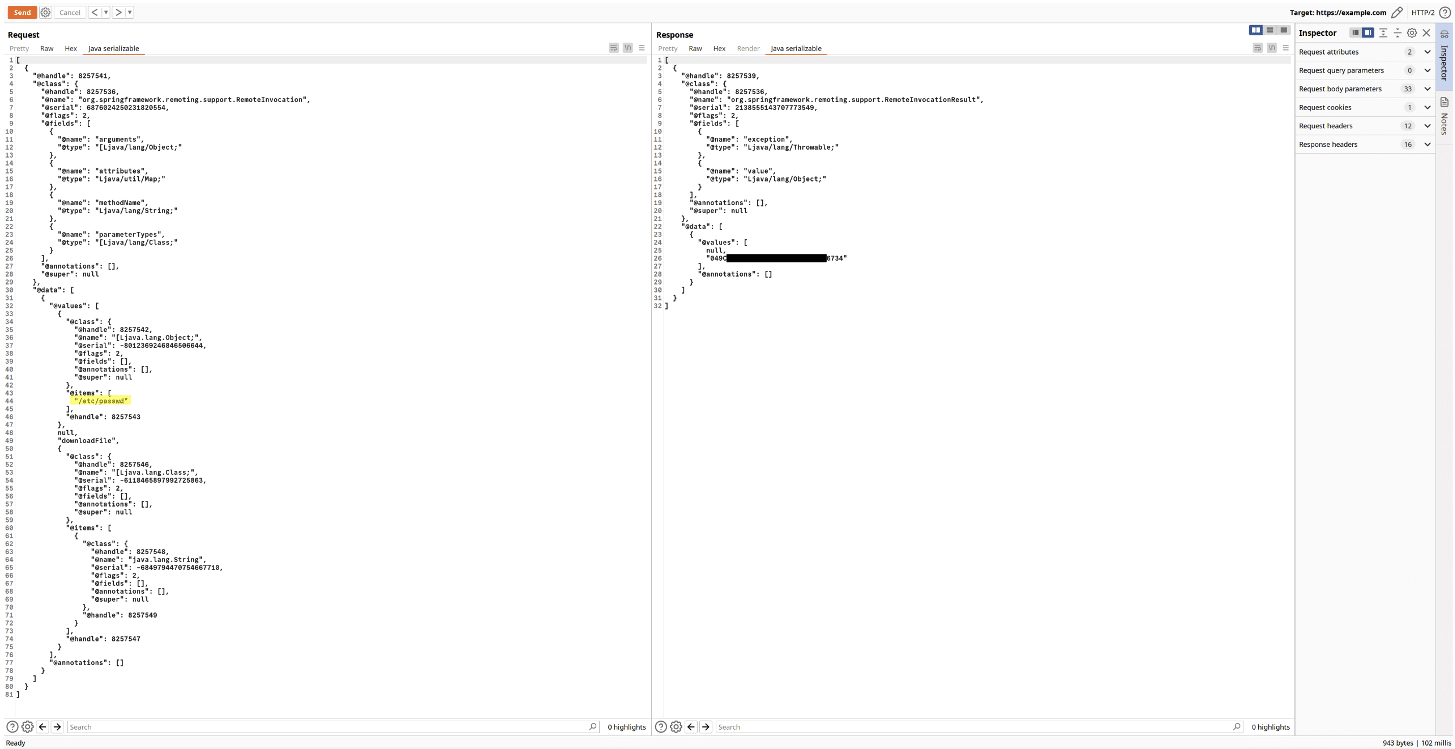
Lors d’un pentest web, nous avons testé une application web et un client riche, tous deux écrits en Java. Pour chaque message envoyé entre ces deux applications, un objet sérialisé Java était également envoyé.
Au cours de nos tests, nous avons découvert une requête intéressante adressée au serveur. Le client envoyait un chemin et le serveur répondait avec un jeton qui pouvait être utilisé pour télécharger le fichier au chemin donné.
En utilisant notre programme comme une extension Burp, il a été possible de patcher facilement le flux dans la requête et d’extraire le jeton de la réponse.
Le développement de l’extension nous a permis d’identifier encore plus de vulnérabilités et d’être plus efficaces pour les exploiter.
Comme nous avons écrit le programme pour un cas d’utilisation spécifique, certaines parties de la spécification ne sont pas implémentées et pourront l’être à l’avenir si nous rencontrons ce cas.
L’extension Burp exige également que le flux se trouve à un endroit spécifique et avec un encodage spécifique, vous pouvez toujours patcher le code pour extraire les données du bon endroit.
Par exemple, il n’est pas possible de représenter la même chaîne de caractères dans un flux avec deux handles différents ; dans notre programme, nous fusionnons ces références. Cela peut créer des différences inattendues lors du réencodage d’un flux.
Quoi qu’il en soit, nous trouvons parfois des vulnérabilités de base qui sont difficiles à exploiter parce que nous ne pouvons pas manipuler les données facilement, et pour qu’elles soient corrigées, nous devons démontrer la vulnérabilité. Nous espérons que cette extension permettra à d’autres pentesters de démontrer plus facilement les problèmes.
Auteur : Arnaud PASCAL – Pentester @Vaadata


