
During our penetration tests on web platforms, one of the main attack vectors we use most often to discover and exploit vulnerabilities is rate limiting.
Based on this principle, we believe that any web application will, sooner or later, be confronted with a traffic-generating attack. These can take several forms, but the main ones are the following:
All these attacks can be mitigated by implementing an essential process that limits the amount of requests a client can send to the server: rate limiting.
Rate limiting can take several forms, which we will discuss in more detail. But before that, we present some concrete examples of brute force attacks that allowed the discovery and exploitation of critical vulnerabilities thanks to the lack of rate limiting.
During a web application penetration test, we observed that like on most platforms there was a password reset feature. Here, when a user made a reset request, a temporary 6-digit password was generated and emailed to them.
Login : kevin@plateforme.test
Mot de passe : 558573
Login : kevin@plateforme.test
Mot de passe : 922145
Login : kevin@plateforme.test
Mot de passe : 498144 As you can see, each generated password consisted of a random number of 6 digits. Testing all the possibilities of a 6-digit list seems feasible if the web application doesn’t limit us, and that was the case here. Indeed, the server had no rate limiting protection, which means that nothing blocked a user’s login attempts.
We were able to test all the possibilities until we found the temporary password. The impact of this attack is quite critical as an attacker can take control of any account on the platform by knowing the victim’s email (which is not very difficult to find via a little recon).
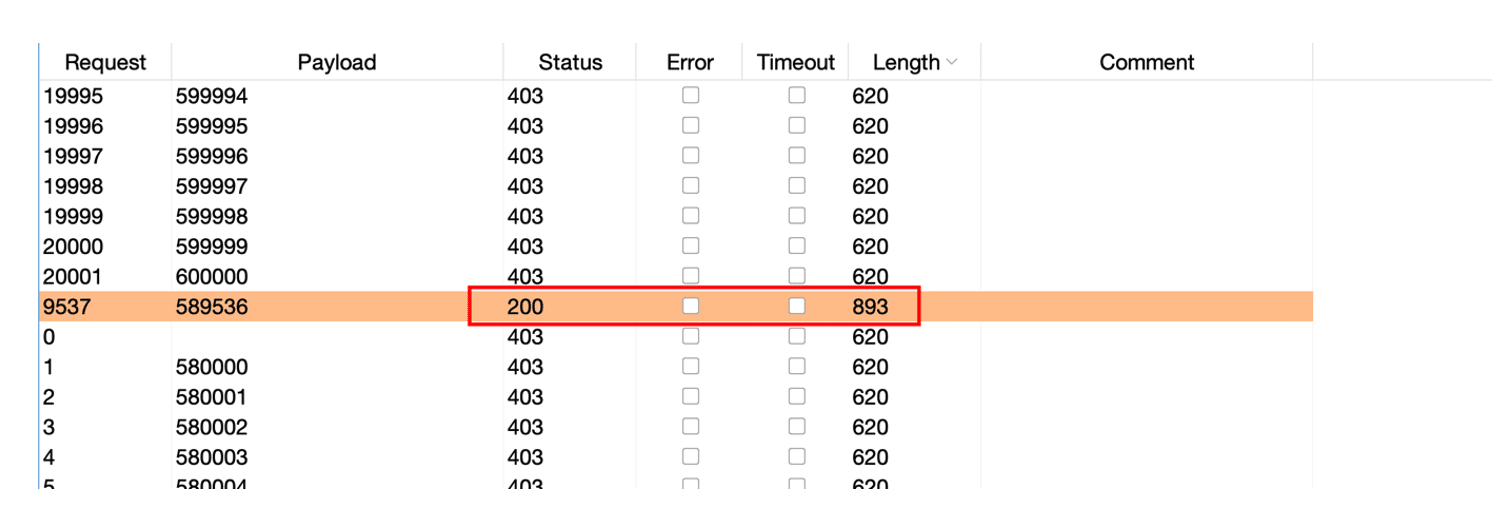
It is very easy to exploit a lack of rate limiting to, for example, brute force a password via a login form. All the attacker has to do is to try out one by one the passwords that they have previously compiled and/or generated in a file.
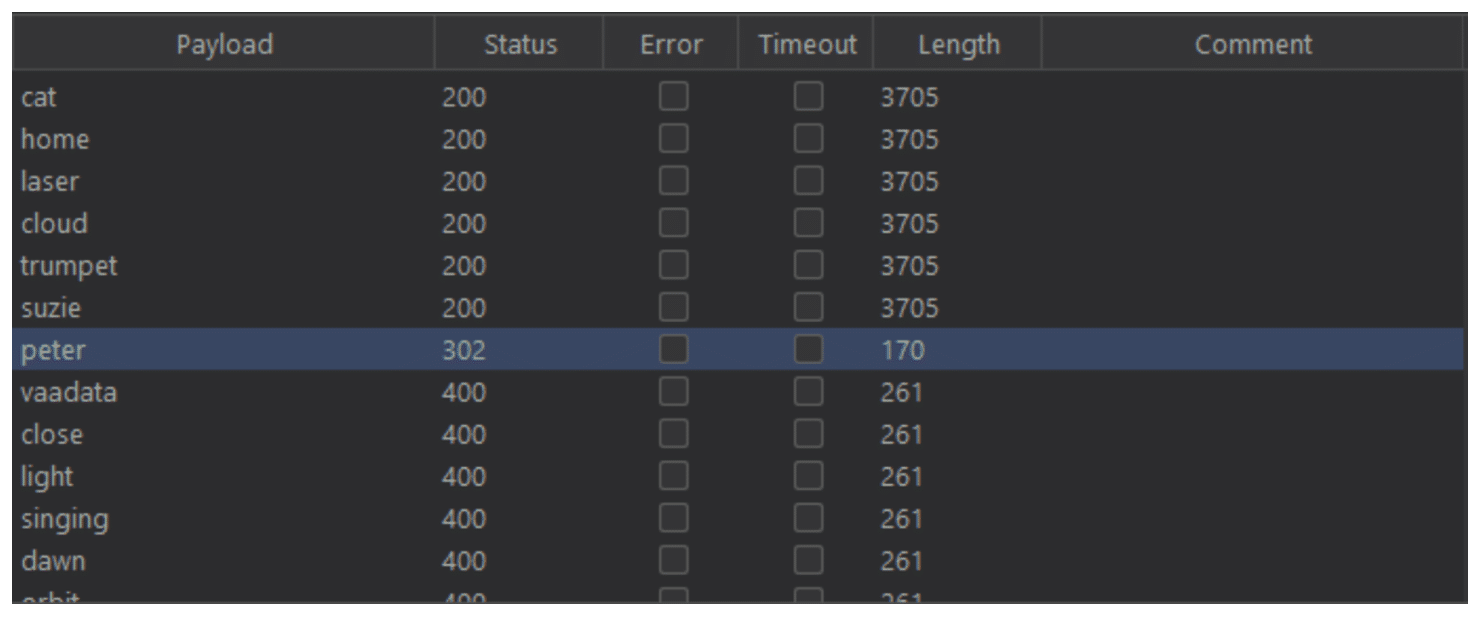
In the example above, we can see that the server responds differently when we send a login request with “peter” as the password. The password is valid and we are now logged in with an account that does not belong to us.
The same tactic applies to a 2FA (2-factor authentication) process that requires, for example, a 4-digit code sent by SMS. If there is a lack of rate limiting, simply try all possible combinations to get a good guess.
This limitation is usually at the level of the server (or the proxy that receives the requests in the first place, if applicable) and consists of simply dropping requests from IPs that generate too many requests.
This limit is usually high, several dozen requests per second, and is mainly there to counter mass denial of service attacks. It is vital for any platform and is usually included in modern hosting packages.
But it is unfortunately insufficient to counter more targeted attacks. For that, we need…
This limitation consists in reducing more drastically the requests received and processed on certain endpoints. It must be implemented at the application level, generally via middleware, and makes it possible to target and modulate throughput limitations much more precisely on a case-by-case basis, by authorising, for example, only 5 connection attempts, or by prohibiting several calls to a resource-intensive function until the previous operations have been completed.
The client can be identified by its IP, as for the global rate limiting, but can also be identified by its session token, once logged in, if the protected endpoints are accessible only by a logged-in user of course.
In the case of resource-intensive endpoints, it is also possible to set up a queue to ensure that requests are processed sequentially and not in parallel (or only a certain number). In this case, it is of course also necessary to ensure that one user cannot completely fill the queue on their own.
During a penetration test, we encountered a feature that allowed us to generate a PDF from JSON data. Running the generation of many PDFs simultaneously completely saturated the server memory and made the service unavailable. In this case, a queue can be set up.
However, there is a problematic case: what if the user’s behaviour is suspicious but potentially “normal”? For example, in the case where 5 unsuccessful login attempts have been made, is it just a user having forgotten their password or a malicious actor trying to steal an account? What should be done?
The vast majority of attacks mitigated by rate limiting will be carried out by bots. No attacker will manually attempt to guess the 1,000,000 passwords they have identified as plausible to try to steal an account: they will delegate the task to a machine.
But machines have a weakness: they have great difficulty recognising patterns in “chaotic” images, which is exactly what a CAPTCHA (Completely Automated Public Turing test to tell Computers and Humans Apart) requires: a small form that blocks the request from being sent until the client recognises the pattern in question, which could be a sequence of letters and numbers, an open circle among closed circles, signs, a type of vehicle, etc.
Below is an example of a CAPTCHA:

If you have found the open circle, congratulations, you are human!
Some more advanced CAPTCHAs study the user’s behaviour (mouse movement, typing speed…) to make sure they are human: no need for pictures or puzzles.
CAPTCHAs can be implemented on features that need to be severely regulated (login, forgotten password, very resource-intensive function…) but that it is not excluded that a user can call several times in a relatively short time.
However, one question remains: what frequency is allowed for each endpoint? Globally?
There is no easy answer: it will depend on your application and the use your users will make of it. Each sensitive endpoint must be studied individually to define what frequency is acceptable.
Adjusting rate limiting is a constant process, which needs to be fed by your analytics, customer feedback and your logging and monitoring system to ensure that attacks are blocked while not infringing on your users’ experience and legitimate use of the platform.


