
In the development cycle of a web application, security should never be relegated to the background.
It must be considered at every stage: from the design phase, when choosing the architecture, throughout development, but also after deployment, through continuous testing.
Among the various approaches to assessing the security of an application, source code auditing plays a key role. Unlike black-box or grey-box penetration testing, this method allows you to delve into the inner workings of the application, understand its mechanisms and identify flaws that are sometimes invisible on the surface.
In this article, we will explore the principles and objectives of a web application source code audit. We will also detail a source code audit method based on the analysis of ‘sources’ and ‘sinks’, security implementations, dependencies, etc. Finally, we will present concrete examples of vulnerabilities that can be identified in the source code in order to better understand how this methodology can be applied.
Comprehensive Guide to Source Code Audit Methodology
What is a Source Code Audit?
Source code auditing is a process of in-depth analysis of an application’s code to identify security flaws, logic errors and poor development practices.
This analysis is based on a mixed approach combining automated tools and the expertise of security consultants. The tools scan the entire code to detect known vulnerabilities. However, they are often limited. This is why human intervention remains essential. Through targeted reading and a detailed understanding of the context, a pentester is able to identify complex flaws specific to the application, which are often undetectable by tools.
With this in mind, collaboration with developers is essential. Their knowledge of the architecture and functionalities allows them to guide auditors towards critical components, particularly those that handle sensitive data, interact with the file system, execute commands or make requests to other services.
It is also important to pay particular attention to functionalities that are considered complex, poorly documented or potentially problematic in their implementation. To effectively guide this analysis, access to detailed technical documentation or application architecture mapping is a real asset. This provides a better understanding of data flows, user entry points, and interactions between modules, thereby enabling the most likely attack vectors to be anticipated.
Following this preparatory phase, code analysis can begin.
Source Code Audit Through Analysis of Sources and Sinks
A source code audit does not mean examining every line one by one. Such an approach would be inefficient, time-consuming and counterproductive. The challenge is to target the most sensitive parts of the code, those that pose a risk to the security of the application.
To do this, one of the most common approaches in code auditing is to analyse the ‘sources’ and ‘sinks’, as well as the paths that connect them.
- A source represents data entered into the application, typically provided by a user via a form, URL, HTTP header or the body of a request.
- A sink, on the other hand, refers to a point in the code where this data is used in a potentially dangerous way: execution of a system command, insertion into an SQL query, unescaped HTML rendering, etc.
The audit then consists of tracing the paths that data travels between its entry point and its potentially vulnerable exit point. This work makes it possible to assess whether protections are in place to validate, filter or transform this data before it is used. For example, a string of characters passed as a parameter could be cleaned to remove special characters, or encoded to prevent any unwanted interpretation.
Having access to the source code allows us to understand precisely how these filters work. We may discover that a check does not cover all cases, that a dangerous character has been overlooked, or that the filter is poorly positioned in the processing chain.
Analysis using sources
Understanding the various data sources
Direct sources correspond to values provided directly by the user when interacting with the application. They can be transmitted via the URL (path segments, query parameters), HTTP headers (such as authorisation headers, specific headers or cookies), or in the body of a request.
There are also indirect sources, which are often more difficult to identify. For example, instead of a value being transmitted directly to a component, the code may retrieve it from a database. This data may have been previously entered by the user via another feature. Another form of indirect source may occur when one server makes a request to another server and uses its response.
By having context about the source, such as where it is used and its format, it becomes possible to anticipate potential vulnerabilities related to its manipulation. For example:
- If the source is a comment field on a blog post, a Cross-Site Scripting (XSS) vulnerability is likely.
- If the source corresponds to an email generation template, a Server-Side Template Injection (SSTI) is possible.
- And if the source represents a resource identifier, an Insecure Direct Object Reference (IDOR) vulnerability may be present.
Tracking flows and usage in the source code
Once the context surrounding the source is sufficiently understood, the next step is to track all uses of that source in the code. It is important to note how the value is manipulated, transformed, or conditioned in certain contexts. It is also crucial to take into account the interactions between multiple sources. For example, one source may instruct the application to apply a transformation to another source.
Finally, some execution paths result in data being stored in a location that will be used later by another component. For example, user input may be stored in a database to be displayed on other pages. This creates a new indirect source derived from the initial source. In this case, the portions of code that retrieve this stored data become a new starting point for in-depth analysis.
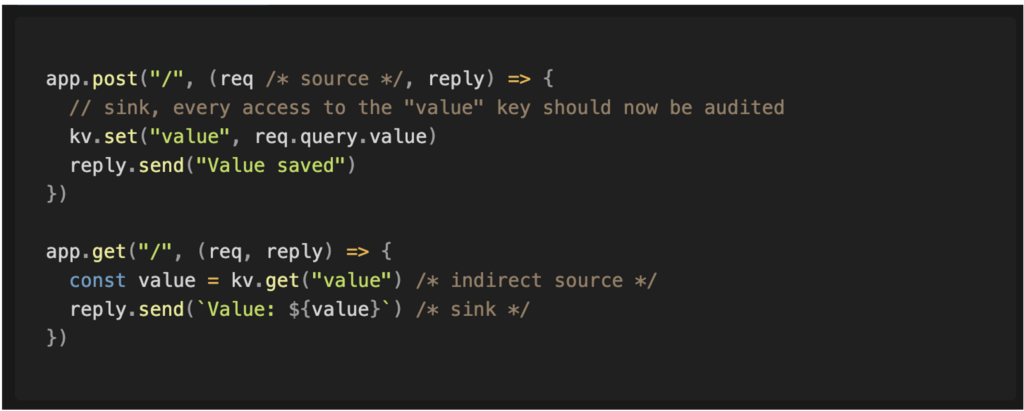
Prioritising analysis based on risk
This approach covers the entire application. It also makes it possible to identify previously unknown sinks, including potentially dangerous functions from third-party libraries.
However, this method is particularly time-consuming, as not all analysed paths necessarily lead to relevant or exploitable sinks. It is therefore necessary to accept a certain amount of fruitless exploration.
Once all paths have been identified and listed, it becomes possible to classify them according to the level of danger of the sinks reached. This step allows for prioritising analysis and corrective actions by focusing on the most sensitive areas of the code.
Analysis using sinks
This method takes the opposite approach to the previous one: the analysis no longer starts from the sources, but directly from the sinks.
The advantage is that by targeting the critical points of the code from the outset, the analysis can be interrupted as soon as an effective filter is detected, making it impossible or unlikely for the sink to be exploited.
To identify sinks present in the application, you can search the code for patterns known to be dangerous, such as the use of unprepared SQL statements or functions that execute system commands.
There are tools available to automate this detection. Semgrep, for example, can identify the use of sensitive methods. However, it relies on models created by other users, which has several limitations.
Some obvious sinks may not be detected, and conversely, the tool may generate many false alerts on harmless patterns. This phenomenon, known as alert fatigue, can lead to developers becoming weary and disengaged from security reports.
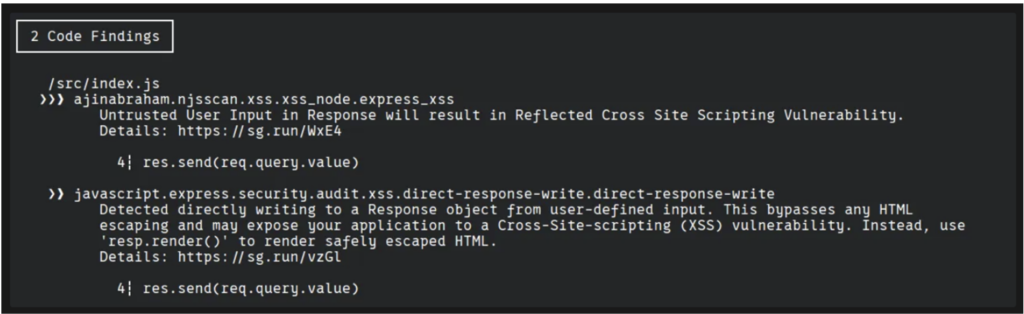
As with source-oriented analysis, a sink can be indirectly influenced by user data. If the value transmitted to a sink comes from a database, then any insertion made to that database becomes a new potential entry point, to be explored as a sink.
Which approach is better: source analysis or sink audit?
Each method has its advantages and limitations. Source-oriented analysis often generates a large number of paths to examine, but it provides better coverage of the sinks present in the application.
Conversely, the sink-oriented approach is faster and reduces the number of paths to analyse, as exploration can be stopped as soon as a filter renders the data harmless.
In practice, an effective source code audit combines both approaches in order to benefit from both the accuracy of sink-oriented analysis and the comprehensiveness of source-oriented analysis.
Reviewing Security Implementations in the Source Code
Once a path between a source and a sink has been identified, the next step is to verify that the value passes from function to function without being altered in such a way as to prevent exploitation of the sink.
Throughout this journey, the data may pass through filters or transformers. A filter may, for example, block certain characters, while a transformer may accept the value but remove elements considered invalid.
The objective is therefore to document all the transformations undergone by the data, in order to be able to construct an entry that passes through each stage of processing while retaining the ability to exploit the final sink.
Deny lists analysis
A filtering strategy based on a deny list involves blocking a value if it has certain characteristics or if it belongs to an explicit list of prohibited items.
For example, code may attempt to detect the presence of invalid characters in a string before inserting it.
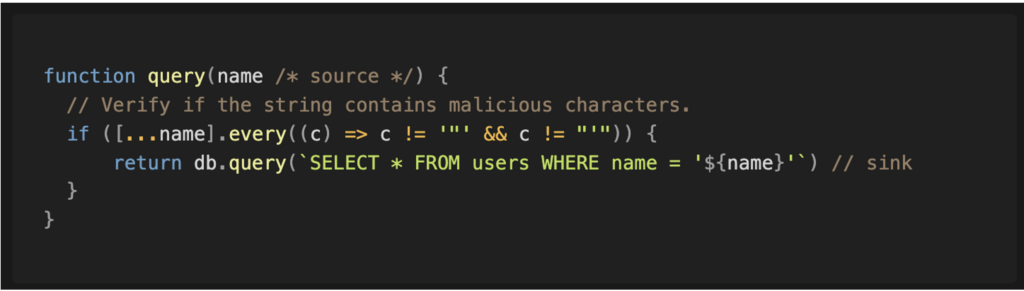
However, not all filters are created equal. A filter based on a list of prohibited values is often considered weak, as it only blocks elements that are explicitly known to be dangerous.
Some cases may have been overlooked or simply unknown, leaving significant scope for an attacker to introduce unexpected values capable of altering the behaviour of the programme.
For example, the backslash character (\) added at the end of the string can be used to escape an apostrophe. With MariaDB, if another manipulable property then intervenes in the query, this could be exploited to execute arbitrary SQL queries.
Allow lists analysis
A strategy based on a allow list is to only accept certain specific values. This type of filter is generally considered more robust, as the set of allowed values is defined in advance, making it easier to review and limiting unexpected behaviour.
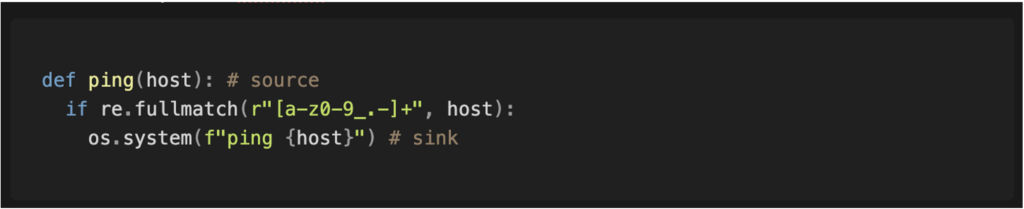
Adopting such an approach significantly enhances security by considerably reducing the possibilities for attack. For example, in the absence of an adequate filter, an attacker could inject special characters to execute subcommands and thus obtain arbitrary code execution on the targeted service.
However, even a strategy based on an authorisation list is not foolproof. In the example mentioned, the host parameter is still interpreted by the programme. The filter in place allows the use of a hyphen (-) at the beginning of a value, which can be exploited to inject additional arguments into the command and bypass the protections.
Neutralisation
Filters should be applied when the value can reach a sink capable of interpreting it in a dangerous way. However, the best solution is to avoid having dangerous sinks in the first place.
There are often safer alternatives to risky methods, ensuring that the transmitted value will not be used in a special or malicious way. Developers should prioritise the use of secure methods rather than adding filters on top of inherently dangerous methods.
For example, in the cases mentioned above, it is preferable to use prepared SQL statements rather than raw queries. In another case, it is better to use a method that does not execute the command via a shell, and, if possible, use the end-of-command option separator to avoid any unwanted interpretation.

Neutralisation therefore consists of ensuring that the value is not treated with a particular meaning that could be exploited.
Several protective measures can be put in place on the path leading to the sink. The best practice for developers is to always place the most robust countermeasures as close as possible to the sink.
For example, within the same function, it is advisable to apply filters just before calling the dangerous sink. This makes it easier to analyse the source code, as it ensures that all paths leading to the sink must pass through these filters.
On the other hand, if the filters are placed too far upstream, close to the source, there is a risk that new paths to the sink will appear without passing through these protections.
Dependency Analysis
Security alerts may be issued when a vulnerability is discovered in a library. A vulnerability is often reported when a feature that is supposed to be secure can be exploited in an unexpected way.
However, if the library is designed to provide insecure methods, it is possible that no CVE is issued for it.
It is therefore important to examine the dependencies used by the application to identify whether any of them offer dangerous methods, such as executing raw SQL queries or accessing local files. These risky methods must be included in the list of sinks to be analysed.
In some cases, countermeasures are implemented via utility functions provided by third-party libraries. For example, a file upload feature may use an external function to determine the file type.
To ensure that a filter effectively prevents a sink from being reached, it may be necessary to analyse the code of these libraries to check whether special values, not anticipated by the developers, can be exploited.
Examples of Vulnerabilities Identified During a Source Code Audit of a Web Application
In the simplest case, the source and sink are close to each other. However, most situations are more complex and involve data flowing through multiple functions and multiple files.
Mass Assignment
Mass Assignment vulnerabilities often appear in applications where users can modify their profiles.
The application then uses all the properties received and saves them to the database without checking precisely which fields have been modified.
Often, the application only checks the authorisation to modify the user themselves, which means that modifying the current user is authorised, but this does not guarantee that the modified fields are also authorised.
In some cases, this can even allow properties or related objects to be written in an undesirable manner.
When analysing the application’s source code, it is important to identify all entry points. We can start by examining the application’s router.
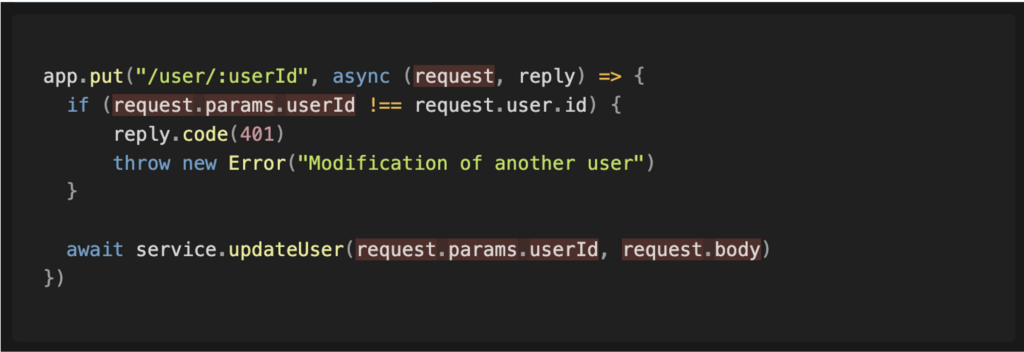
The ‘request’ parameter is the source to be analysed. In the following lines, we can see that this value is used in a comparison before being passed to a function, which allows the analysis to continue in that function.
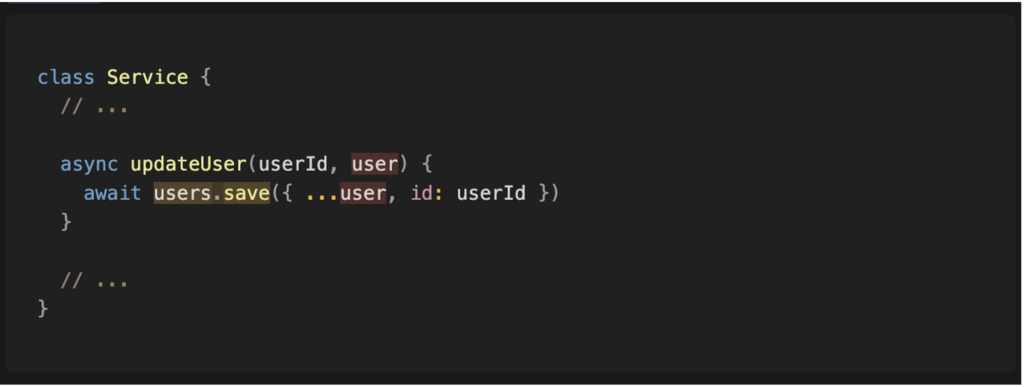
In the final function, we observe that the value controlled by the user reaches the ‘save’ method. We thus have a complete path between the source and the sink.
File Path Traversal
Sometimes developers seek to simplify the process and, instead of creating a secure indirection layer, allow users to directly specify the path of the file they wish to access.
When analysing the application’s sinks, we seek to identify all dangerous functions that could be called. For example, we can start by searching for calls to the file_get_contents function in the application code.
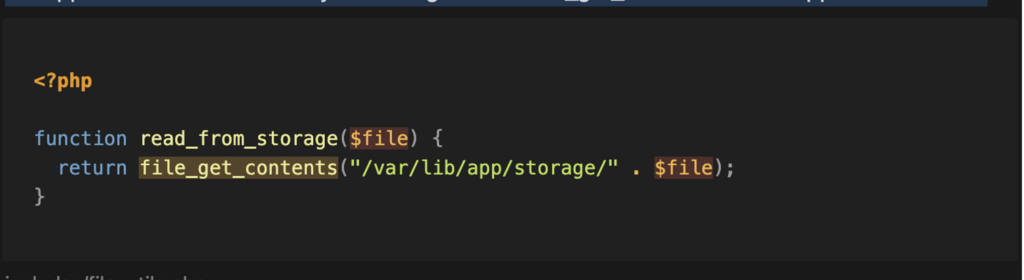
We note that this function is used in the read_from_storage function. The source of this function goes through a security measure that adds a folder to the beginning of the file path. Unfortunately, this measure is insufficient, and an attacker could exploit a path traversal vulnerability to access any file on the server.
The next steps involve treating this function as a sink and searching for all instances of its use in the application code.
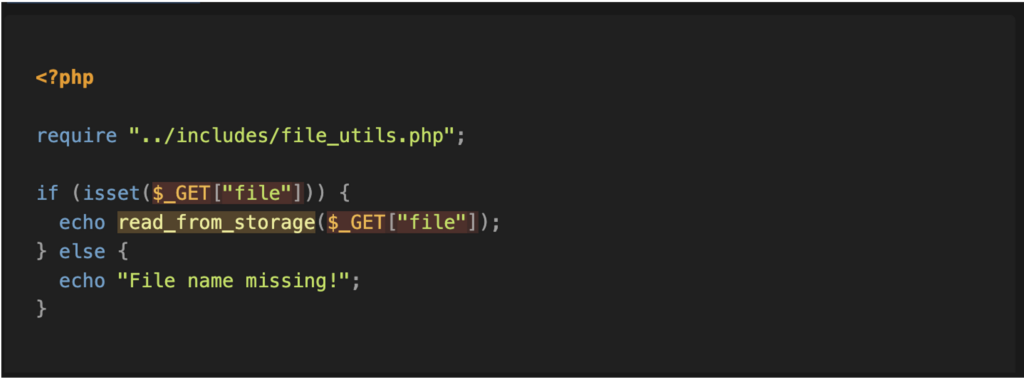
Finally, we can see that the entire chain is present: it is possible to provide the query parameter ‘file’ (source) to reach the ‘file_get_contents’ function (sink) and read the file’s contents.
Conclusion
Given that source code audits are time-limited, different strategies are used to perform a more effective analysis.
Using a source-sink strategy helps identify paths in the code that could be compromised by an attacker or the countermeasures implemented to protect a sink. This allows an auditor to focus on the most relevant lines of the application.
Although there are tools to help discover sinks, they are not yet sophisticated enough to identify all cases. However, they can be integrated into development cycles to make developers aware of patterns that could be exploited by attackers. In any case, automated tools are not yet ready to replace manual analysis.
Author: Arnaud PASCAL – Pentester @Vaadata